
https://medium.com/@cbarkinozer/starcoder2-makale-i%CC%87ncelemesi-12fd8bbfac51
A summary of the article "StarCoder 2 and The Stack v2: The Next Generation".

Abstract
The BigCode project1, an open-scientific collaboration focusing on the ethical creation of Large Language Models for Code (Code LLMs), introduces StarCoder2. In collaboration with Software Heritage (SWH),2 we built The Stack v2 on the digital commons of their source code collection. Along with the SWH repositories, which cover 619 programming languages, we carefully choose other high-quality data sources such as GitHub pull requests, Kaggle notebooks, and code documentation. This creates a training set that is four times larger than the initial StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens before extensively evaluating them against a complete range of Code LLM benchmarks.
We discovered that our tiny model, StarCoder2-3B, outperforms StarCoderBase-15B. Our larger model, StarCoder2-15B, matches or beats CodeLlama-34B. Although DeepSeekCoder-33B is the best-performing model for code completion in high-resource languages, we discovered that StarCoder2-15B surpasses it in math and code reasoning benchmarks, as well as some low-resource languages.
1. Introduction
As of January 30, 2024, GitHub CoPilot had over 1.3 million paying subscribers, with over 50,000 organisations opting for the enterprise version (MSFT Q2 Earning Call, 2024), which is expected to increase developer productivity by up to 56% while also increasing developer satisfaction (Peng et al., 2023; Ziegler et al., 2024). ServiceNow recently announced that their "text-to-code" solution, based on fine-tuning StarCoderBase models (Li et al., 2023), resulted in a 52% boost in developer productivity (Yahoo Finance, 2024).
The Stack v2 dataset relies on Software Heritage's huge source code archive, which includes over 600 programming languages. In addition to code repositories, we curate other high-quality open data sources, such as Github issues, pull requests, Kaggle and Jupyter notebooks, code documentation, and other natural language datasets about math, coding, and reasoning. To prepare the data for training, we deduplicate it, implement filters to remove low-quality code, redact Personally Identifiable Information (PII), remove malicious code, and handle opt-out requests from developers who want their code removed from the dataset.
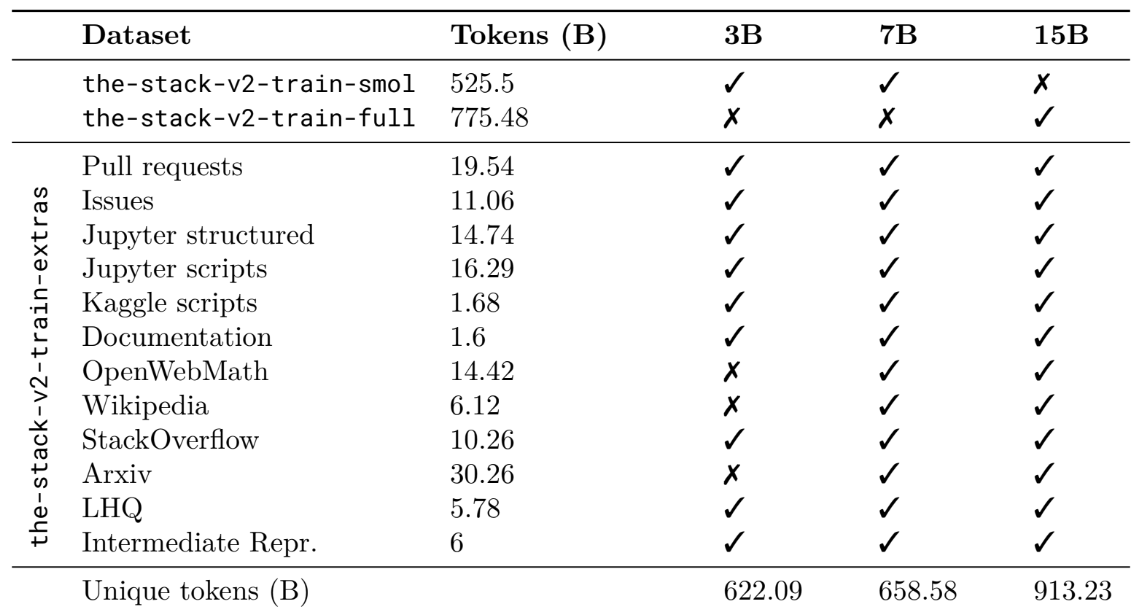
We developed the latest generation of StarCoder models using a new training set of over 900 billion unique tokens, which is four times larger than the original dataset. We trained Code LLMs with 3B, 7B, and 15B parameters in two stages (Rozière et al., 2023; Guo et al., 2024). We begin basic model training with a 4k context window and then fine-tune the model using a 16k context window. We ensure that the training process does not exceed 5 epochs over the dataset (Muennighoff et al., 2023).
We train tiny models with 3.3 to 4.3 trillion tokens, above the compute-optimal number recommended by Chinchilla (Harm's law; de Vries, 2023).
2. Data Sources
In this section, we go over the process of gathering training data, which includes not only data from Software Heritage but also GitHub issues, pull requests, Jupyter and Kaggle notebooks, documentation, intermediate representations, small math and coding datasets, and other natural language datasets. The latest commit on the master/main branch is used to extract data.
Language Detection
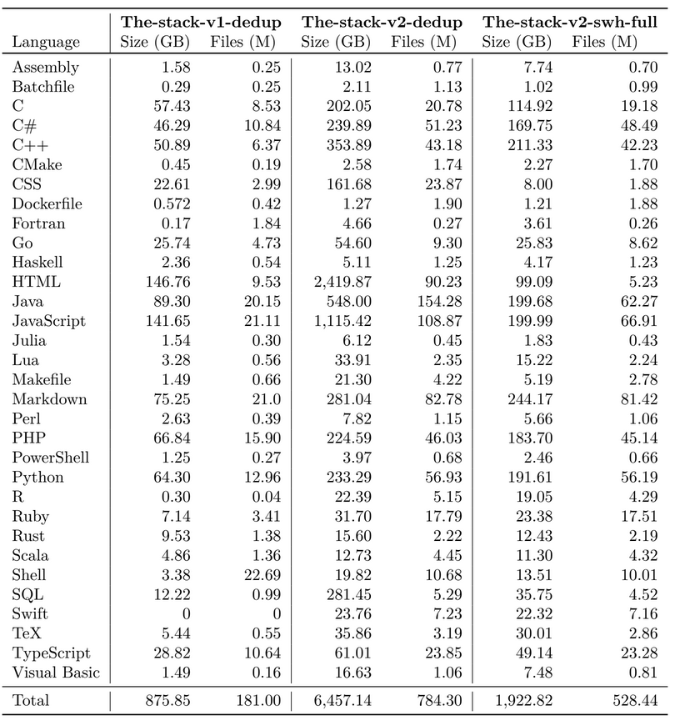
In StackV1, programming languages are identified by their file extensions. This time we use a language classifier. To determine the programming language for each file, we utilize go-enry, which is based on GitHub's library linguist (go-enry, 2024). TheStackV2-dedup identifies 658 distinct languages, which are partially deleted during data inspection.
The code base size grew 2-10 times depending on the language (java 7x, Python 4x, C# 6x, C++ 7x, Javascript 10x, Dockerfile 2x, Batchfile 10x, Markdown 4x, Powershell 2x, and SQL 20x). Swift previously did not exist due to an error, but it has now been added. The total data size went from 875 GB to 6457 GB.
I'm skipping the preprocessing section because it's largely the same as in StarCoder1.
4. Data filtering
Autogenerated files, data files, and any other low-quality training data are eliminated.
Long-line filter: Removes files with a size of more than 100,000. We also eliminate files having an average line length of more than 100 characters or a maximum line length of more than 1000 characters in all languages, with the exception of non-code files.
Autogenerated filter: Go-enry's is_generated() method detects and removes autogenerated code.Alpha filter: We eliminate files that contain less than 25% alphabetic characters in all languages.
Language-specific filters:
- We only keep Text files with "requirement" in the lowercased filename, or if the filename without the extension is one of {"readme", "notes", "todo", "description", "cmakelists"}.
- Text, JSON, YAML, Web Ontology Language, and Graphviz (DOT) files with more than 512 lines are removed to reduce the impact of repetitive tokens in data files.
- We maintain only HTML files with visible content that is at least 100 characters long and accounts for at least 20% of the code, similar to StarCoder's processing pipeline.
To improve the model's grasp of low-resource programming languages, we combine source code and its intermediate representations (IR). The main reason for this approach is that a shared intermediate representation could assist tie low-resource constructs to analogous ones in high-resource languages.
Other Non-English Natural Language Datasources
Documentations for programming languages, as well as 3,541 free programming books in various languages such as English, Chinese, Japanese, Spanish, and others, are included.Furthermore, English is the most common natural language in source code and other datasets, however other languages are utilized as well. As a result, the model can create code snippets with some non-English context, but the resulting code is not guaranteed to perform as intended or equally well in all languages. We remove files from the basic commit that contain non-English language in Markdown.
LHQ (Leandro’s High-Quality dataset)
We have included many tiny high-quality datasets for math and coding:
- APPS (train) (Hendrycks et al., 2021) is a popular Python text-to-code benchmark with a train set of 5,000 instances. We include one solution for each programming task.
- Code Contest (Li et al., 2022) is similar to APPS but includes solutions in a variety of programming languages, including Python 2/3, C++, and Java. We include one answer per problem and language, yielding a dataset of 13k+ samples.
- GSM8K (train) (Cobbe et al., 2021) is the train split of GSM8K, a popular evaluation benchmark for assessing LLMs' math reasoning abilities. The dataset consists of around 7,000 instances.
- GSM8K (SciRel) (Yuan et al., 2023) is an enhanced version of GSM8K that offers alternate reasoning paths for the questions in GSM8K. The enhanced version includes 110k samples.
- Deepmind Mathematics (Saxton et al., 2019) is a synthetic dataset of math questions and answers spanning several domains (algebra, arithmetic, calculus, comparison, measurement, numbers, polynomials, probability) and difficulty levels (easy-medium-hard). The dataset consists of almost 110 million (brief) instances.
- Rosetta Code (Rosetta Code, 2023; Nanz & Furia, 2015) is a collection including over 1100 common programming jobs and solutions in as many programming languages as possible.
- MultiPL-T (Cassano et al., 2023a) generates high-quality data in Lua, Racket, and OCaml by automatically translating extracted Python functions and validating them using unit tests. The complete dataset contains about 200k samples.
- Proofsteps is part of the AlgebraicStack dataset (Azerbayev et al., 2024), which is used to train the Lemma family of models. We also offer proofsteps-lean, which was taken from mathlib 4 (mathlib Community, 2020), and proofsteps-isabelle, which was produced using the PISA dataset (Jiang et al., 2021). Proofsteps-lean has about 3000 examples, but proofsteps-isabelle has over 250k examples.
Other Natural Language Datasets
- StackOverflow We have included 11 million questions and their related multiple responses from the Stack Overflow dump dated September 14, 2023. We excluded queries with fewer than three replies.
- ArXiv We use the ArXiv subset of the RedPajama dataset. This dataset was obtained from a publicly available Amazon S3 bucket (Arxiv, 2024). We further processed the dataset by retaining only latex source files and removing preambles, comments, macros, and bibliographies. The total dataset contains approximately 30B tokens.
- Wikipedia We include Wikipedia's English subset. We specifically use the version gathered by RedPajama (RedPajama Wiki, 2024), which is based on the dump from March 20, 2023. We follow RedPajama's processing processes to remove linkages and templates from Wikipedia entries. The complete dataset contains approximately 6 billion tokens.
- OpenWebMath We include OpenWebMath (Paster et al., 2023), a publicly available dataset of high-quality mathematical language collected from CommonCrawl. The complete dataset contains over 15 billion tokens.
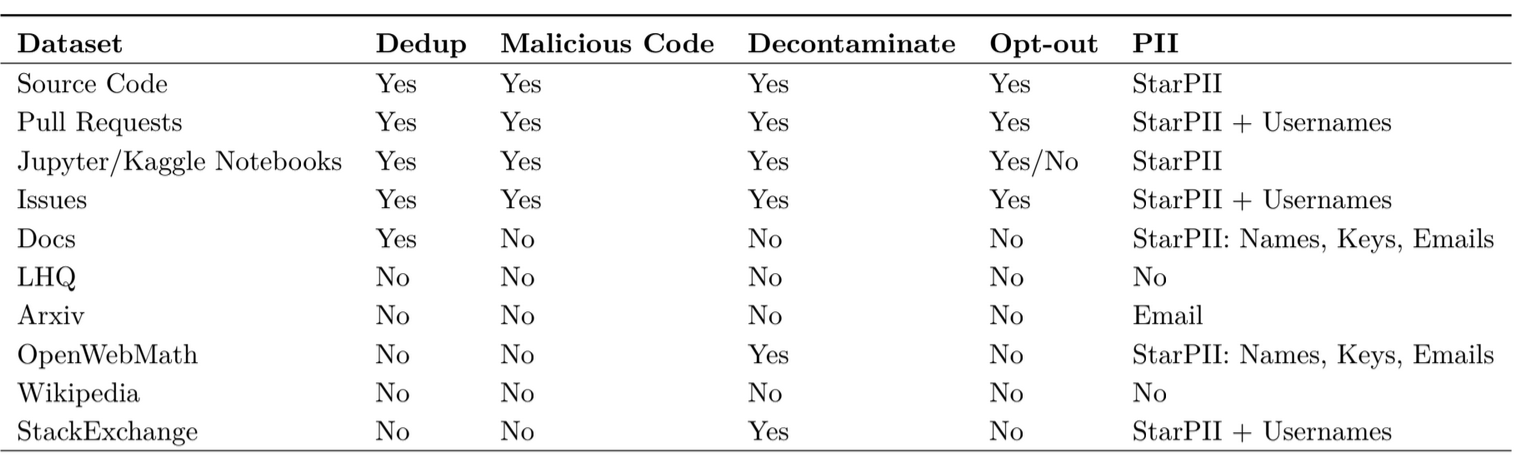
The 15B model alone speaks 619 languages, while the 3B and 7B versions speak 17 of the most common languages. 3B's English grammar may also be poorer because they did not include some natural language resources.

5. Data Formatting
We add the repository name and file paths to the context of the code file. We only add this metadata with a 50% chance of allowing the model to work without it. We use the following format for adding the repository name and file paths:
<repo_name>reponame<file_sep>filepath1\ncode1<file_sep>filepath2\ncode2 ... <|endoftext|>.When this meta-data is not included, we use the format shown below:
<file_sep>code1<file_sep>code2 ... <|endoftext|>.
6. Model Architecture and Training Details
In this section, we present information about the model architecture, tokenizer, training details, and CO2 emissions during training.
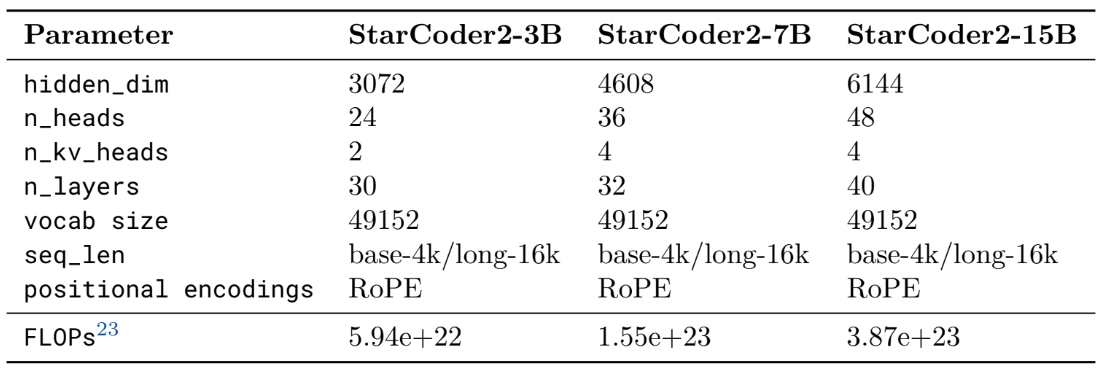
We make a few architectural changes compared to StarCoderBase. To improve performance, we replaced learnt positional embeddings with Rotary Positional Encodings (RoPE; Su et al., 2021) after a pilot ablation research revealed considerable results. Following DeepseekCoder (Guo et al., 2024) and Code LLaMA (Rozière et al., 2023), we employ a base period of θ = 1e5. The second architectural change involves replacing Multi-Query Attention (MQA; Shazeer, 2019) with Grouped Query Attention (Ainslie et al., 2023, GQA). To avoid slowing down inference, we limit the number of key-value heads to two for the 3B, four for the 7B, and 15B.

Tokenizer
We use the StarCoderBase technique to train a byte-level Byte-Pair-Encoding tokenizer on a tiny part of The Stack v1.24. In our preliminary studies, we found that raising the vocabulary size to 100,000 did not increase performance. As a result, we opted to keep a vocabulary size of 49,152 tokens, including the sentinel tokens from Table 5. The pre-tokenization process contains the GPT-2 pre-tokenizer's digit-splitter and regex splitter.
Training Details
Basic models The models were trained using a 4,096 sequence length using Adam (Kingma & Ba, 2015) with β1 = 0.9, β2 = 0.95, ε = 10−8, and a weight decay of 0.1, with no dropouts. After 1,000 cycles of linear warmup, the learning rate decayed as a cosine function. Table 7 shows the training hyperparameters for each model. The RoPE θ values for StarCoder2-15B differ due to a problem in training configuration parsing.
Furthermore, StarCoder2-15B was supposed to train for 1.1 million iterations but was stopped prematurely after 1 million. Following Muennighoff et al. (2023), we repeat data for four to five epochs.
Long context. We then pre-trained each model for long-context on 200 billion tokens from the same pretraining corpus, using a 16,384 context length, a sliding window of 4,096, and FlashAttention-2 (Dao et al., 2022; Dao, 2024). We boost RoPE θ while maintaining the same optimizer settings. The remaining training hyperparameters are included in Table 8.
7. Evaluation
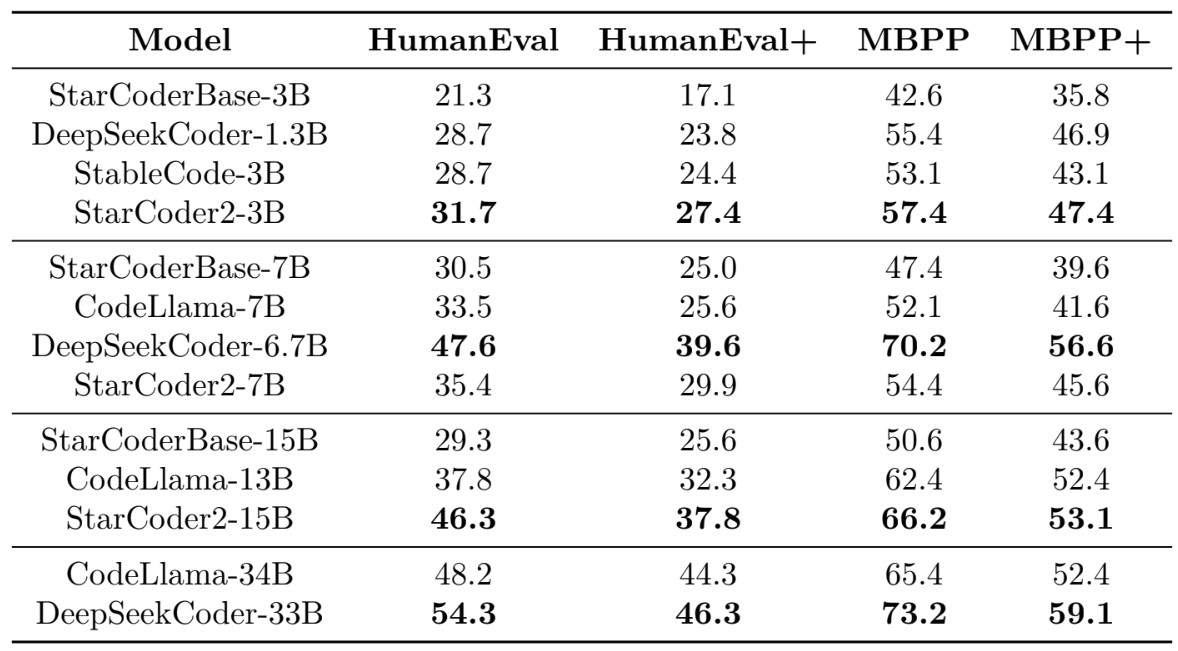
We assess the StarCoder2 models on a number of literature benchmarks and compare them to recent cutting-edge open Code LLMs: StableCode (Pinnaparaju et al., 2024), Code Llama (Rozière et al., 2023), DeepSeekCoder (Guo et al., 2024), and the original StarCoder (Li et al., 2023). Because StarCoder2 is a base model, we only compare it to the base models from the model families indicated above.
Code Completion
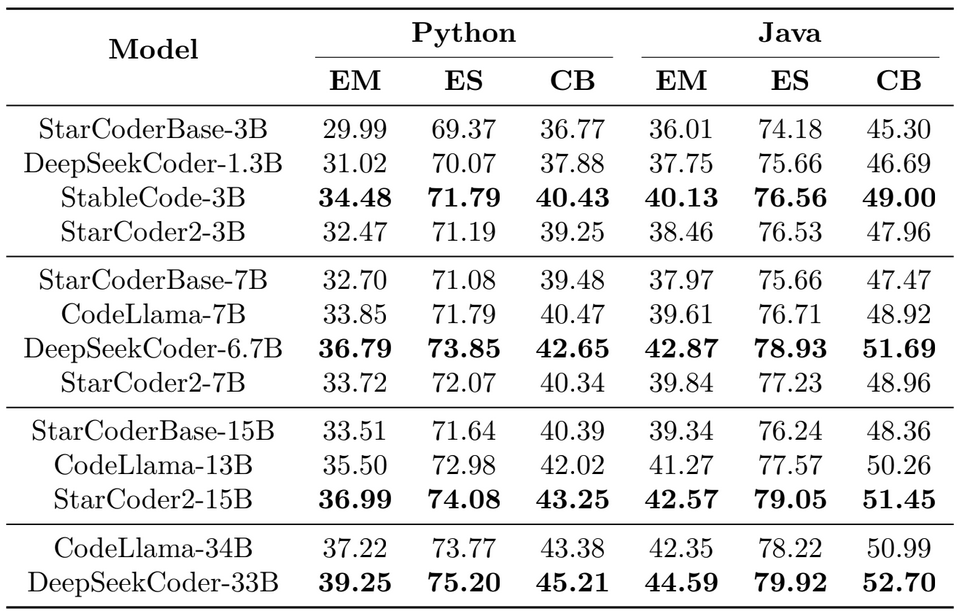
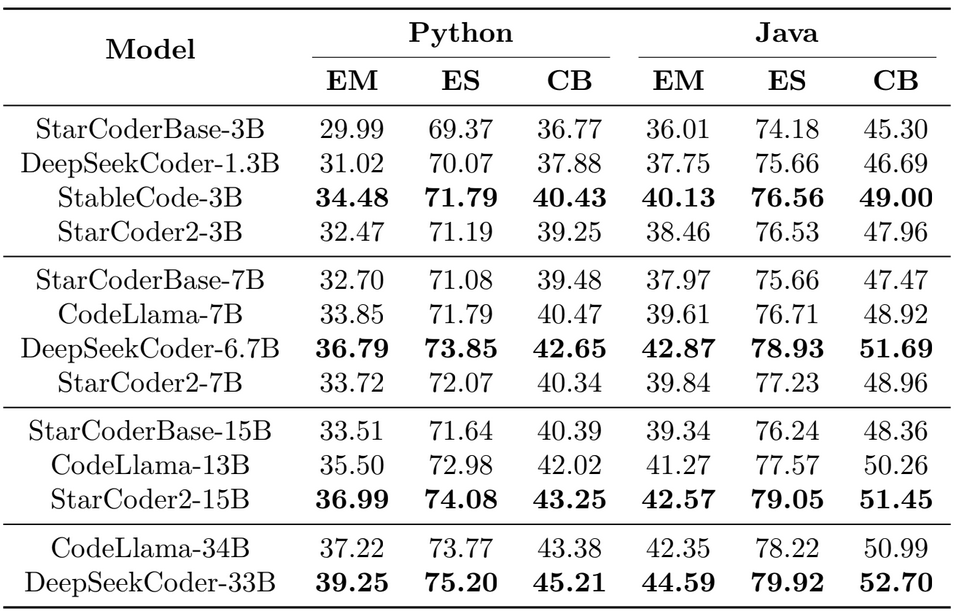
- StarCoder2-3B is the top-performing small model across all datasets (HumanEval, MBPP, Hu-manEval+, and MBPP+). The model performs much better than its predecessor, StarCoderBase-3B, with improvements of 60.2% on HumanEval+ and 32.4% on MBPP+.
- StarCoder2-7B comes in second place among midsize models. DeepSeekCoder-6.7B is more powerful, outperforming StarCoder2-7B by 32.4% and 24.1% on HumanEval+ and MBPP+, respectively. However, StarCoder2-7B routinely surpasses all medium models, including StarCoderBase-7B and CodeLlama-7B. StarCoder2-7B outperforms StarCoderBase-7B by 19.6% and 15.2% in HumanEval+ and MBPP+, respectively. Additionally, it outperforms CodeLlama-7B by 16.8% and 9.6% in these benchmarks.
- StarCoder2-15B is the best-performing large model by a wide margin. On HumanEval, it scores 46.3, whereas CodeLlama-13B scores 37.8. The results from EvalPlus are likewise consistent. For example, in HumanEval+, it outperforms StarCoderBase-15B and CodeLlama-13B by 47.7% and 17.0%, respectively.
MultiPL-E: Multilingual Code Completion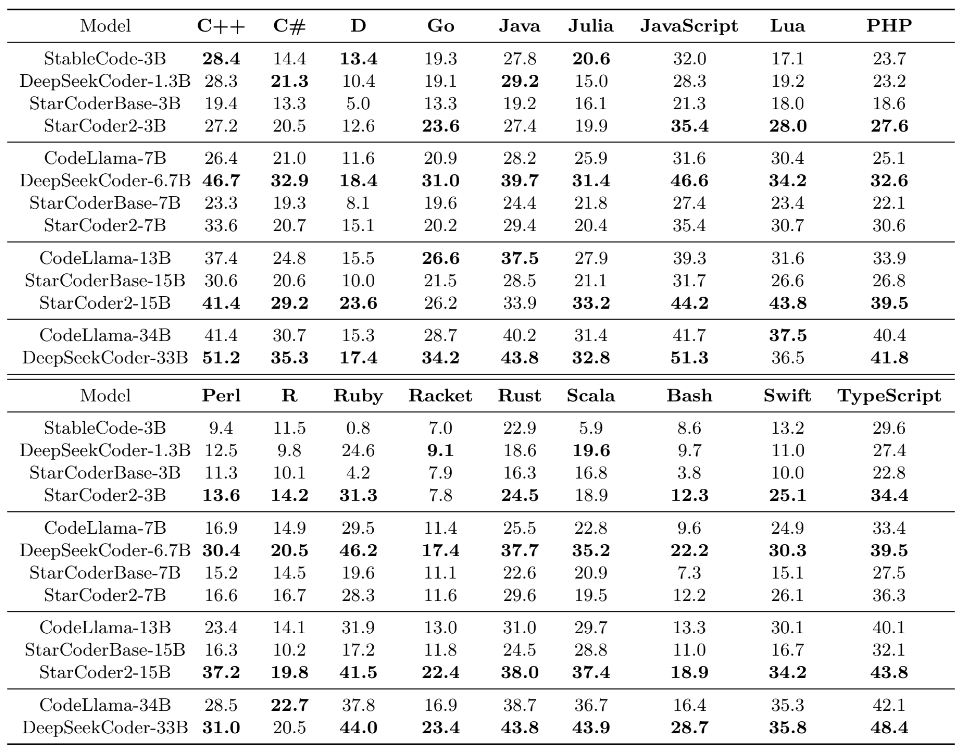 Pass@1 results on MultiPL-E were averaged across 50 samples for each problem. All models are evaluated at temperature 0.2 and top-p of 0.95.
Pass@1 results on MultiPL-E were averaged across 50 samples for each problem. All models are evaluated at temperature 0.2 and top-p of 0.95.
Across all size classes, no single model is superior in every language. Nonetheless, the StarCoder2 models work effectively, as described below. StarCoder2-3B outperforms the other tiny models in 11 of 18 programming languages. DeepSeekCoder-6.7B outperforms other medium models. StarCoder2-7B outperforms CodeLlama-7B in most languages. StarCoder2-15B outperforms other large models in 16/18 programming languages. CodeLlama-13B outperforms StarCoder2-15B in both Go and Java. StarCoder2-15B performs similarly to or better than CodeLlama-34B on 10/18 programming languages and DeepSeekCoder-33B on four lower-resource languages.
DS-1000: Data Science Tasks in Python
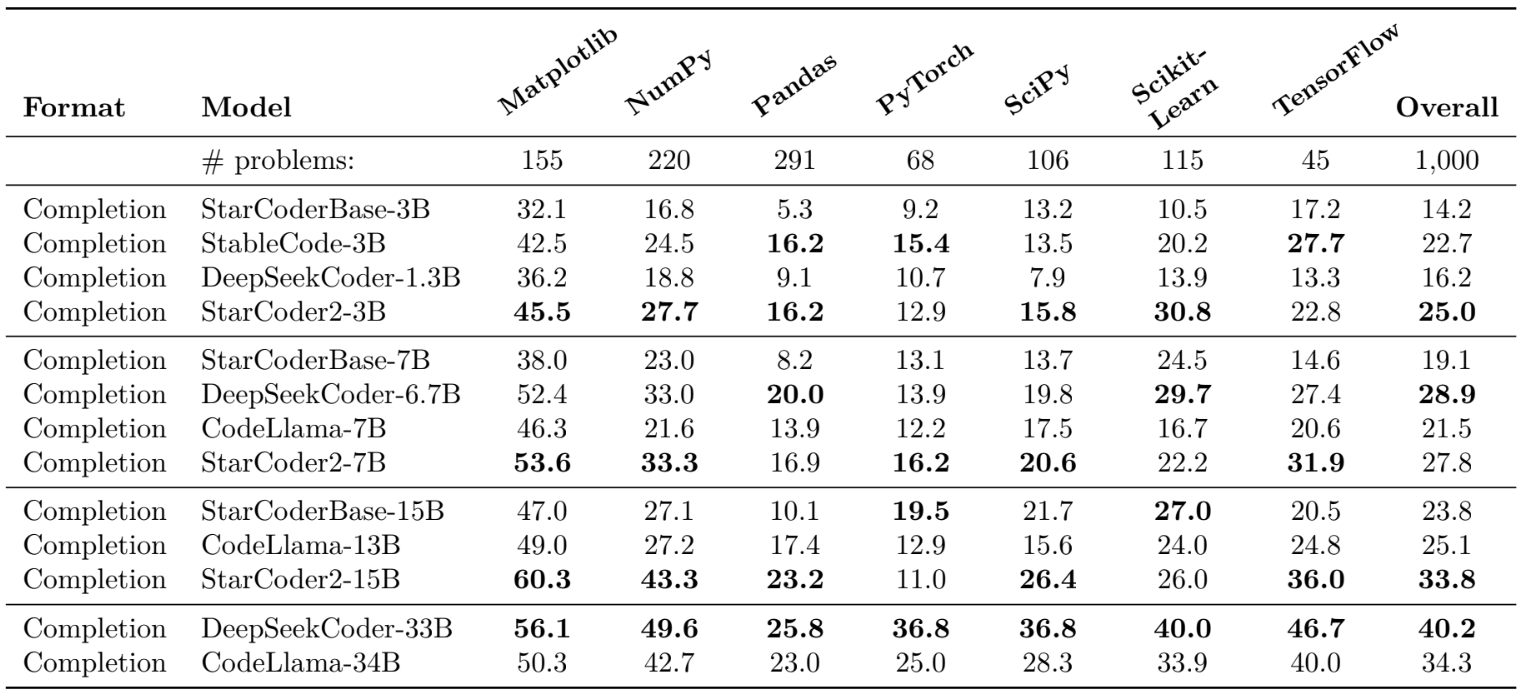
StarCoder2-7B ranks in second place among medium models, with performance comparable to DeepSeekCoder-6.7B.
StarCoder2-15B is the best-performing big model on the DS-1000. It exceeds both StarCoderBase-15B and CodeLlama-13B by a significant margin and is on par with CodeLlama-34B in total performance.
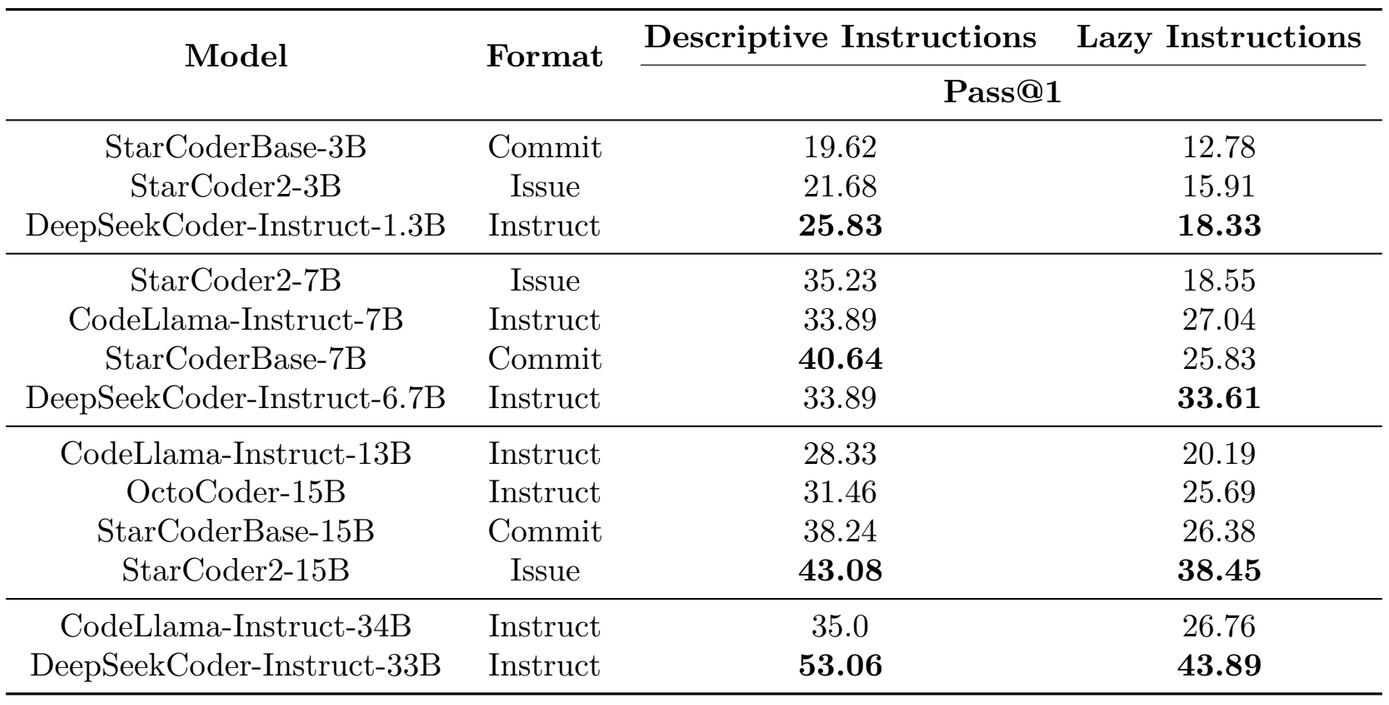
Code Fixing and Editing
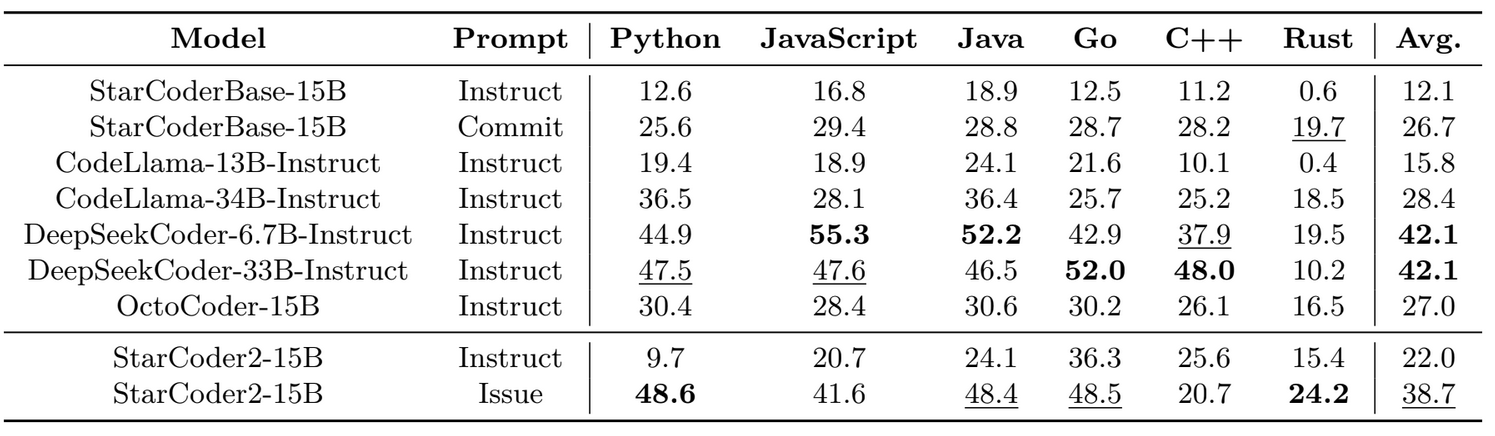
- When given an instruction prompt, the base models (StarCoder2-15B and StarCoderBase-15B) perform extremely poorly, highlighting the need for a better prompt structure.
- Using the Issue prompt mentioned above, StarCoder2-15B operates admirably as a basic model. It outperforms instruction-tuned CodeLlama models and roughly matches DeepSeekCoder models.
- Using the Issue prompt for StarCoder2-15B improves performance more than the Commit prompt for StarCoderBase-15B. This means that pre-training on pull requests (StarCoder2) is a viable alternative to pre-training on commits (StarCoderBase). Using the Issue prompt, StarCoder2-15B outperforms all of the open models offered by Muennighoff et al. (2024a).
- StarCoder2-15B performs poorly in C++ while using the Issue prompt, which degrades its overall speed. Our analysis reveals that this is primarily due to one-third of the code generated being unfinished, such as having an unexpected break just after the start of a for loop. Additional prompt engineering may be required to resolve this. Thus, we continue to see value in instruction tuning StarCoder2 to increase its usability in handling comparable cases more successfully without prompt engineering. We leave instruction tailoring and even preference alignment (Christiano et al., 2017; Ethayarajh et al., 2024) to future work with StarCoder2.
Code Editing
Math Reasoning
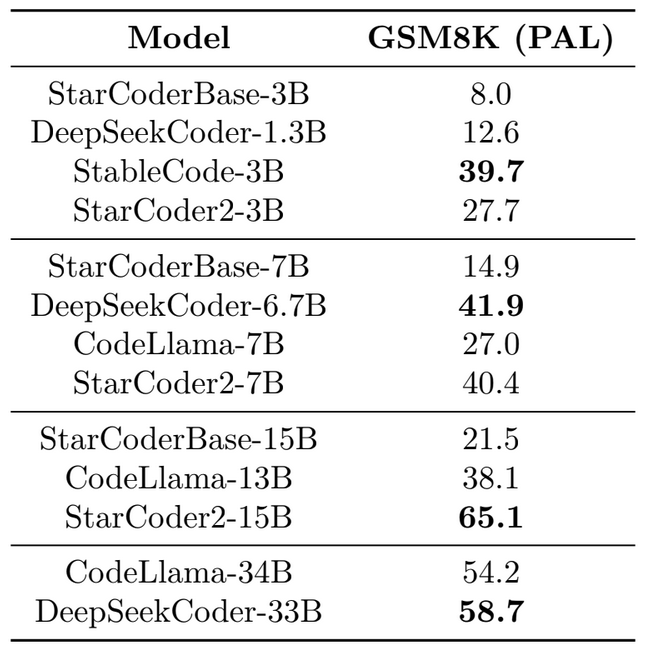
- StableCode-3B is the top-performing compact model. StarCoder2-3B is ranked second.
- StarCoder2-7B takes second place. It performs similarly to the first-place model, DeepSeekCoder-6.7B, while significantly outperforming CodeLlama-7B and StarCoderBase-7B.
- StarCoder2-15B performs substantially better than all large models, including CodeLlama-13B and StarCoderBase-15B.
- In fact, StarCoder2-15B surpasses CodeLlama-34B and DeepSeekCoder-33B, which are more than twice the size.
CRUXEval: Code Reasoning, Understanding, and Execution
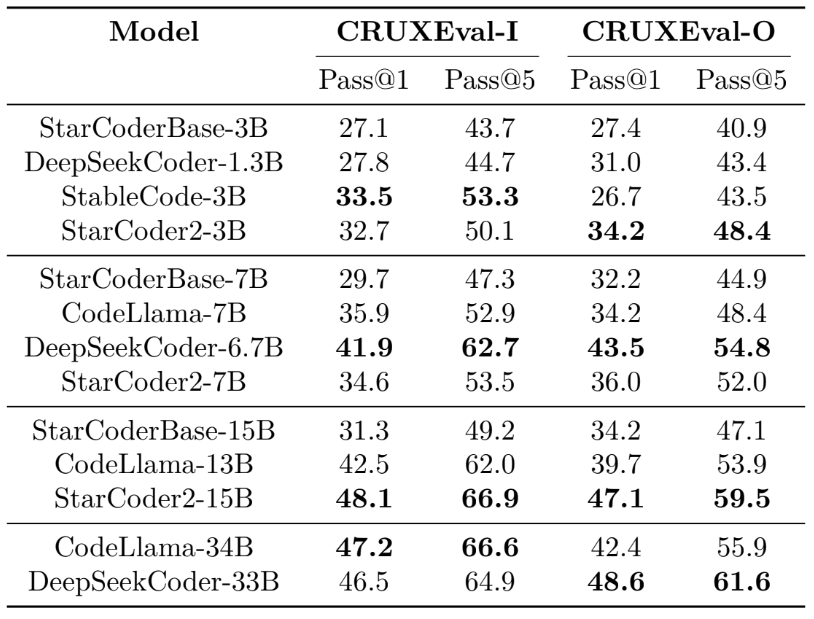
- StarCoder2-3B is competitive with other compact models. It slightly underperforms StableCode-3B on CRUXEval-I (within the noise margin of error), but outperforms all other tiny models on CRUXEval-O.
- For both tasks, StarCoder2-7B performs similarly to CodeLlama-7B but falls much behind DeepSeekCoder-6.7B.
- StarCoder2-15B is the top-performing big model. It outperforms CodeLlama-13B and StarCoderBase-15B on both CRUXEval-I and CRUXEval-O.
- StarCoder2-15B performs similarly to the extra-large variants. On CRUXEval-I, it outperforms both CodeLlama-34B and DeepSeekCoder-33B within a standard deviation. On CRUXEval-O, it greatly outperforms CodeLlama-34B while somewhat underperforming DeepSeekCoder-33B.
Fill-in-the-Middle
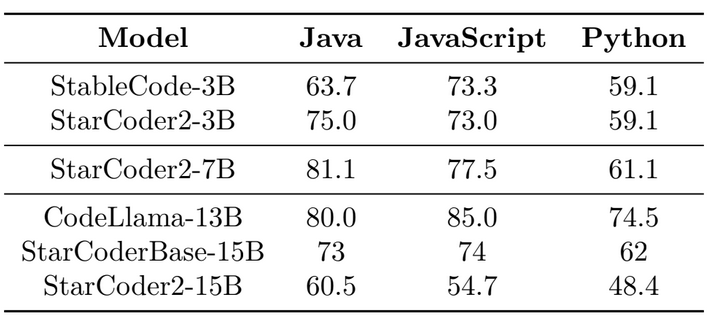
Repository-Level Code Completion Evaluation
- StarCoder2, with repository-level training, consistently outperforms StarCoderBase across all tested model sizes.
- StarCoder2-3B outperforms the smaller variants, ranking second to StableCode-3B.
- StarCoder2-7B performs competitively, closely matching CodeLlama-7B among medium models, with DeepSeekCoder-6.7B outperforming the competition.
- StarCoder2-15B not only outperforms CodeLlama-13B, but it also performs comparably, if not better, than the much bigger CodeLlama-34B model.
“Asleep at the Keyboard” Security Benchmark
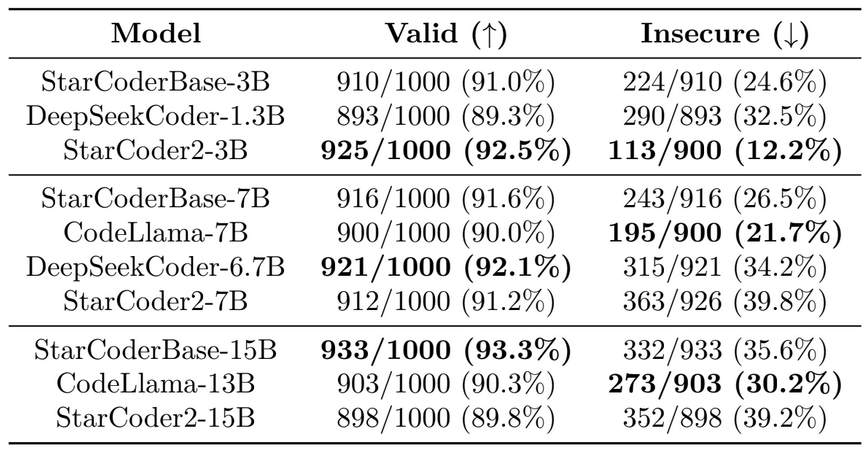
- StarCoder2 produces a comparable amount of valid programs as StarCoderBase, CodeLlama, and DeepSeekCoder. Both the StarCoderBase and StarCoder2 models achieve over 90% valid program rates. However, after some careful inspection, we discovered that StarCoder2 produces more functionally accurate code than StarCoderBase. The observation is consistent with the evaluations in the previous sections.
- Except for StarCoder2-3B, StarCoder2-7B and StarCoder2-15B have the greatest unsecure program rate among models with comparable specifications. The increased insecurity rate could be attributed to the higher rate of valid and functionally correct completions. These created programs are more likely to be vulnerable, according to Bhatt et al. (2023). Li et al. (2023) discovered that the initial model utilized in commercialized Copilot, code-cushman-001, has an unsecure rate of above 40%.
Harmful Generations
Tables 20–23 (see paper for tables) show the results for BOLD, WinoBias, HONEST, and RealToxicityPrompts. The tables indicate that our models' LLMs produce nearly the same amount of harmful content, and according to Li et al. (2023), LLMs trained largely on code produce less harmful content than LLMs trained on general web text.
Conclusion
We launched StarCoder2, a family of LLMs geared for code generation, as well as The Stack v2, the largest pre-training corpus for Code LLMs based on the Software Heritage repository. The Stack v2 is ten times larger than its predecessor and produces a raw dataset of 67.5 TB. We built a training set of around 3TB (900 billion+ tokens) by extensively cleaning, filtering, and subsampling the source code, as well as incorporating other high quality code-related datasets.
Using this new dataset, we trained StarCoder2 models with parameters 3B, 7B, and 15B. Our thorough Code LLM assessments, which assessed code completion, editing, and reasoning capabilities, found that StarCoder2-3B and StarCoder2-15B are cutting-edge models in their respective size classes. We hope that by not only publishing the model weights but also assuring total transparency on the training data, we will boost trust in the developed models and enable other engineering teams and scientists to expand on our efforts.
Reference
[1] Anton Lozhkov1 Raymond Li2 Loubna Ben Allal1 Federico Cassano4 Joel Lamy-Poirier2, (28.02.2024), StarCoder 2 and The Stack v2: The Next Generation
[https://drive.google.com/file/d/17iGn3c-sYNiLyRSY-A85QOzgzGnGiVI3/view]










0 Comments