
https://medium.com/@cbarkinozer/bilgi-grafikleri-kullanarak-nas%C4%B1l-rag-yap%C4%B1l%C4%B1r-aac3f6d12307
Summary of the “Knowledge Graphs for RAG” course on Deeplearning.ai.

NEO4J
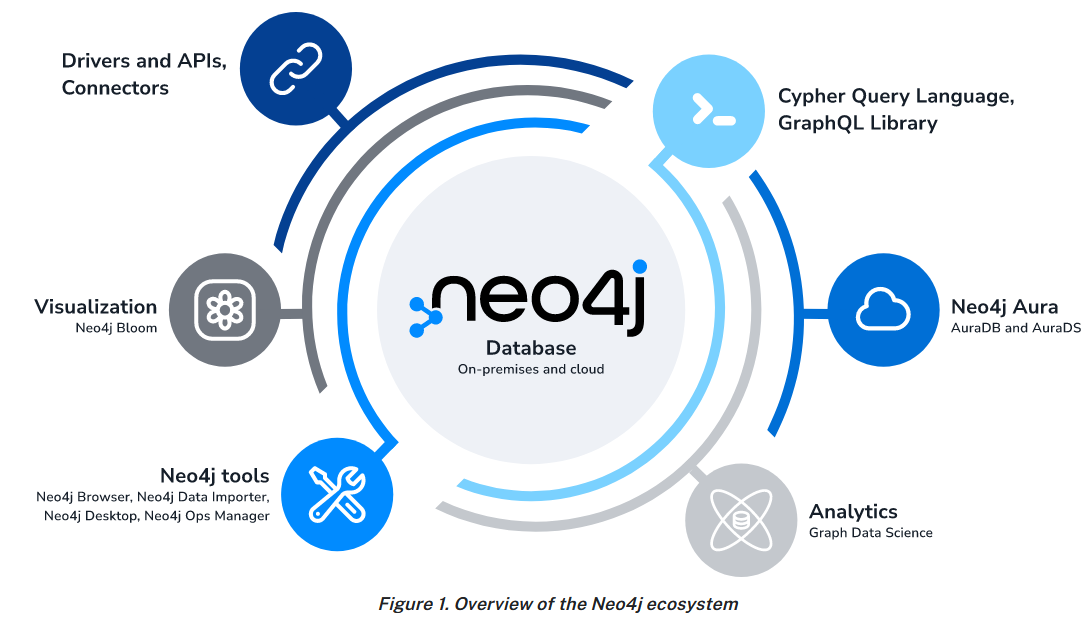
Neo4j uses a native graph database at its heart to store and manage data in a natural, connected form. The graph database employs a property graph method, which improves both traversal performance and operations runtime.
Neo4j began as a graph database and has grown into a robust ecosystem of tools, applications, and libraries. This ecosystem enables you to seamlessly integrate graph technology into your work environment.
For instructions on installing and deploying Neo4j, refer to the Neo4j documentation: [https://neo4j.com/docs/getting-started/get-started-with-neo4j/#neo4j-docs].
Knowledge Graph Fundamentals
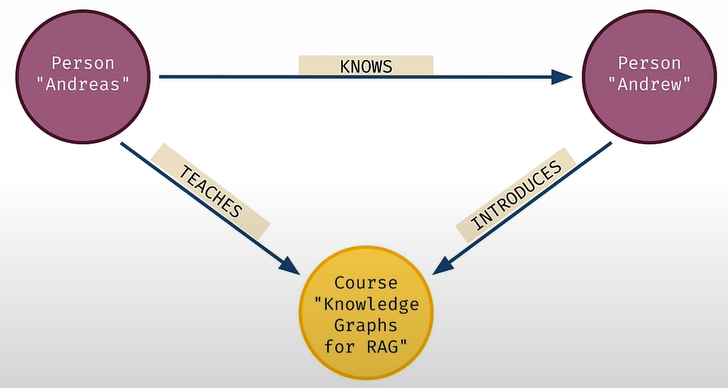
In a Knowledge Graph, nodes represent data records. Relationships among nodes are also data records.

Every relationship has a type and a direction.
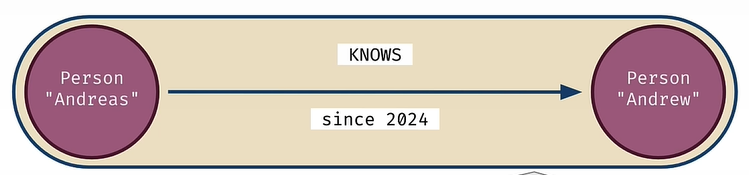
The nodes are connected by a relationship, which has attributes. Graph types are composable.
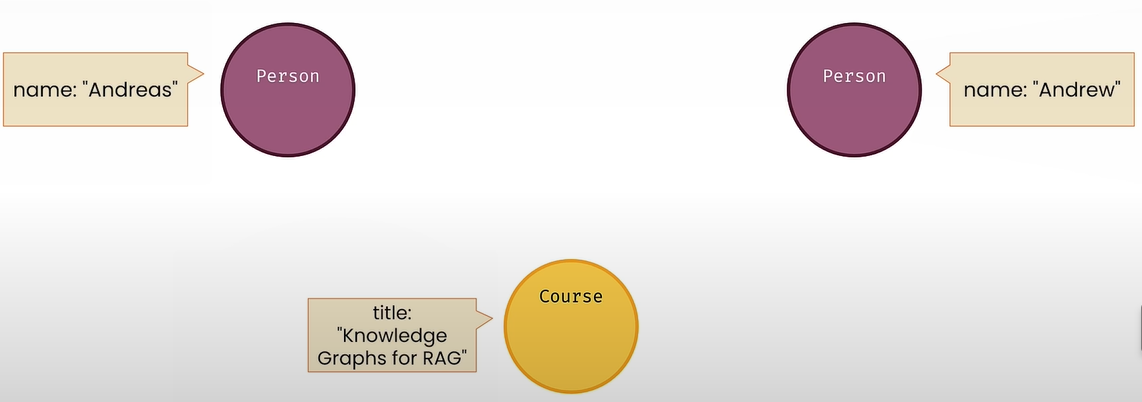
Nodes and relationships are data records that have key/value characteristics.
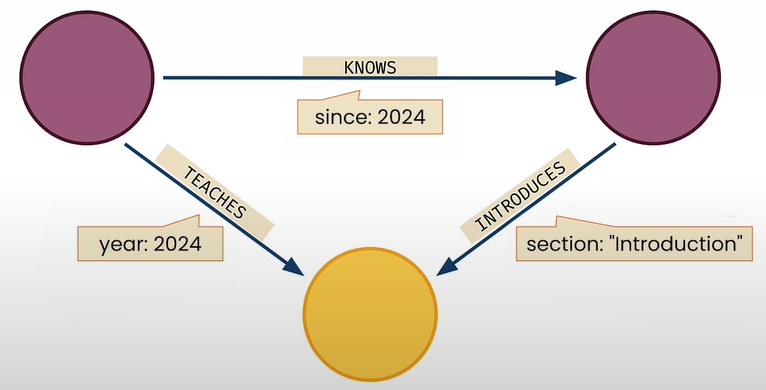
Querying Knowledge Graphs
from dotenv import load_dotenv
import os
from langchain_community.graphs import Neo4jGraph
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE')Initializing a knowledge graph instance with LangChain's Neo4j integration:
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)Querying the movie knowledge graph

Match all nodes in the graph:
cypher = """
MATCH (n)
RETURN count(n)
"""
result = kg.query(cypher)
print(result) # [{'count(n)':171}]
cypher = """
MATCH (n)
RETURN count(n) AS numberOfNodes
"""
result = kg.query(cypher)
print(result) # [{'numberOfNodes':171}]
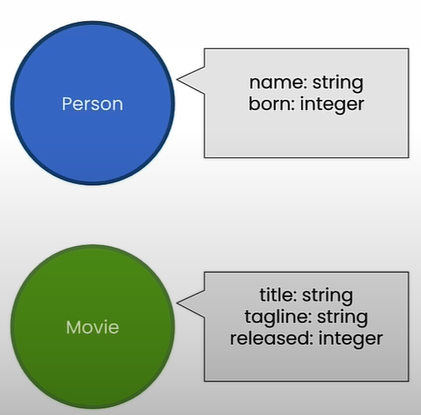
print(f"There are {result[0]['numberOfNodes']} nodes in this graph.") # There are 171 nodes in this graph.Match only the Movie nodes by specifying the node label:
cypher = """
MATCH (n:Movie)
RETURN count(n) AS numberOfMovies
"""
kg.query(cypher) # [{'numberOfMovies':38}]Initializing a knowledge graph instance using LangChain's Neo4j integration:
cypher = """
MATCH (m:Movie)
RETURN count(m) AS numberOfMovies
"""
kg.query(cypher) # [{'numberOfMovies':38}]Match only the Person nodes:
cypher = """
MATCH (people:Person)
RETURN count(people) AS numberOfPeople
"""
kg.query(cypher) # [{'numberOfPeople':133}]Match a single person by specifying the value of the name property on the Person node:
cypher = """
MATCH (tom:Person {name:"Tom Hanks"})
RETURN tom
"""
kg.query(cypher)Match a single Movie by specifying the value of the title property:
cypher = """
MATCH (cloudAtlas:Movie {title:"Cloud Atlas"})
RETURN cloudAtlas
"""
kg.query(cypher)Return only the released property of the matched Movie node:
cypher = """
MATCH (cloudAtlas:Movie {title:"Cloud Atlas"})
RETURN cloudAtlas.released
"""
kg.query(cypher)Return two properties:
cypher = """
MATCH (cloudAtlas:Movie {title:"Cloud Atlas"})
RETURN cloudAtlas.released, cloudAtlas.tagline
"""
kg.query(cypher)Cypher patterns with conditional matching
cypher = """
MATCH (nineties:Movie)
WHERE nineties.released >= 1990
AND nineties.released < 2000
RETURN nineties.title
"""
kg.query(cypher)Pattern matching with multiple nodes
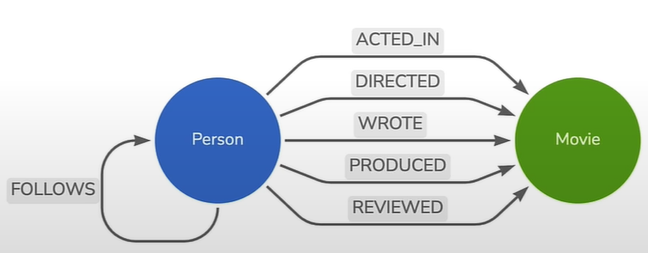
cypher = """
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)
RETURN actor.name, movie.title LIMIT 10
"""
kg.query(cypher)
cypher = """
MATCH (tom:Person {name: "Tom Hanks"})-[:ACTED_IN]->(tomHanksMovies:Movie)
RETURN tom.name,tomHanksMovies.title
"""
kg.query(cypher)
cypher = """
MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors)
RETURN coActors.name, m.title
"""
kg.query(cypher)Delete data from the graph
cypher = """
MATCH (emil:Person {name:"Emil Eifrem"})-[actedIn:ACTED_IN]->(movie:Movie)
RETURN emil.name, movie.title
"""
kg.query(cypher)
cypher = """
MATCH (emil:Person {name:"Emil Eifrem"})-[actedIn:ACTED_IN]->(movie:Movie)
DELETE actedIn
"""
kg.query(cypher)Adding data to the graph
cypher = """
CREATE (andreas:Person {name:"Andreas"})
RETURN andreas
"""
kg.query(cypher)
cypher = """
MATCH (andreas:Person {name:"Andreas"}), (emil:Person {name:"Emil Eifrem"})
MERGE (andreas)-[hasRelationship:WORKS_WITH]->(emil)
RETURN andreas, hasRelationship, emil
"""
kg.query(cypher)Preparing Text for RAG
from dotenv import load_dotenv
import os
from langchain_community.graphs import Neo4jGraph
# Load from environment
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE')
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# Note the code below is unique to this course environment, and not a
# standard part of Neo4j's integration with OpenAI. Remove if running
# in your own environment.
OPENAI_ENDPOINT = os.getenv('OPENAI_BASE_URL') + '/embeddings'
# Connect to the knowledge graph instance using LangChain
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)Create a vector index:
kg.query("""
CREATE VECTOR INDEX movie_tagline_embeddings IF NOT EXISTS
FOR (m:Movie) ON (m.taglineEmbedding)
OPTIONS { indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}"""
)
kg.query("""
SHOW VECTOR INDEXES
"""
)Populate the vector index
Use OpenAI to calculate a vector representation for each movie tagline. Add a vector to the Movie node as the taglineEmbedding attribute.
kg.query("""
MATCH (movie:Movie) WHERE movie.tagline IS NOT NULL
WITH movie, genai.vector.encode(
movie.tagline,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS vector
CALL db.create.setNodeVectorProperty(movie, "taglineEmbedding", vector)
""",
params={"openAiApiKey":OPENAI_API_KEY, "openAiEndpoint": OPENAI_ENDPOINT} )
result = kg.query("""
MATCH (m:Movie)
WHERE m.tagline IS NOT NULL
RETURN m.tagline, m.taglineEmbedding
LIMIT 1
"""
)
result[0]['m.tagline']
result[0]['m.taglineEmbedding'][:10]
len(result[0]['m.taglineEmbedding'])Similarity search
Calculate embedding for the question. Identify matching movies based on the similarities between the question and tagline.Embedding vectors.
question = "What movies are about love?"
kg.query("""
WITH genai.vector.encode(
$question,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS question_embedding
CALL db.index.vector.queryNodes(
'movie_tagline_embeddings',
$top_k,
question_embedding
) YIELD node AS movie, score
RETURN movie.title, movie.tagline, score
""",
params={"openAiApiKey":OPENAI_API_KEY,
"openAiEndpoint": OPENAI_ENDPOINT,
"question": question,
"top_k": 5
})Ask your question:
question = "What movies are about adventure?" # Change here with your question
kg.query("""
WITH genai.vector.encode(
$question,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS question_embedding
CALL db.index.vector.queryNodes(
'movie_tagline_embeddings',
$top_k,
question_embedding
) YIELD node AS movie, score
RETURN movie.title, movie.tagline, score
""",
params={"openAiApiKey":OPENAI_API_KEY,
"openAiEndpoint": OPENAI_ENDPOINT,
"question": question,
"top_k": 5
})Constructing a Knowledge Graph from Text Documents
from dotenv import load_dotenv
import os
# Common data processing
import json
import textwrap
# Langchain
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_openai import ChatOpenAI
# Load from environment
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE') or 'neo4j'
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# Note the code below is unique to this course environment, and not a
# standard part of Neo4j's integration with OpenAI. Remove if running
# in your own environment.
OPENAI_ENDPOINT = os.getenv('OPENAI_BASE_URL') + '/embeddings'
# Global constants
VECTOR_INDEX_NAME = 'form_10k_chunks'
VECTOR_NODE_LABEL = 'Chunk'
VECTOR_SOURCE_PROPERTY = 'text'
VECTOR_EMBEDDING_PROPERTY = 'textEmbedding'Take a look at a Form 10-K JSON file:
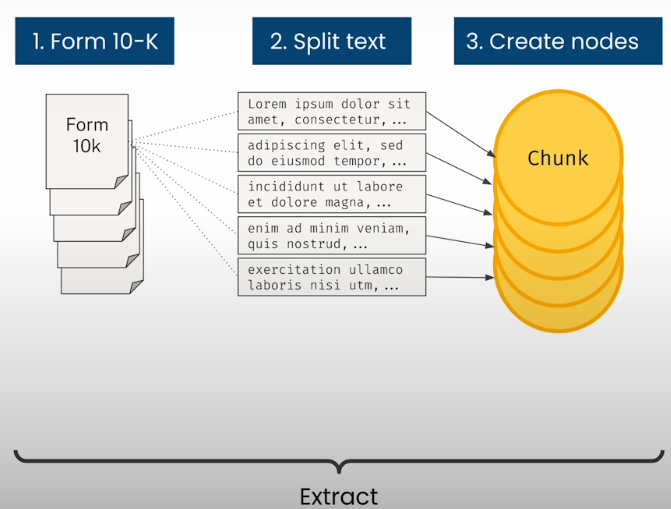
Each year, publicly traded corporations must file a Form 10-K with the Securities and Exchange Commission (SEC). You can search these filings using the SEC’s EDGAR database [https://www.sec.gov/edgar/search/].Data Cleaning
Completed 10-k forms are available for download as text files with XML components. To work with them, the following cleaning procedures should be used:
- Regular expressions are used to clean up files.
Beautiful Soup can be used to parse XML into Python data structures.
Extracted the CIK (Central Index Key) ID, which is the SEC's company identifier.
I extracted particular sections of the form (Items 1, 1a, 7, and 7a).
The Approach:
- Use a Langchain text splitter to break up form sections into chunks.
Create a graph with each chunk as a node and chunk metadata as attributes.
Generate a vector index.
Calculate the text embedding vector for each piece and fill in the index.
Use a similarity search to locate relevant chunks.
first_file_name = "./data/form10k/0000950170-23-027948.json"
first_file_as_object = json.load(open(first_file_name))
for k,v in first_file_as_object.items():
print(k, type(v))
item1_text = first_file_as_object['item1']
item1_text[0:1500]Separate Form 10-K parts into chunks:
Set up a text splitter using LangChain. For the time being, split only the text in the "item 1" part.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 2000,
chunk_overlap = 200,
length_function = len,
is_separator_regex = False,
)
item1_text_chunks = text_splitter.split_text(item1_text)
item1_text_chunks[0]Create a helper function to chunk all portions of the Form 10-K. To speed up the process, you will limit the amount of pieces in each part to 20.
def split_form10k_data_from_file(file):
chunks_with_metadata = [] # use this to accumlate chunk records
file_as_object = json.load(open(file)) # open the json file
for item in ['item1','item1a','item7','item7a']: # pull these keys from the json
print(f'Processing {item} from {file}')
item_text = file_as_object[item] # grab the text of the item
item_text_chunks = text_splitter.split_text(item_text) # split the text into chunks
chunk_seq_id = 0
for chunk in item_text_chunks[:20]: # only take the first 20 chunks
form_id = file[file.rindex('/') + 1:file.rindex('.')] # extract form id from file name
# finally, construct a record with metadata and the chunk text
chunks_with_metadata.append({
'text': chunk,
# metadata from looping...
'f10kItem': item,
'chunkSeqId': chunk_seq_id,
# constructed metadata...
'formId': f'{form_id}', # pulled from the filename
'chunkId': f'{form_id}-{item}-chunk{chunk_seq_id:04d}',
# metadata from file...
'names': file_as_object['names'],
'cik': file_as_object['cik'],
'cusip6': file_as_object['cusip6'],
'source': file_as_object['source'],
})
chunk_seq_id += 1
print(f'\tSplit into {chunk_seq_id} chunks')
return chunks_with_metadata
first_file_chunks = split_form10k_data_from_file(first_file_name)
first_file_chunks[0]Create graph nodes using text chunks:
merge_chunk_node_query = """
MERGE(mergedChunk:Chunk {chunkId: $chunkParam.chunkId})
ON CREATE SET
mergedChunk.names = $chunkParam.names,
mergedChunk.formId = $chunkParam.formId,
mergedChunk.cik = $chunkParam.cik,
mergedChunk.cusip6 = $chunkParam.cusip6,
mergedChunk.source = $chunkParam.source,
mergedChunk.f10kItem = $chunkParam.f10kItem,
mergedChunk.chunkSeqId = $chunkParam.chunkSeqId,
mergedChunk.text = $chunkParam.text
RETURN mergedChunk
"""Set up a connection to the graph instance using LangChain.
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)
# Create a single chunk node for now
kg.query(merge_chunk_node_query,
params={'chunkParam':first_file_chunks[0]})
# Create a uniqueness constraint to avoid duplicate chunks
kg.query("""
CREATE CONSTRAINT unique_chunk IF NOT EXISTS
FOR (c:Chunk) REQUIRE c.chunkId IS UNIQUE
""")
kg.query("SHOW INDEXES")Loop through and add nodes to each chunk. Because you limited the text-splitting algorithm above to 20 chunks, it should generate 23 nodes.
node_count = 0
for chunk in first_file_chunks:
print(f"Creating `:Chunk` node for chunk ID {chunk['chunkId']}")
kg.query(merge_chunk_node_query,
params={
'chunkParam': chunk
})
node_count += 1
kg.query("""
MATCH (n)
RETURN count(n) as nodeCount
""")Create a vector index:
kg.query("""
CREATE VECTOR INDEX `form_10k_chunks` IF NOT EXISTS
FOR (c:Chunk) ON (c.textEmbedding)
OPTIONS { indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
""")
kg.query("SHOW INDEXES")Calculate embedding vectors for chunks and populate the index.
This query computes the embedding vector and saves it to a property named textEmbedding on each chunk node.
kg.query("""
MATCH (chunk:Chunk) WHERE chunk.textEmbedding IS NULL
WITH chunk, genai.vector.encode(
chunk.text,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS vector
CALL db.create.setNodeVectorProperty(chunk, "textEmbedding", vector)
""",
params={"openAiApiKey":OPENAI_API_KEY, "openAiEndpoint": OPENAI_ENDPOINT} )
kg.refresh_schema()
print(kg.schema)Use similarity search to find relevant chunks
Create a help function to run a similarity search using the vector index.
def neo4j_vector_search(question):
"""Search for similar nodes using the Neo4j vector index"""
vector_search_query = """
WITH genai.vector.encode(
$question,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS question_embedding
CALL db.index.vector.queryNodes($index_name, $top_k, question_embedding) yield node, score
RETURN score, node.text AS text
"""
similar = kg.query(vector_search_query,
params={
'question': question,
'openAiApiKey':OPENAI_API_KEY,
'openAiEndpoint': OPENAI_ENDPOINT,
'index_name':VECTOR_INDEX_NAME,
'top_k': 10})
return similar
search_results = neo4j_vector_search(
'In a single sentence, tell me about Netapp.'
)
search_results[0]Set up a LangChain RAG workflow to chat with the form
neo4j_vector_store = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=VECTOR_INDEX_NAME,
node_label=VECTOR_NODE_LABEL,
text_node_properties=[VECTOR_SOURCE_PROPERTY],
embedding_node_property=VECTOR_EMBEDDING_PROPERTY,
)
retriever = neo4j_vector_store.as_retriever()Set up a RetrievalQAWithSourcesChain to handle question answering. You can view the LangChain documentation for this chain here: [https://api.python.langchain.com/en/latest/chains/langchain.chains.qa_with_sources.retrieval.RetrievalQAWithSourcesChain.html]. Adding relationships to the SEC Knowledge Graph.
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever
)
def prettychain(question: str) -> str:
"""Pretty print the chain's response to a question"""
response = chain({"question": question},
return_only_outputs=True,)
print(textwrap.fill(response['answer'], 60))Asking questions:
question = "What is Netapp's primary business?"
prettychain(question)
prettychain("Where is Netapp headquartered?")
prettychain("""
Tell me about Netapp.
Limit your answer to a single sentence.
""")
prettychain("""
Tell me about Apple.
Limit your answer to a single sentence.
""")
prettychain("""
Tell me about Apple.
Limit your answer to a single sentence.
If you are unsure about the answer, say you don't know.
""")
prettychain("""
ADD YOUR OWN QUESTION HERE
""")Adding Relationships to the SEC Knowledge Graph
from dotenv import load_dotenv
import os
# Common data processing
import textwrap
# Langchain
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
# Load from environment
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE') or 'neo4j'
# Global constants
VECTOR_INDEX_NAME = 'form_10k_chunks'
VECTOR_NODE_LABEL = 'Chunk'
VECTOR_SOURCE_PROPERTY = 'text'
VECTOR_EMBEDDING_PROPERTY = 'textEmbedding'
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)Create a Form 10-K node
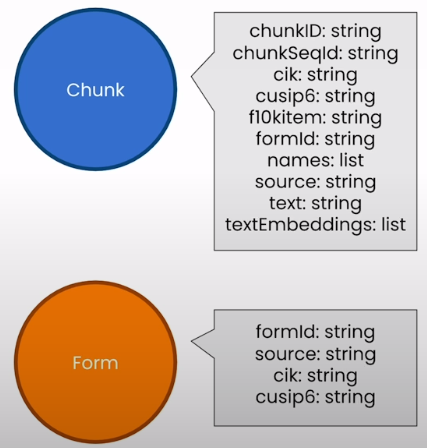
Create a node that represents the whole Form 10-K. Fill in with metadata extracted from a particular section of the form.
cypher = """
MATCH (anyChunk:Chunk)
WITH anyChunk LIMIT 1
RETURN anyChunk { .names, .source, .formId, .cik, .cusip6 } as formInfo
"""
form_info_list = kg.query(cypher)
form_info = form_info_list[0]['formInfo']
cypher = """
MERGE (f:Form {formId: $formInfoParam.formId })
ON CREATE
SET f.names = $formInfoParam.names
SET f.source = $formInfoParam.source
SET f.cik = $formInfoParam.cik
SET f.cusip6 = $formInfoParam.cusip6
"""
kg.query(cypher, params={'formInfoParam': form_info})
kg.query("MATCH (f:Form) RETURN count(f) as formCount")Create a linked list of Chunk nodes for each section
Begin by locating chunks within the same section.
cypher = """
MATCH (from_same_form:Chunk)
WHERE from_same_form.formId = $formIdParam
RETURN from_same_form {.formId, .f10kItem, .chunkId, .chunkSeqId } as chunkInfo
LIMIT 10
"""
kg.query(cypher, params={'formIdParam': form_info['formId']})Order chunks by their sequence ID.
cypher = """
MATCH (from_same_form:Chunk)
WHERE from_same_form.formId = $formIdParam
RETURN from_same_form {.formId, .f10kItem, .chunkId, .chunkSeqId } as chunkInfo
ORDER BY from_same_form.chunkSeqId ASC
LIMIT 10
"""
kg.query(cypher, params={'formIdParam': form_info['formId']})Limit chunks to the "Item 1" area and sort them in ascending order.
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam // NEW!!!
RETURN from_same_section { .formId, .f10kItem, .chunkId, .chunkSeqId }
ORDER BY from_same_section.chunkSeqId ASC
LIMIT 10
"""
kg.query(cypher, params={'formIdParam': form_info['formId'],
'f10kItemParam': 'item1'})Gather organized chunks into a list.
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam
WITH from_same_section { .formId, .f10kItem, .chunkId, .chunkSeqId }
ORDER BY from_same_section.chunkSeqId ASC
LIMIT 10
RETURN collect(from_same_section) // NEW!!!
"""
kg.query(cypher, params={'formIdParam': form_info['formId'],
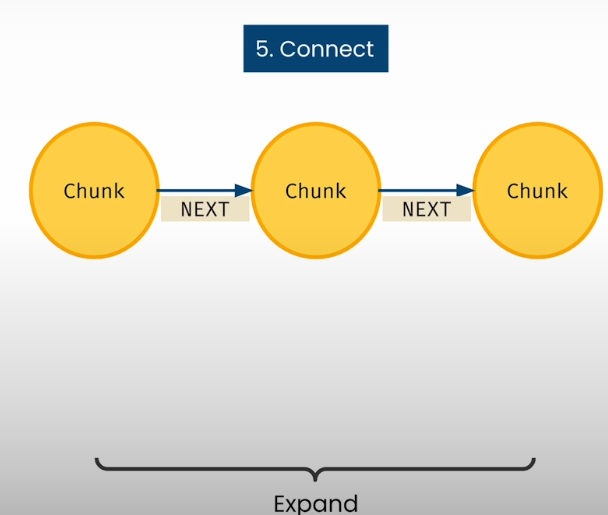
'f10kItemParam': 'item1'})Add a NEXT relationship between subsequent chunks
Use Neo4j's apoc.nodes.link function to link the ordered list of Chunk nodes with a NEXT relationship. Begin with the "Item 1" section.
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam
WITH from_same_section
ORDER BY from_same_section.chunkSeqId ASC
WITH collect(from_same_section) as section_chunk_list
CALL apoc.nodes.link(
section_chunk_list,
"NEXT",
{avoidDuplicates: true}
) // NEW!!!
RETURN size(section_chunk_list)
"""
kg.query(cypher, params={'formIdParam': form_info['formId'],
'f10kItemParam': 'item1'})
kg.refresh_schema()Loop through and establish linkages between all sections of the form 10-K.
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam
WITH from_same_section
ORDER BY from_same_section.chunkSeqId ASC
WITH collect(from_same_section) as section_chunk_list
CALL apoc.nodes.link(
section_chunk_list,
"NEXT",
{avoidDuplicates: true}
)
RETURN size(section_chunk_list)
"""
for form10kItemName in ['item1', 'item1a', 'item7', 'item7a']:
kg.query(cypher, params={'formIdParam':form_info['formId'],
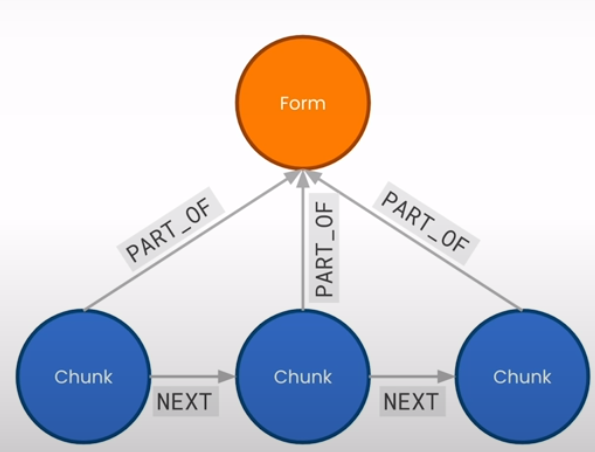
'f10kItemParam': form10kItemName})Connect chunks to their parent form using a PART_OF relationship:
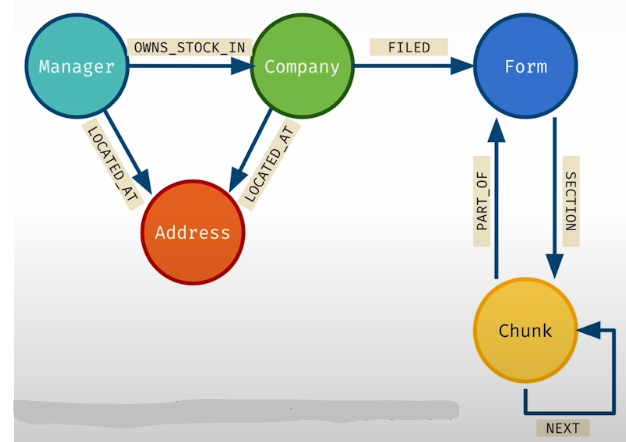
cypher = """https://s172-31-2-251p19846.lab-aws-production.deeplearning.ai/notebooks/L5-add_relationships_to_kg.ipynb#Connect-chunks-to-their-parent-form-with-a-PART_OF-relationship
MATCH (c:Chunk), (f:Form)
WHERE c.formId = f.formId
MERGE (c)-[newRelationship:PART_OF]->(f)
RETURN count(newRelationship)
"""
kg.query(cypher)Add an SECTION connection to the first chunk of each section:
cypher = """
MATCH (first:Chunk), (f:Form)
WHERE first.formId = f.formId
AND first.chunkSeqId = 0
WITH first, f
MERGE (f)-[r:SECTION {f10kItem: first.f10kItem}]->(first)
RETURN count(r)
"""
kg.query(cypher)Example cypher queries
Return to the first part of the Item 1 section.
cypher = """
MATCH (f:Form)-[r:SECTION]->(first:Chunk)
WHERE f.formId = $formIdParam
AND r.f10kItem = $f10kItemParam
RETURN first.chunkId as chunkId, first.text as text
"""
first_chunk_info = kg.query(cypher, params={
'formIdParam': form_info['formId'],
'f10kItemParam': 'item1'
})[0]
Get the second part of the Item 1 portion.
cypher = """
MATCH (first:Chunk)-[:NEXT]->(nextChunk:Chunk)
WHERE first.chunkId = $chunkIdParam
RETURN nextChunk.chunkId as chunkId, nextChunk.text as text
"""
next_chunk_info = kg.query(cypher, params={
'chunkIdParam': first_chunk_info['chunkId']
})[0]
print(first_chunk_info['chunkId'], next_chunk_info['chunkId'])Return a window of three chunks:
cypher = """
MATCH (c1:Chunk)-[:NEXT]->(c2:Chunk)-[:NEXT]->(c3:Chunk)
WHERE c2.chunkId = $chunkIdParam
RETURN c1.chunkId, c2.chunkId, c3.chunkId
"""
kg.query(cypher,
params={'chunkIdParam': next_chunk_info['chunkId']})Information is stored in the structure of a graph
Paths are the matched patterns of nodes and relationships in a graph. A path's length is determined by the number of relationships it contains. Paths can be stored as variables and utilized in subsequent queries.
cypher = """
MATCH window = (c1:Chunk)-[:NEXT]->(c2:Chunk)-[:NEXT]->(c3:Chunk)
WHERE c1.chunkId = $chunkIdParam
RETURN length(window) as windowPathLength
"""
kg.query(cypher,
params={'chunkIdParam': next_chunk_info['chunkId']})Finding variable-length windows
If there is no relationship in the graph, the pattern match will fail. For example, if the first chunk in a section has no previous chunk, the subsequent query will return nothing.
cypher = """
MATCH window=(c1:Chunk)-[:NEXT]->(c2:Chunk)-[:NEXT]->(c3:Chunk)
WHERE c2.chunkId = $chunkIdParam
RETURN nodes(window) as chunkList
"""
# pull the chunk ID from the first
kg.query(cypher,
params={'chunkIdParam': first_chunk_info['chunkId']})Change the NEXT relationship to have variable length.
cypher = """
MATCH window=
(:Chunk)-[:NEXT*0..1]->(c:Chunk)-[:NEXT*0..1]->(:Chunk)
WHERE c.chunkId = $chunkIdParam
RETURN length(window)
"""
kg.query(cypher,
params={'chunkIdParam': first_chunk_info['chunkId']})Retrieve only the longest path.
cypher = """
MATCH window=
(:Chunk)-[:NEXT*0..1]->(c:Chunk)-[:NEXT*0..1]->(:Chunk)
WHERE c.chunkId = $chunkIdParam
WITH window as longestChunkWindow
ORDER BY length(window) DESC LIMIT 1
RETURN length(longestChunkWindow)
"""
kg.query(cypher,
params={'chunkIdParam': first_chunk_info['chunkId']})Customize the results of the similarity search using Cypher
Extend the vector store definition to accept Cypher queries. The Cypher query manipulates the results of the vector similarity search in some way. Begin with a simple query that provides some additional text with the search results.
retrieval_query_extra_text = """
WITH node, score, "Andreas knows Cypher. " as extraText
RETURN extraText + "\n" + node.text as text,
score,
node {.source} AS metadata
"""Configure the vector store to use the query, and then create a retriever and Question-Answer chain in LangChain.
vector_store_extra_text = Neo4jVector.from_existing_index(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=VECTOR_SOURCE_PROPERTY,
retrieval_query=retrieval_query_extra_text, # NEW !!!
)
# Create a retriever from the vector store
retriever_extra_text = vector_store_extra_text.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain_extra_text = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_extra_text
)
# Ask a question
chain_extra_text(
{"question": "What topics does Andreas know about?"},
return_only_outputs=True)It is worth noting that the LLM hallucinates in this case, using both the obtained text and the extra text. Modify the prompt to get a more accurate response.
chain_extra_text(
{"question": "What single topic does Andreas know about?"},
return_only_outputs=True)Try your own with the following template:
Modify the query below to include any additional text. Engineer the prompt to improve your outcomes. It is important to note that every time you alter the Cypher query, you must reset the vector store, retriever, and chain.
# modify the retrieval extra text here then run the entire cell
retrieval_query_extra_text = """
WITH node, score, "Andreas knows Cypher. " as extraText
RETURN extraText + "\n" + node.text as text,
score,
node {.source} AS metadata
"""
vector_store_extra_text = Neo4jVector.from_existing_index(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=VECTOR_SOURCE_PROPERTY,
retrieval_query=retrieval_query_extra_text, # NEW !!!
)
# Create a retriever from the vector store
retriever_extra_text = vector_store_extra_text.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain_extra_text = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_extra_text
)Expand context around a chunk using a window
First, make a standard vector store that returns a single node.
neo4j_vector_store = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=VECTOR_INDEX_NAME,
node_label=VECTOR_NODE_LABEL,
text_node_properties=[VECTOR_SOURCE_PROPERTY],
embedding_node_property=VECTOR_EMBEDDING_PROPERTY,
)
# Create a retriever from the vector store
windowless_retriever = neo4j_vector_store.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
windowless_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=windowless_retriever
)Next, create a window retrieval query to obtain successive chunks.
retrieval_query_window = """
MATCH window=
(:Chunk)-[:NEXT*0..1]->(node)-[:NEXT*0..1]->(:Chunk)
WITH node, score, window as longestWindow
ORDER BY length(window) DESC LIMIT 1
WITH nodes(longestWindow) as chunkList, node, score
UNWIND chunkList as chunkRows
WITH collect(chunkRows.text) as textList, node, score
RETURN apoc.text.join(textList, " \n ") as text,
score,
node {.source} AS metadata
"""Create a QA chain that will run the window retrieval query.
vector_store_window = Neo4jVector.from_existing_index(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=VECTOR_SOURCE_PROPERTY,
retrieval_query=retrieval_query_window, # NEW!!!
)
# Create a retriever from the vector store
retriever_window = vector_store_window.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain_window = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_window
)Comparing two chains
question = "In a single sentence, tell me about Netapp's business."
answer = windowless_chain(
{"question": question},
return_only_outputs=True,
)
print(textwrap.fill(answer["answer"]))
answer = chain_window(
{"question": question},
return_only_outputs=True,
)
print(textwrap.fill(answer["answer"]))Expanding the SEC Knowledge Graph
Import packages and set up Neo4j:
from dotenv import load_dotenv
import os
import textwrap
# Langchain
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_openai import ChatOpenAI
# Load from environment
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE') or 'neo4j'
# Global constants
VECTOR_INDEX_NAME = 'form_10k_chunks'
VECTOR_NODE_LABEL = 'Chunk'
VECTOR_SOURCE_PROPERTY = 'text'
VECTOR_EMBEDDING_PROPERTY = 'textEmbedding'
kg = Neo4jGraph(
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE
)Read the collection of Form 13s
Investment management businesses must record their investments in corporations to the SEC using Form 13. You will load a collection of Form 13s for managers who have invested in NetApp. You can view the CSV file by heading to the data directory via the File menu at the top of the notebook: [https://learn.deeplearning.ai/courses/knowledge-graphs-rag/lesson/7/expanding-the-sec-knowledge-graph]import csv
all_form13s = []
with open('./data/form13.csv', mode='r') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader: # each row will be a dictionary
all_form13s.append(row)Consider the contents of the first five Form 13s:
all_form13s[0:5]Create company nodes in the graph
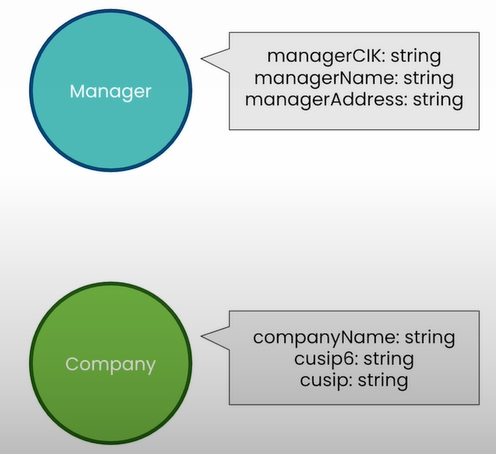
Create Company nodes using the companies listed on Form 13s. Currently, only one corporation exists: NetApp.
# work with just the first form fow now
first_form13 = all_form13s[0]
cypher = """
MERGE (com:Company {cusip6: $cusip6})
ON CREATE
SET com.companyName = $companyName,
com.cusip = $cusip
"""
kg.query(cypher, params={
'cusip6':first_form13['cusip6'],
'companyName':first_form13['companyName'],
'cusip':first_form13['cusip']
})
cypher = """
MATCH (com:Company)
RETURN com LIMIT 1
"""
kg.query(cypher)Update the firm name to match the Form 10-K.
cypher = """
MATCH (com:Company), (form:Form)
WHERE com.cusip6 = form.cusip6
RETURN com.companyName, form.names
"""
kg.query(cypher)
cypher = """
MATCH (com:Company), (form:Form)
WHERE com.cusip6 = form.cusip6
SET com.names = form.names
"""
kg.query(cypher)Establish a FILED link between the corporation and the Form-10K node.
kg.query("""
MATCH (com:Company), (form:Form)
WHERE com.cusip6 = form.cusip6
MERGE (com)-[:FILED]->(form)
""")Create manager nodes
Set up a management node for corporations that have submitted Form 13 to record their NetApp investment. Begin with the single manager who submitted the first Form 13 on the list.
cypher = """
MERGE (mgr:Manager {managerCik: $managerParam.managerCik})
ON CREATE
SET mgr.managerName = $managerParam.managerName,
mgr.managerAddress = $managerParam.managerAddress
"""
kg.query(cypher, params={'managerParam': first_form13})
kg.query("""
MATCH (mgr:Manager)
RETURN mgr LIMIT 1
""")Create a uniqueness constraint to avoid having duplicate managers.
kg.query("""
CREATE CONSTRAINT unique_manager
IF NOT EXISTS
FOR (n:Manager)
REQUIRE n.managerCik IS UNIQUE
""")Create a full-text index of manager names to facilitate text searches.
kg.query("""
CREATE FULLTEXT INDEX fullTextManagerNames
IF NOT EXISTS
FOR (mgr:Manager)
ON EACH [mgr.managerName]
""")
kg.query("""
CALL db.index.fulltext.queryNodes("fullTextManagerNames",
"royal bank") YIELD node, score
RETURN node.managerName, score
""")Create nodes for all organizations who have filed a Form 13.
cypher = """
MERGE (mgr:Manager {managerCik: $managerParam.managerCik})
ON CREATE
SET mgr.managerName = $managerParam.managerName,
mgr.managerAddress = $managerParam.managerAddress
"""
# loop through all Form 13s
for form13 in all_form13s:
kg.query(cypher, params={'managerParam': form13 })
kg.query("""
MATCH (mgr:Manager)
RETURN count(mgr)
""")Create relationships between managers and companies
Match firms and managers using Form 13 data. Establish an OWNS_STOCK_IN link between the management and the corporation. Begin with the single manager who submitted the first Form 13 on the list.
cypher = """
MATCH (mgr:Manager {managerCik: $investmentParam.managerCik}),
(com:Company {cusip6: $investmentParam.cusip6})
RETURN mgr.managerName, com.companyName, $investmentParam as investment
"""
kg.query(cypher, params={
'investmentParam': first_form13
})
cypher = """
MATCH (mgr:Manager {managerCik: $ownsParam.managerCik}),
(com:Company {cusip6: $ownsParam.cusip6})
MERGE (mgr)-[owns:OWNS_STOCK_IN {
reportCalendarOrQuarter: $ownsParam.reportCalendarOrQuarter
}]->(com)
ON CREATE
SET owns.value = toFloat($ownsParam.value),
owns.shares = toInteger($ownsParam.shares)
RETURN mgr.managerName, owns.reportCalendarOrQuarter, com.companyName
"""
kg.query(cypher, params={ 'ownsParam': first_form13 })
kg.query("""
MATCH (mgr:Manager {managerCik: $ownsParam.managerCik})
-[owns:OWNS_STOCK_IN]->
(com:Company {cusip6: $ownsParam.cusip6})
RETURN owns { .shares, .value }
""", params={ 'ownsParam': first_form13 })Establish relationships between all managers who submitted Form 13s and the company:
cypher = """
MATCH (mgr:Manager {managerCik: $ownsParam.managerCik}),
(com:Company {cusip6: $ownsParam.cusip6})
MERGE (mgr)-[owns:OWNS_STOCK_IN {
reportCalendarOrQuarter: $ownsParam.reportCalendarOrQuarter
}]->(com)
ON CREATE
SET owns.value = toFloat($ownsParam.value),
owns.shares = toInteger($ownsParam.shares)
"""
#loop through all Form 13s
for form13 in all_form13s:
kg.query(cypher, params={'ownsParam': form13 })
cypher = """
MATCH (:Manager)-[owns:OWNS_STOCK_IN]->(:Company)
RETURN count(owns) as investments
"""
kg.query(cypher)
kg.refresh_schema()
print(textwrap.fill(kg.schema, 60))Determine the number of investors
Begin by locating a form 10-K chunk and saving it for use in subsequent inquiries.
cypher = """
MATCH (chunk:Chunk)
RETURN chunk.chunkId as chunkId LIMIT 1
"""
chunk_rows = kg.query(cypher)
print(chunk_rows)
chunk_first_row = chunk_rows[0]
print(chunk_first_row)
ref_chunk_id = chunk_first_row['chunkId']
ref_chunk_idCreate a path from the Form 10-K piece to corporations and managers.
cypher = """
MATCH (:Chunk {chunkId: $chunkIdParam})-[:PART_OF]->(f:Form)
RETURN f.source
"""
kg.query(cypher, params={'chunkIdParam': ref_chunk_id})
cypher = """
MATCH (:Chunk {chunkId: $chunkIdParam})-[:PART_OF]->(f:Form),
(com:Company)-[:FILED]->(f)
RETURN com.companyName as name
"""
kg.query(cypher, params={'chunkIdParam': ref_chunk_id})
cypher = """
MATCH (:Chunk {chunkId: $chunkIdParam})-[:PART_OF]->(f:Form),
(com:Company)-[:FILED]->(f),
(mgr:Manager)-[:OWNS_STOCK_IN]->(com)
RETURN com.companyName,
count(mgr.managerName) as numberOfinvestors
LIMIT 1
"""
kg.query(cypher, params={
'chunkIdParam': ref_chunk_id
})Use queries to build additional context for LLM
Create sentences that show how much stock a manager has put in a corporation.
cypher = """
MATCH (:Chunk {chunkId: $chunkIdParam})-[:PART_OF]->(f:Form),
(com:Company)-[:FILED]->(f),
(mgr:Manager)-[owns:OWNS_STOCK_IN]->(com)
RETURN mgr.managerName + " owns " + owns.shares +
" shares of " + com.companyName +
" at a value of $" +
apoc.number.format(toInteger(owns.value)) AS text
LIMIT 10
"""
kg.query(cypher, params={
'chunkIdParam': ref_chunk_id
})
results = kg.query(cypher, params={
'chunkIdParam': ref_chunk_id
})
print(textwrap.fill(results[0]['text'], 60))Create a simple question-and-answer chain. Cypher Query just does a similarity search; no augmentation occurs.
vector_store = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=VECTOR_INDEX_NAME,
node_label=VECTOR_NODE_LABEL,
text_node_properties=[VECTOR_SOURCE_PROPERTY],
embedding_node_property=VECTOR_EMBEDDING_PROPERTY,
)
# Create a retriever from the vector store
retriever = vector_store.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
plain_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever
)Build a second QA chain. Use sentences from the investment question above to augment the similarity search.
investment_retrieval_query = """
MATCH (node)-[:PART_OF]->(f:Form),
(f)<-[:FILED]-(com:Company),
(com)<-[owns:OWNS_STOCK_IN]-(mgr:Manager)
WITH node, score, mgr, owns, com
ORDER BY owns.shares DESC LIMIT 10
WITH collect (
mgr.managerName +
" owns " + owns.shares +
" shares in " + com.companyName +
" at a value of $" +
apoc.number.format(toInteger(owns.value)) + "."
) AS investment_statements, node, score
RETURN apoc.text.join(investment_statements, "\n") +
"\n" + node.text AS text,
score,
{
source: node.source
} as metadata
"""
vector_store_with_investment = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=VECTOR_SOURCE_PROPERTY,
retrieval_query=investment_retrieval_query,
)
# Create a retriever from the vector store
retriever_with_investments = vector_store_with_investment.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
investment_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_with_investments
)Compare the outputs!
question = "In a single sentence, tell me about Netapp."
plain_chain(
{"question": question},
return_only_outputs=True,
)
investment_chain(
{"question": question},
return_only_outputs=True,
)The LLM did not use the investor information because the query did not specifically mention investors. Change your question and ask again.
question = "In a single sentence, tell me about Netapp investors."
plain_chain(
{"question": question},
return_only_outputs=True,
)
investment_chain(
{"question": question},
return_only_outputs=True,
)Change the query above to retrieve further information. Try other questions. It is important to note that changing the Cypher query will require you to reset the retriever and QA chain.
Chatting with the SEC Knowledge Graph
How a knowledge graph is created?
Begin with a minimal viable graph (MVG), then extract, enhance, expand, and repeat to extend the graph. Extracting means identifying interesting information. Enhancing means supercharging the data. Expanding entails connecting facts to broaden context.

You may continue to expand the knowledge graph by cross-linking companies that reference each other, adding individuals, locations, and themes extracted from text, adding more form data or relevant data sources, and adding users to improve relevance and enable feedback.
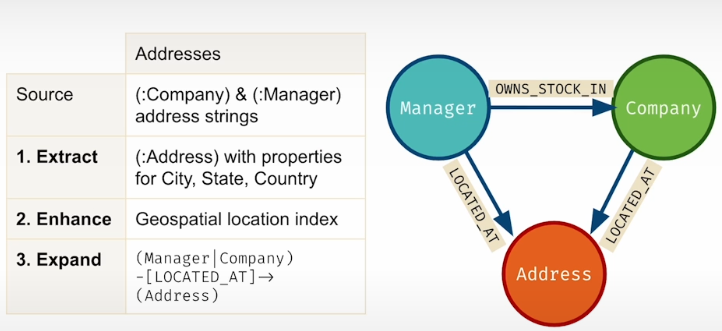
Extract (:Adresses) Nodes:
- Extract the whole address strings.
- Geocode to get city, state, nation, altitude, and longitude.
Enhance with geospatial index
- Enable distance queries
Expand -[:LOCATED_AT]->relationships
- Connect (:Manager), (:Company) nodes to (:Address)
Import packages and set up Neo4j
from dotenv import load_dotenv
import os
import textwrap
# Langchain
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import OpenAIEmbeddings
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
# Load from environment
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE') or 'neo4j'
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# Note the code below is unique to this course environment, and not a
# standard part of Neo4j's integration with OpenAI. Remove if running
# in your own environment.
OPENAI_ENDPOINT = os.getenv('OPENAI_BASE_URL') + '/embeddings'
# Global constants
VECTOR_INDEX_NAME = 'form_10k_chunks'
VECTOR_NODE_LABEL = 'Chunk'
VECTOR_SOURCE_PROPERTY = 'text'
VECTOR_EMBEDDING_PROPERTY = 'textEmbedding'
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)Explore the updated SEC documents graph
Let's start with an updated graph that contains the address information mentioned in the video.
kg.refresh_schema()
print(textwrap.fill(kg.schema, 60))Check the address of a random Manager. The company returned by the following query may differ from that shown in the video.
kg.query("""
MATCH (mgr:Manager)-[:LOCATED_AT]->(addr:Address)
RETURN mgr, addr
LIMIT 1
""")Conduct a full-text search for a manager named Royal Bank.
kg.query("""
CALL db.index.fulltext.queryNodes(
"fullTextManagerNames",
"royal bank") YIELD node, score
RETURN node.managerName, score LIMIT 1
""")Find the location of Royal Bank.
kg.query("""
CALL db.index.fulltext.queryNodes(
"fullTextManagerNames",
"royal bank"
) YIELD node, score
WITH node as mgr LIMIT 1
MATCH (mgr:Manager)-[:LOCATED_AT]->(addr:Address)
RETURN mgr.managerName, addr
""")Determine the state with the most investment firms.
kg.query("""
MATCH p=(:Manager)-[:LOCATED_AT]->(address:Address)
RETURN address.state as state, count(address.state) as numManagers
ORDER BY numManagers DESC
LIMIT 10
""")Determine which state has the most companies.
kg.query("""
MATCH p=(:Company)-[:LOCATED_AT]->(address:Address)
RETURN address.state as state, count(address.state) as numCompanies
ORDER BY numCompanies DESC
""")What are the cities in California with the most investment firms?
kg.query("""
MATCH p=(:Manager)-[:LOCATED_AT]->(address:Address)
WHERE address.state = 'California'
RETURN address.city as city, count(address.city) as numManagers
ORDER BY numManagers DESC
LIMIT 10
""")Which city in California has the most companies listed?
kg.query("""
MATCH p=(:Company)-[:LOCATED_AT]->(address:Address)
WHERE address.state = 'California'
RETURN address.city as city, count(address.city) as numCompanies
ORDER BY numCompanies DESC
""")What are the top investment firms in San Francisco?
kg.query("""
MATCH p=(mgr:Manager)-[:LOCATED_AT]->(address:Address),
(mgr)-[owns:OWNS_STOCK_IN]->(:Company)
WHERE address.city = "San Francisco"
RETURN mgr.managerName, sum(owns.value) as totalInvestmentValue
ORDER BY totalInvestmentValue DESC
LIMIT 10
""")What companies are located in Santa Clara?
kg.query("""
MATCH (com:Company)-[:LOCATED_AT]->(address:Address)
WHERE address.city = "Santa Clara"
RETURN com.companyName
""")What companies are near Santa Clara?
kg.query("""
MATCH (sc:Address)
WHERE sc.city = "Santa Clara"
MATCH (com:Company)-[:LOCATED_AT]->(comAddr:Address)
WHERE point.distance(sc.location, comAddr.location) < 10000
RETURN com.companyName, com.companyAddress
""")What investment firms are near Santa Clara?
Let’s try updating the distance in the query to expand the search radius.
kg.query("""
MATCH (address:Address)
WHERE address.city = "Santa Clara"
MATCH (mgr:Manager)-[:LOCATED_AT]->(managerAddress:Address)
WHERE point.distance(address.location,
managerAddress.location) < 10000
RETURN mgr.managerName, mgr.managerAddress
""")Which investment firms are near Palo Alto Networks?
Note that full-text search can handle typos!
# Which investment firms are near Palo Aalto Networks?
kg.query("""
CALL db.index.fulltext.queryNodes(
"fullTextCompanyNames",
"Palo Aalto Networks"
) YIELD node, score
WITH node as com
MATCH (com)-[:LOCATED_AT]->(comAddress:Address),
(mgr:Manager)-[:LOCATED_AT]->(mgrAddress:Address)
WHERE point.distance(comAddress.location,
mgrAddress.location) < 10000
RETURN mgr,
toInteger(point.distance(comAddress.location,
mgrAddress.location) / 1000) as distanceKm
ORDER BY distanceKm ASC
LIMIT 10
""")You can learn more about Cypher at the neo4j website: [https://neo4j.com/product/cypher-graph-query-language/]
Writing Cypher with an LLM
We'll utilize few-shot learning to educate an LLM on how to write Cypher. We will utilize OpenAI's GPT 3.5 model. We'll also leverage GraphCypherQAChain, a new Neo4j integration built into LangChain.
CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to
query a graph database.
Instructions:
Use only the provided relationship types and properties in the
schema. Do not use any other relationship types or properties that
are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than
for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Examples: Here are a few examples of generated Cypher
statements for particular questions:
# What investment firms are in San Francisco?
MATCH (mgr:Manager)-[:LOCATED_AT]->(mgrAddress:Address)
WHERE mgrAddress.city = 'San Francisco'
RETURN mgr.managerName
The question is:
{question}"""
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"],
template=CYPHER_GENERATION_TEMPLATE
)
cypherChain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=kg,
verbose=True,
cypher_prompt=CYPHER_GENERATION_PROMPT,
)
def prettyCypherChain(question: str) -> str:
response = cypherChain.run(question)
print(textwrap.fill(response, 60))
prettyCypherChain("What investment firms are in San Francisco?")
prettyCypherChain("What investment firms are in Menlo Park?")
prettyCypherChain("What companies are in Santa Clara?")
prettyCypherChain("What investment firms are near Santa Clara?")Expand the prompt to teach the LLM new Cypher patterns
CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Examples: Here are a few examples of generated Cypher statements for particular questions:
# What investment firms are in San Francisco?
MATCH (mgr:Manager)-[:LOCATED_AT]->(mgrAddress:Address)
WHERE mgrAddress.city = 'San Francisco'
RETURN mgr.managerName
# What investment firms are near Santa Clara?
MATCH (address:Address)
WHERE address.city = "Santa Clara"
MATCH (mgr:Manager)-[:LOCATED_AT]->(managerAddress:Address)
WHERE point.distance(address.location,
managerAddress.location) < 10000
RETURN mgr.managerName, mgr.managerAddress
The question is:
{question}"""Update the Cypher generating prompt with a new template, then reset the Cypher chain to use the new prompt. Rerun this code whenever you make a modification to the Cypher generating template!
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"],
template=CYPHER_GENERATION_TEMPLATE
)
cypherChain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=kg,
verbose=True,
cypher_prompt=CYPHER_GENERATION_PROMPT,
)
prettyCypherChain("What investment firms are near Santa Clara?")Expand the query to retrieve information from the Form 10K chunks
CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Examples: Here are a few examples of generated Cypher statements for particular questions:
# What investment firms are in San Francisco?
MATCH (mgr:Manager)-[:LOCATED_AT]->(mgrAddress:Address)
WHERE mgrAddress.city = 'San Francisco'
RETURN mgr.managerName
# What investment firms are near Santa Clara?
MATCH (address:Address)
WHERE address.city = "Santa Clara"
MATCH (mgr:Manager)-[:LOCATED_AT]->(managerAddress:Address)
WHERE point.distance(address.location,
managerAddress.location) < 10000
RETURN mgr.managerName, mgr.managerAddress
# What does Palo Alto Networks do?
CALL db.index.fulltext.queryNodes(
"fullTextCompanyNames",
"Palo Alto Networks"
) YIELD node, score
WITH node as com
MATCH (com)-[:FILED]->(f:Form),
(f)-[s:SECTION]->(c:Chunk)
WHERE s.f10kItem = "item1"
RETURN c.text
The question is:
{question}"""
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"],
template=CYPHER_GENERATION_TEMPLATE
)
cypherChain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=kg,
verbose=True,
cypher_prompt=CYPHER_GENERATION_PROMPT,
)
prettyCypherChain("What does Palo Alto Networks do?")You can change the Cypher generating prompt below to ask various questions about the graph. You can use the "check schema" box to remind yourself of the graph structure.
# Check the graph schema
kg.refresh_schema()
print(textwrap.fill(kg.schema, 60))
CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Examples: Here are a few examples of generated Cypher statements for particular questions:
# What investment firms are in San Francisco?
MATCH (mgr:Manager)-[:LOCATED_AT]->(mgrAddress:Address)
WHERE mgrAddress.city = 'San Francisco'
RETURN mgr.managerName
# What investment firms are near Santa Clara?
MATCH (address:Address)
WHERE address.city = "Santa Clara"
MATCH (mgr:Manager)-[:LOCATED_AT]->(managerAddress:Address)
WHERE point.distance(address.location,
managerAddress.location) < 10000
RETURN mgr.managerName, mgr.managerAddress
# What does Palo Alto Networks do?
CALL db.index.fulltext.queryNodes(
"fullTextCompanyNames",
"Palo Alto Networks"
) YIELD node, score
WITH node as com
MATCH (com)-[:FILED]->(f:Form),
(f)-[s:SECTION]->(c:Chunk)
WHERE s.f10kItem = "item1"
RETURN c.text
The question is:
{question}"""
# Update the prompt and reset the QA chain
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"],
template=CYPHER_GENERATION_TEMPLATE
)
cypherChain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=kg,
verbose=True,
cypher_prompt=CYPHER_GENERATION_PROMPT,
)
prettyCypherChain("<<REPLACE WITH YOUR QUESTION>>")Resources
[1] Deeplearningai, (April 2024), Knowledge Graphs for RAG:
[https://learn.deeplearning.ai/courses/knowledge-graphs-rag]










0 Comments