
Deeplearning.ai’s “Building and Evaluating Advanced RAG Applications” course’s detailed summary.

This course will show you how to construct production-ready RAG-based LLM apps.
This course examines two advanced retrieval approaches: sentence window retrieval and auto-merging retrieval, which provide substantially better context for the LLM than simpler methods. This course also teaches you how to evaluate your LLM question-answering system using three evaluation metrics: context-relevance, groundedness, and answer relevance.
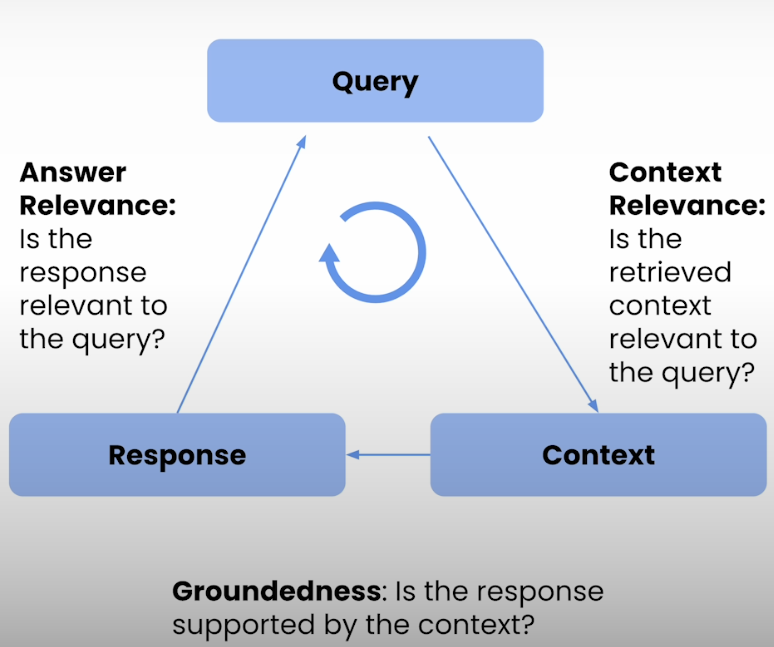
To evaluate RAG-based LLM programs, the RAG triad of metrics for the three primary steps of a RAG's execution is quite useful. For example, we will go over in detail how to compute context relevance, which quantifies how relevant the retrieved pieces of text are to the user's queries.This helps you identify and debug possible issues with how your system retrieves context for the LLM overall QA system.
Advanced RAG Pipeline
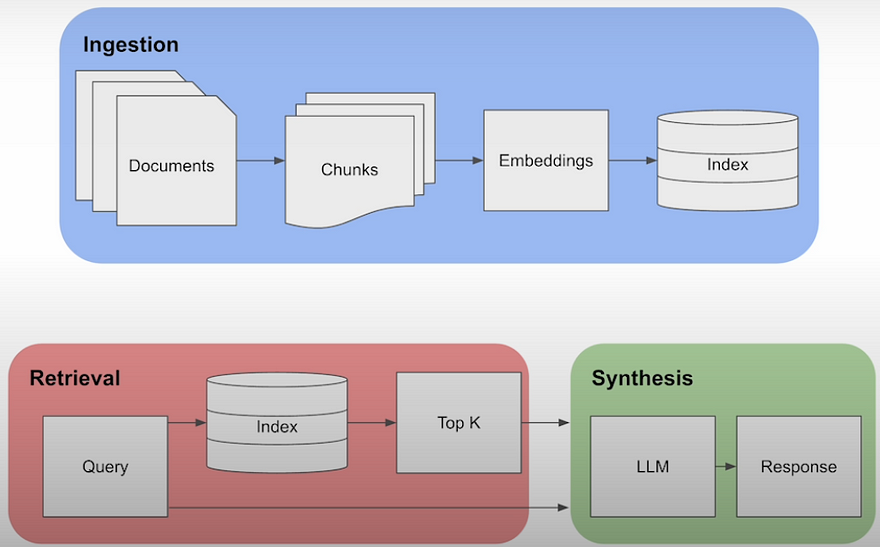
A basic RAG architecture consists of three parts: intake, retrieval, and synthesis.
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
print(type(documents), "\n")
print(len(documents), "\n")
print(type(documents[0]))
print(documents[0])Basic RAG pipeline
from llama_index import Document
document = Document(text="\n\n".join([doc.text for doc in documents]))
from llama_index import VectorStoreIndex
from llama_index import ServiceContext
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
service_context = ServiceContext.from_defaults(
llm=llm, embed_model="local:BAAI/bge-small-en-v1.5"
)
index = VectorStoreIndex.from_documents([document],
service_context=service_context)
query_engine = index.as_query_engine()
response = query_engine.query(
"What are steps to take when finding projects to build your experience?"
)
print(str(response))Evaluation setup using TruLens
The RAG system has three key components. Answer relevance (is the response relevant to the question), context relevance (is the retrieved context relevant to the query), and groundedness (is the context supporting the response).
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
# Remove newline character and convert to integer
item = line.strip()
print(item)
eval_questions.append(item)
# You can try your own question:
new_question = "What is the right AI job for me?"
eval_questions.append(new_question)
print(eval_questions)
from trulens_eval import Tru
tru = Tru()
tru.reset_database()
from utils import get_prebuilt_trulens_recorder
tru_recorder = get_prebuilt_trulens_recorder(query_engine,
app_id="Direct Query Engine")
with tru_recorder as recording:
for question in eval_questions:
response = query_engine.query(question)
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
The following columns are included: app_id, app_json, type, record_id, input, output, tags, record_json, cost_json, and perf_json. Groundedness, Answer, Relevance_calls, Context Relevance_calls, Groundedness_calls, delay, total_tokens, and total_cost.
# launches on http://localhost:8501/
tru.run_dashboard()Starting dashboard ...
Config file already exists. Skipping writing process.
Credentials file already exists. Skipping writing process.
Dashboard Log
Dashboard started at https://s172-31-12-156p53074.lab-aws-production.deeplearning.ai/ .
<Popen: returncode: None args: ['streamlit', 'run', '--server.headless=True'...>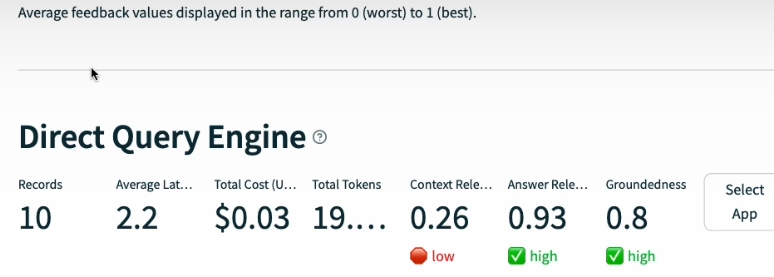
Advanced RAG pipeline
1. Sentence Window retrieval
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
from utils import build_sentence_window_index
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
from utils import get_sentence_window_query_engine
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
window_response = sentence_window_engine.query(
"how do I get started on a personal project in AI?"
)
print(str(window_response))
tru.reset_database()
tru_recorder_sentence_window = get_prebuilt_trulens_recorder(
sentence_window_engine,
app_id = "Sentence Window Query Engine"
)
for question in eval_questions:
with tru_recorder_sentence_window as recording:
response = sentence_window_engine.query(question)
print(question)
print(str(response))
tru.get_leaderboard(app_ids=[])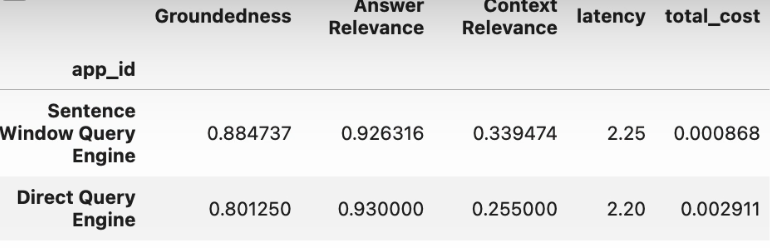
# launches on http://localhost:8501/
tru.run_dashboard()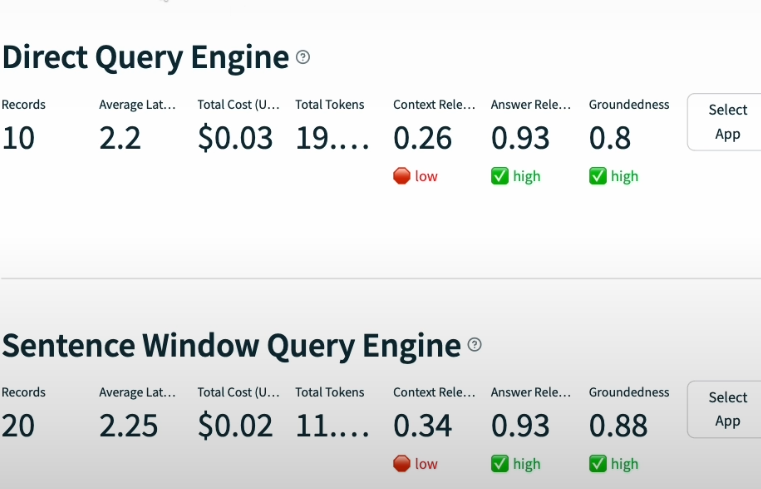
2. Auto-merging retrieval
from utils import build_automerging_index
automerging_index = build_automerging_index(
documents,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="merging_index"
)
from utils import get_automerging_query_engine
automerging_query_engine = get_automerging_query_engine(
automerging_index,
)
auto_merging_response = automerging_query_engine.query(
"How do I build a portfolio of AI projects?"
)
print(str(auto_merging_response))
tru.reset_database()
tru_recorder_automerging = get_prebuilt_trulens_recorder(automerging_query_engine,
app_id="Automerging Query Engine")
for question in eval_questions:
with tru_recorder_automerging as recording:
response = automerging_query_engine.query(question)
print(question)
print(response)> Merging 2 nodes into parent node.
> Parent node id: 9cf055b6-c82d-42f0-9b13-0d99b2d3acd2.
> Parent node text: PAGE 3Table of
ContentsIntroduction: Coding AI is the New Literacy.
Chapter 1: Three Steps to Ca...
> Merging 1 nodes into parent node.
> Parent node id: 1bd270b3-c6ac-43ab-9c07-30611601ae3f.
> Parent node text: PAGE 3Table of
ContentsIntroduction: Coding AI is the New Literacy.
Chapter 1: Three Steps to Ca...
What are the keys to building a career in AI?
Learning foundational technical skills, working on projects, finding a job, and being part of a community are essential keys to building a career in AI. Additionally, collaborating with others, influencing, and being influenced by others are crucial aspects for success in AI.
How can teamwork contribute to success in AI?
Teamwork can contribute to success in AI by enabling individuals to work more effectively on large projects. Collaborating in teams allows for a pooling of diverse skills and perspectives, leading to better problem-solving and innovation. Additionally, the ability to work with others, influence them, and be influenced by them is crucial in the field of AI.
> Merging 3 nodes into parent node.
> Parent node id: 58c7116d-2f08-4eb6-9024-6dfcd58571f4.
> Parent node text: PAGE 35Keys to Building a Career in AI CHAPTER 10
The path to career success in AI is more comple...
> Merging 1 nodes into parent node.
> Parent node id: 262ec000-02f8-49da-afbe-6deeebc6b8f5.
> Parent node text: PAGE 35Keys to Building a Career in AI CHAPTER 10
The path to career success in AI is more comple...
What is the importance of networking in AI?
Networking in AI is crucial as it helps in building a strong professional network within the industry. This network can provide support, guidance, and opportunities for career advancement. By connecting with others in the field, individuals can gain valuable insights, stay updated on industry trends, and potentially find mentors who can help them navigate their career paths effectively.
> Merging 2 nodes into parent node.
> Parent node id: c98aeacf-aa18-4d22-be40-a355e2c3de11.
> Parent node text: PAGE 36Keys to Building a Career in AI CHAPTER 10
Of all the steps in building a career, this
on...
> Merging 2 nodes into parent node.
> Parent node id: b999d07a-62b3-45cd-9c8b-fd5fb827136a.
> Parent node text: PAGE 11
The Best Way to Build
a New Habit
One of my favorite books is BJ Fogg’s, Tiny Habits: Th...
> Merging 1 nodes into parent node.
> Parent node id: 2a2fee45-9973-4f82-8558-c1a5b3933b18.
> Parent node text: PAGE 36Keys to Building a Career in AI CHAPTER 10
Of all the steps in building a career, this
on...
> Merging 1 nodes into parent node.
> Parent node id: 38e01f2f-1443-42e5-b33a-5532e904e708.
> Parent node text: PAGE 11
The Best Way to Build
a New Habit
One of my favorite books is BJ Fogg’s, Tiny Habits: Th...
What are some good habits to develop for a successful career?
Good habits to develop for a successful career include habits related to eating well, exercising regularly, getting enough sleep, maintaining positive personal relationships, consistently working towards learning and self-improvement, and practicing self-care. These habits can help individuals progress in their careers while also ensuring their overall well-being.
> Merging 2 nodes into parent node.
> Parent node id: f5c4fced-a276-4c81-bbc6-5c9b9115a791.
> Parent node text: PAGE 30Finding someone to interview isn’t always easy, but many people who are in senior position...
> Merging 1 nodes into parent node.
> Parent node id: 83590d05-f6da-4ae7-bbe6-23e57c85fe3c.
> Parent node text: PAGE 30Finding someone to interview isn’t always easy, but many people who are in senior position...
How can altruism be beneficial in building a career?
Altruism can be beneficial in building a career by creating a positive impact on others, fostering strong relationships within professional networks, and potentially leading to opportunities for collaboration and mentorship.
> Merging 5 nodes into parent node.
> Parent node id: 8ba83d26-9c05-449d-9f9b-991d595c779c.
> Parent node text: PAGE 38Before we dive into the final chapter of this book, I’d like to address the serious matter...
> Merging 1 nodes into parent node.
> Parent node id: 88fb1eff-ac7e-4f56-b0b3-4b10a5f74154.
> Parent node text: PAGE 37Overcoming Imposter
SyndromeCHAPTER 11
> Merging 3 nodes into parent node.
> Parent node id: 6460f5fe-7745-4d12-a22d-abe5dae45c4c.
> Parent node text: PAGE 39My three-year-old daughter (who can barely count to 12) regularly tries to teach things to...
> Merging 1 nodes into parent node.
> Parent node id: 0ef88b9f-7021-47c8-9c56-a745e4c0269b.
> Parent node text: PAGE 38Before we dive into the final chapter of this book, I’d like to address the serious matter...
> Merging 1 nodes into parent node.
> Parent node id: f61060f2-c810-46fe-8866-1e248e6f134d.
> Parent node text: PAGE 37Overcoming Imposter
SyndromeCHAPTER 11
> Merging 1 nodes into parent node.
> Parent node id: d795762e-a5cc-480c-b473-04b3a1fffd3c.
> Parent node text: PAGE 39My three-year-old daughter (who can barely count to 12) regularly tries to teach things to...
What is imposter syndrome and how does it relate to AI?
Imposter syndrome is when an individual doubts their accomplishments and has a persistent fear of being exposed as a fraud, despite evidence of their competence. In the context of AI, newcomers to the field may experience imposter syndrome due to the technical complexity and the presence of highly capable individuals. It is highlighted that imposter syndrome is common even among accomplished people in the AI community, and the message is to not let it discourage anyone from pursuing growth in AI.
> Merging 3 nodes into parent node.
> Parent node id: 8ba83d26-9c05-449d-9f9b-991d595c779c.
> Parent node text: PAGE 38Before we dive into the final chapter of this book, I’d like to address the serious matter...
> Merging 1 nodes into parent node.
> Parent node id: 88fb1eff-ac7e-4f56-b0b3-4b10a5f74154.
> Parent node text: PAGE 37Overcoming Imposter
SyndromeCHAPTER 11
> Merging 3 nodes into parent node.
> Parent node id: 6460f5fe-7745-4d12-a22d-abe5dae45c4c.
> Parent node text: PAGE 39My three-year-old daughter (who can barely count to 12) regularly tries to teach things to...
> Merging 1 nodes into parent node.
> Parent node id: 0ef88b9f-7021-47c8-9c56-a745e4c0269b.
> Parent node text: PAGE 38Before we dive into the final chapter of this book, I’d like to address the serious matter...
> Merging 1 nodes into parent node.
> Parent node id: f61060f2-c810-46fe-8866-1e248e6f134d.
> Parent node text: PAGE 37Overcoming Imposter
SyndromeCHAPTER 11
> Merging 1 nodes into parent node.
> Parent node id: d795762e-a5cc-480c-b473-04b3a1fffd3c.
> Parent node text: PAGE 39My three-year-old daughter (who can barely count to 12) regularly tries to teach things to...
Who are some accomplished individuals who have experienced imposter syndrome?
Former Facebook COO Sheryl Sandberg, U.S. first lady Michelle Obama, actor Tom Hanks, and Atlassian co-CEO Mike Cannon-Brookes are some accomplished individuals who have experienced imposter syndrome.
What is the first step to becoming good at AI?
The first step to becoming good at AI is to suck at it.
What are some common challenges in AI?
Some common challenges in AI include the highly iterative nature of AI projects, uncertainty in estimating the time required to achieve target accuracy, technical challenges faced by individuals working on AI projects, and feelings of imposter syndrome among those entering the AI community.
> Merging 3 nodes into parent node.
> Parent node id: 8ba83d26-9c05-449d-9f9b-991d595c779c.
> Parent node text: PAGE 38Before we dive into the final chapter of this book, I’d like to address the serious matter...
> Merging 1 nodes into parent node.
> Parent node id: 0ef88b9f-7021-47c8-9c56-a745e4c0269b.
> Parent node text: PAGE 38Before we dive into the final chapter of this book, I’d like to address the serious matter...
Is it normal to find parts of AI challenging?
It is normal to find parts of AI challenging, as even accomplished individuals in the field have faced similar technical challenges at some point.
> Merging 1 nodes into parent node.
> Parent node id: 9b23ddff-b99b-40e9-b303-773555212909.
> Parent node text: PAGE 31Finding the Right
AI Job for YouCHAPTER 9
JOBS
> Merging 1 nodes into parent node.
> Parent node id: ce78543d-97c4-49d7-a122-f235a7e13793.
> Parent node text: If you’re leaving
a job, exit gracefully. Give your employer ample notice, give your full effort...
> Merging 1 nodes into parent node.
> Parent node id: 6bfbb505-dee8-4bd7-9966-1feda40d4fc7.
> Parent node text: PAGE 28Using Informational
Interviews to Find
the Right JobCHAPTER 8
JOBS
> Merging 1 nodes into parent node.
> Parent node id: 0dc3b057-fd18-4e2a-bf8f-9023baaea2cf.
> Parent node text: PAGE 31Finding the Right
AI Job for YouCHAPTER 9
JOBS
> Merging 1 nodes into parent node.
> Parent node id: 11951238-3643-4517-ae08-80759a75ce50.
> Parent node text: PAGE 28Using Informational
Interviews to Find
the Right JobCHAPTER 8
JOBS
What is the right AI job for me?
The right AI job for you would likely depend on whether you are looking to switch roles, industries, or both. If you are seeking your first job in AI, it may be easier to transition by switching either roles or industries rather than attempting to switch both simultaneously.tru.get_leaderboard(app_ids=[])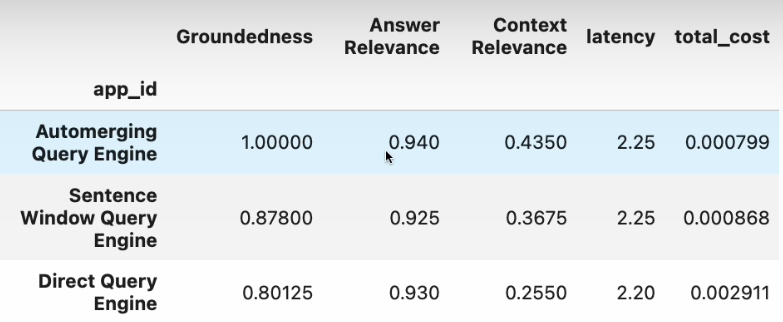
# launches on http://localhost:8501/
tru.run_dashboard()Starting dashboard ...
Config file already exists. Skipping writing process.
Credentials file already exists. Skipping writing process.
Dashboard already running at path: https://s172-31-12-156p53074.lab-aws-production.deeplearning.ai/
<Popen: returncode: None args: ['streamlit', 'run', '--server.headless=True'...>RAG Triad of Metrics
First, we'll learn about the RAG triad of evaluation metrics. These include answer relevance, context relevance, and groundedness. Later, we'll see how to create an evaluation dataset synthetically.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
tru = Tru()
tru.reset_database()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
from llama_index import Document
document = Document(text="\n\n".\
join([doc.text for doc in documents]))
from utils import build_sentence_window_index
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
from utils import get_sentence_window_query_engine
sentence_window_engine = \
get_sentence_window_query_engine(sentence_index)
output = sentence_window_engine.query(
"How do you create your AI portfolio?")
output.response
Feedback functions
A feedback function assigns a score after analyzing an LLM app's inputs, outputs, and intermediate results.
import nest_asyncio
nest_asyncio.apply()
from trulens_eval import OpenAI as fOpenAI
provider = fOpenAI()1. Answer Relevance
Determine whether the final response is related to the query.

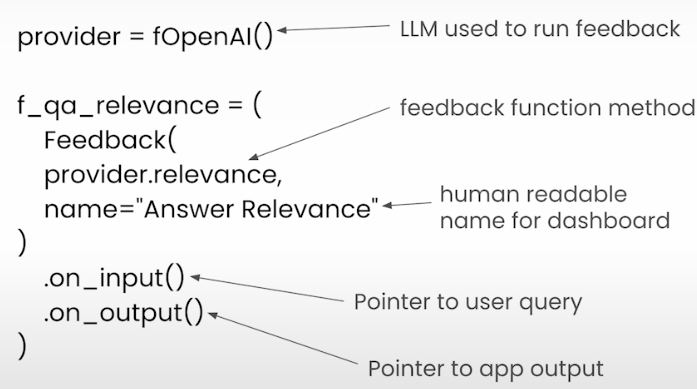
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
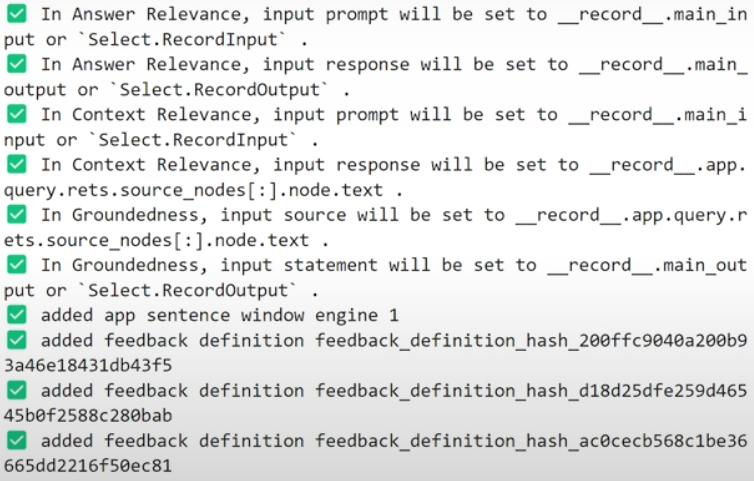
).on_input_output()✅ In Answer Relevance, input prompt will be set to __record__.main_input or `Select.RecordInput` .
✅ In Answer Relevance, input response will be set to __record__.main_output or `Select.RecordOutput` .2. Context Relevance
It evaluates how relevant the answer is to the situation.

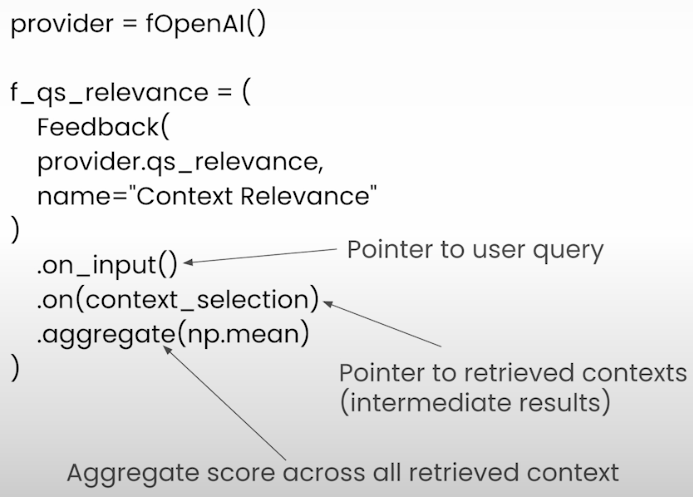
from trulens_eval import TruLlama
context_selection = TruLlama.select_source_nodes().node.text
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)✅ In Context Relevance, input question will be set to __record__.main_input or `Select.RecordInput` .
✅ In Context Relevance, input statement will be set to __record__.app.query.rets.source_nodes[:].node.text .import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons, # qs_relevance_with_cot_reasons for more details
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)✅ In Context Relevance, input question will be set to __record__.main_input or `Select.RecordInput` .
✅ In Context Relevance, input statement will be set to __record__.app.query.rets.source_nodes[:].node.text .3. Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)✅ In Groundedness, input source will be set to __record__.app.query.rets.source_nodes[:].node.text .
✅ In Groundedness, input statement will be set to __record__.main_output or `Select.RecordOutput` .Evaluation of the RAG application
- Start with Llamaindex's basic RAG.
Evaluate using Trulens RAG Triad (failure modes related to context size).
Iterate using Llamaindex Sentence. Window RAG
Reevaluate using the TruLense RAG Triad (Do we detect any improvements? How about other metrics?
Experiment with different window sizes (which window size produces the best evaluation metrics?). - Feedback functions can be implemented in several ways.
from trulens_eval import TruLlama
from trulens_eval import FeedbackMode
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
# Remove newline character and convert to integer
item = line.strip()
eval_questions.append(item)
eval_questions.append("How can I be successful in AI?")
eval_questions['What are the keys to building a career in AI?',
'How can teamwork contribute to success in AI?',
'What is the importance of networking in AI?',
'What are some good habits to develop for a successful career?',
'How can altruism be beneficial in building a career?',
'What is imposter syndrome and how does it relate to AI?',
'Who are some accomplished individuals who have experienced imposter syndrome?',
'What is the first step to becoming good at AI?',
'What are some common challenges in AI?',
'Is it normal to find parts of AI challenging?',
'How can I be successful in AI?']for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
records, feedback = tru.get_records_and_feedback(app_ids=[])
import pandas as pd
pd.set_option("display.max_colwidth", None)
records[["input", "output"] + feedback]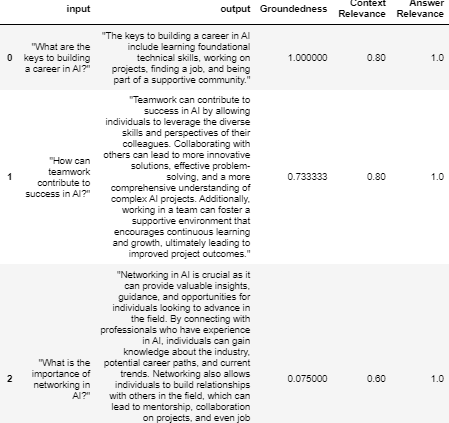
tru.get_leaderboard(app_ids=[])
tru.run_dashboard()
Sentence-Window Retrieval
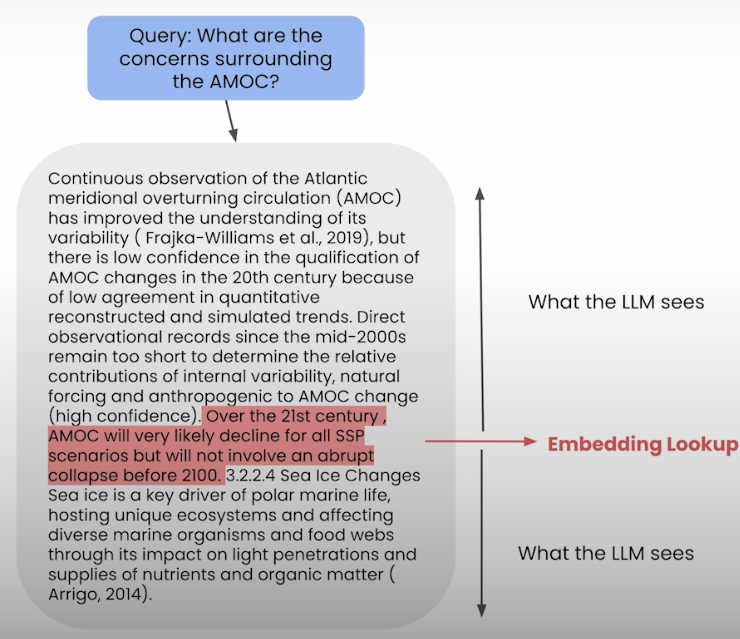
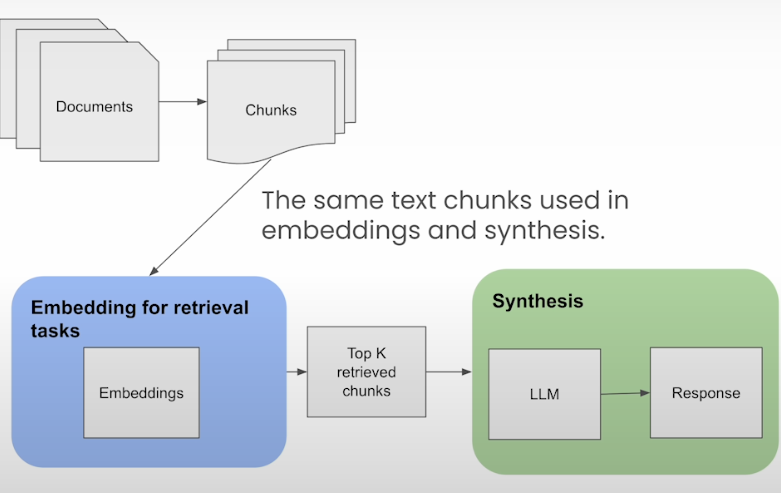
The conventional RAG pipeline applies the same text chunk to both embedding and synthesis. The following graphic depicts a simple RAG process, however embedding-based retrieval is only effective with smaller text chunks. The issue is that embedding-based retrieval often requires more context and larger chunks to generate a satisfactory answer.
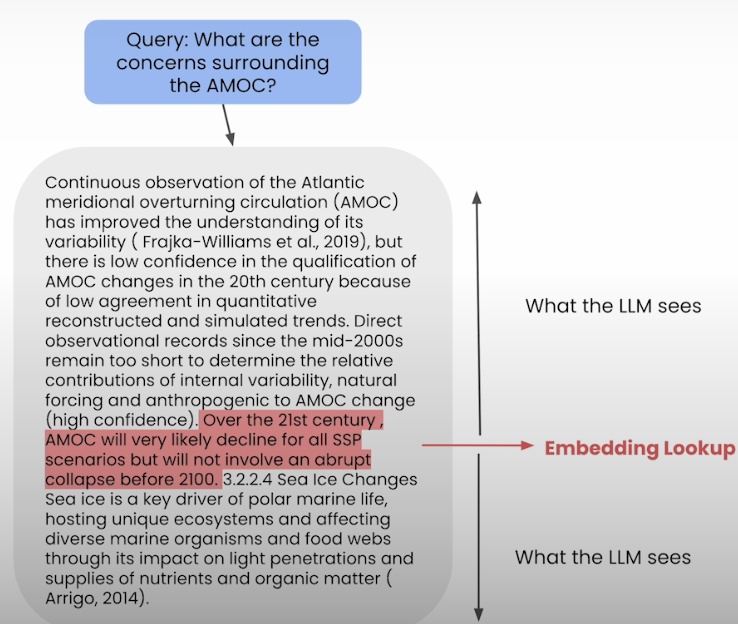
Sentence window retrieval partially decouples the two. We initially incorporate smaller pieces and words into a vector database. We also provide context for the sentences that come before and after each chunk. During retrieval, we use a similarity search to find the sentences that are most relevant to the question, and then replace the sentence with its full context.
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
print(type(documents), "\n")
print(len(documents), "\n")
print(type(documents[0]))
print(documents[0])
from llama_index import Document
document = Document(text="\n\n".join([doc.text for doc in documents]))Window-sentence retrieval setup
from llama_index.node_parser import SentenceWindowNodeParser
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
text = "hello. how are you? I am fine! "
nodes = node_parser.get_nodes_from_documents([Document(text=text)])
print([x.text for x in nodes])
print(nodes[1].metadata["window"])
text = "hello. foo bar. cat dog. mouse"
nodes = node_parser.get_nodes_from_documents([Document(text=text)])
print([x.text for x in nodes])
print(nodes[0].metadata["window"])
Building the index
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
from llama_index import ServiceContext
sentence_context = ServiceContext.from_defaults(
llm=llm,
embed_model="local:BAAI/bge-small-en-v1.5",
# embed_model="local:BAAI/bge-large-en-v1.5"
node_parser=node_parser,
)
from llama_index import VectorStoreIndex
sentence_index = VectorStoreIndex.from_documents(
[document], service_context=sentence_context
)
sentence_index.storage_context.persist(persist_dir="./sentence_index")
# This block of code is optional to check
# if an index file exist, then it will load it
# if not, it will rebuild it
import os
from llama_index import VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index import load_index_from_storage
if not os.path.exists("./sentence_index"):
sentence_index = VectorStoreIndex.from_documents(
[document], service_context=sentence_context
)
sentence_index.storage_context.persist(persist_dir="./sentence_index")
else:
sentence_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="./sentence_index"),
service_context=sentence_context
)
Building the postprocessor
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
from llama_index.schema import NodeWithScore
from copy import deepcopy
scored_nodes = [NodeWithScore(node=x, score=1.0) for x in nodes]
nodes_old = [deepcopy(n) for n in nodes]
nodes_old[1].text # How are you?
replaced_nodes = postproc.postprocess_nodes(scored_nodes)
print(replaced_nodes[1].text) # Hello. How are you? I am fine.Adding a reranker
from llama_index.indices.postprocessor import SentenceTransformerRerank
# BAAI/bge-reranker-base
# link: https://huggingface.co/BAAI/bge-reranker-base
rerank = SentenceTransformerRerank(
top_n=2, model="BAAI/bge-reranker-base"
)
from llama_index import QueryBundle
from llama_index.schema import TextNode, NodeWithScore
query = QueryBundle("I want a dog.")
scored_nodes = [
NodeWithScore(node=TextNode(text="This is a cat"), score=0.6),
NodeWithScore(node=TextNode(text="This is a dog"), score=0.4),
]
reranked_nodes = rerank.postprocess_nodes(
scored_nodes, query_bundle=query
)
print([(x.text, x.score) for x in reranked_nodes])Running the query engine
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=6, node_postprocessors=[postproc, rerank]
)
window_response = sentence_window_engine.query(
"What are the keys to building a career in AI?"
)
from llama_index.response.notebook_utils import display_response
display_response(window_response)
Putting it all Together
import os
from llama_index import ServiceContext, VectorStoreIndex, StorageContext
from llama_index.node_parser import SentenceWindowNodeParser
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index import load_index_from_storage
def build_sentence_window_index(
documents,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
sentence_window_size=3,
save_dir="sentence_index",
):
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=sentence_window_size,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
sentence_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
)
if not os.path.exists(save_dir):
sentence_index = VectorStoreIndex.from_documents(
documents, service_context=sentence_context
)
sentence_index.storage_context.persist(persist_dir=save_dir)
else:
sentence_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=save_dir),
service_context=sentence_context,
)
return sentence_index
def get_sentence_window_query_engine(
sentence_index, similarity_top_k=6, rerank_top_n=2
):
# define postprocessors
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model="BAAI/bge-reranker-base"
)
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank]
)
return sentence_window_engine
from llama_index.llms import OpenAI
index = build_sentence_window_index(
[document],
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
save_dir="./sentence_index",
)
query_engine = get_sentence_window_query_engine(index, similarity_top_k=6)TruLens Evaluation
- Increase the sentence window size gradually, beginning with one.
Use the RAG Triad to evaluate app versions.
Track studies to determine the optimal sentence window size.
Consider the trade-off between token usage/cost and context relevance.
Consider the trade-off between window size and groundness.
When experimenting:
Load several questions.
Try different sentence window sizes (1, 3, 5).
Examine the effects of different window widths on the RAG Triad.
eval_questions = []
with open('generated_questions.text', 'r') as file:
for line in file:
# Remove newline character and convert to integer
item = line.strip()
eval_questions.append(item)
from trulens_eval import Tru
def run_evals(eval_questions, tru_recorder, query_engine):
for question in eval_questions:
with tru_recorder as recording:
response = query_engine.query(question)
from utils import get_prebuilt_trulens_recorder
from trulens_eval import Tru
Tru().reset_database()Sentence window size = 1
sentence_index_1 = build_sentence_window_index(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
embed_model="local:BAAI/bge-small-en-v1.5",
sentence_window_size=1,
save_dir="sentence_index_1",
)
sentence_window_engine_1 = get_sentence_window_query_engine(
sentence_index_1
)
tru_recorder_1 = get_prebuilt_trulens_recorder(
sentence_window_engine_1,
app_id='sentence window engine 1'
)
run_evals(eval_questions, tru_recorder_1, sentence_window_engine_1)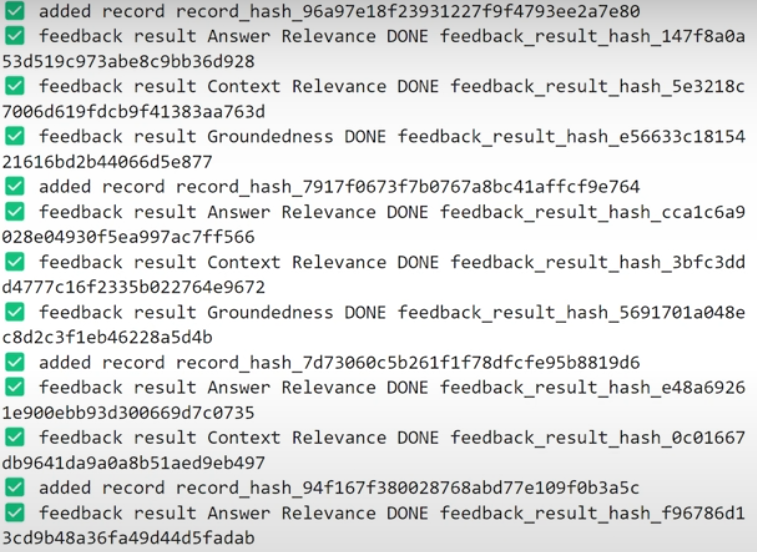
Tru().run_dashboard()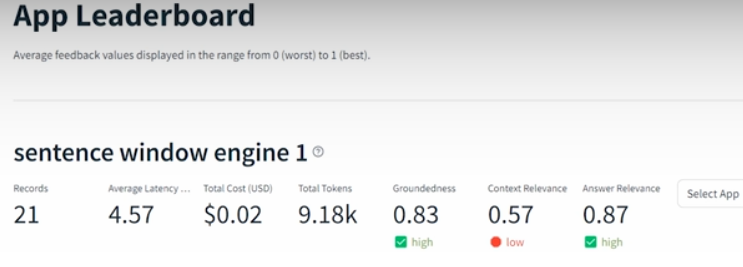
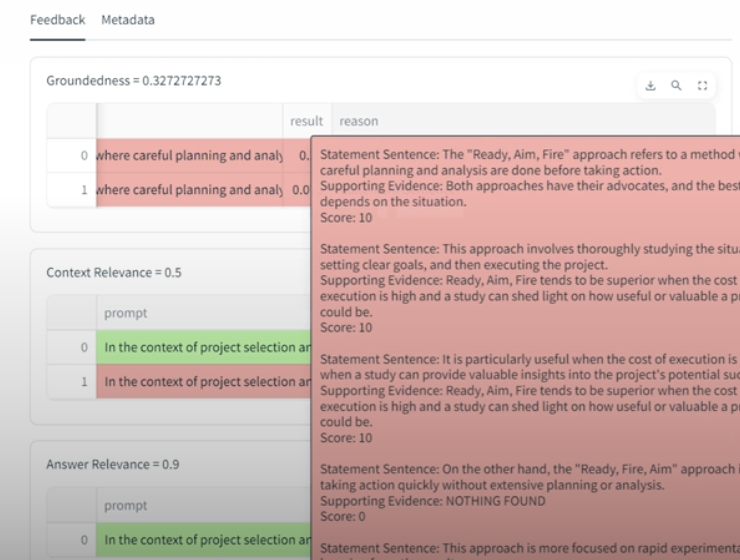
Note about the dataset of questions
- Because this evaluation procedure takes a lengthy time, the generated_questions.text file only contains one question (as described in the lecture video).
If you have any further queries, please explore the file directory by clicking on the "Jupyter" logo in the top right corner of this notebook. You will see the following.Text files: generated_questions_01_05.textgenerated_questions_06_10.textgenerated_questions_11_15.textgenerated_questions_16_20.textgenerated_questions_21_24.text
Running an evaluation on more than one question can take some time, therefore we recommend running only one of these files (each with 5 questions) and exploring the results.
An evaluation set of 20 is appropriate for a personal project.
To properly cover all use cases while evaluating business applications, you may require a collection of 100 or more.
Note that because API requests might occasionally fail, you may receive null replies and should re-run your assessments. Running your evaluations in smaller batches can also help you save time and money by rerunning the evaluation just on the batches that have problems.
eval_questions = []
with open('generated_questions.text', 'r') as file:
for line in file:
# Remove newline character and convert to integer
item = line.strip()
eval_questions.append(item)
Sentence window size = 3
sentence_index_3 = build_sentence_window_index(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
embed_model="local:BAAI/bge-small-en-v1.5",
sentence_window_size=3,
save_dir="sentence_index_3",
)
sentence_window_engine_3 = get_sentence_window_query_engine(
sentence_index_3
)
tru_recorder_3 = get_prebuilt_trulens_recorder(
sentence_window_engine_3,
app_id='sentence window engine 3'
)
run_evals(eval_questions, tru_recorder_3, sentence_window_engine_3)
Tru().run_dashboard()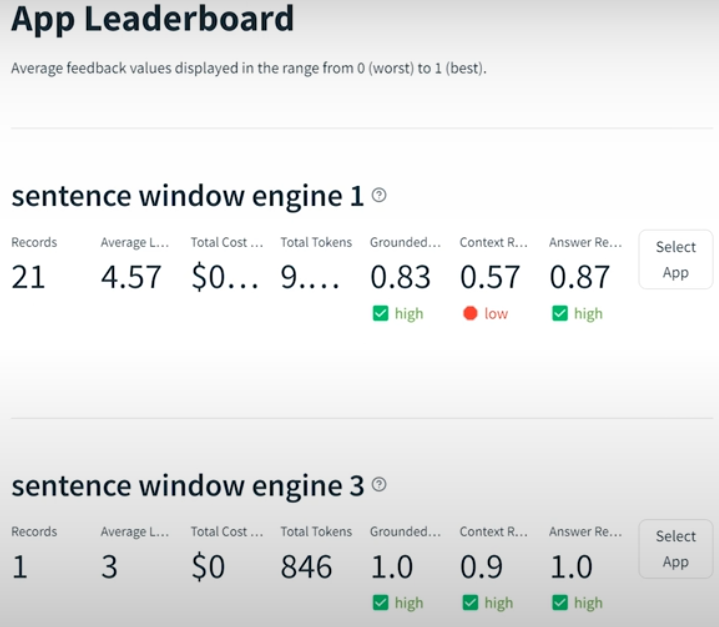
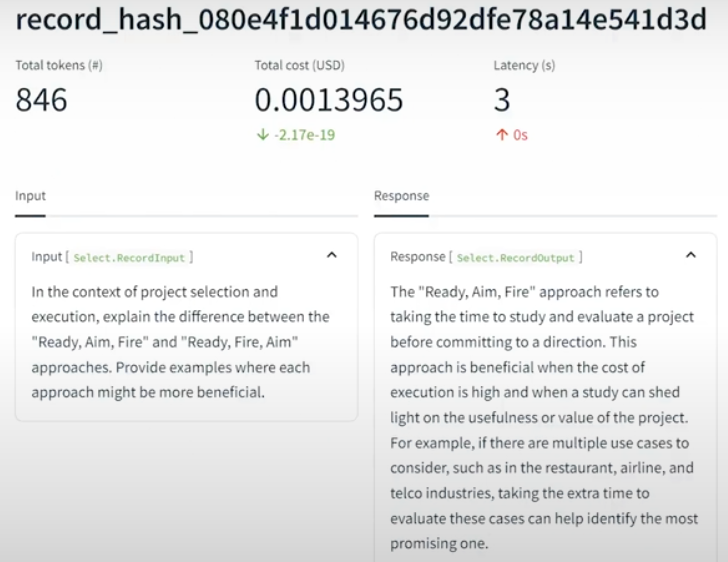
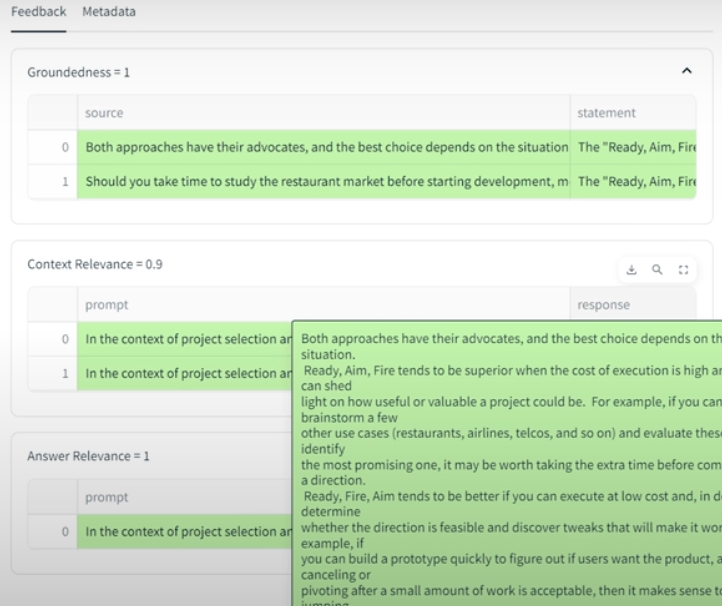
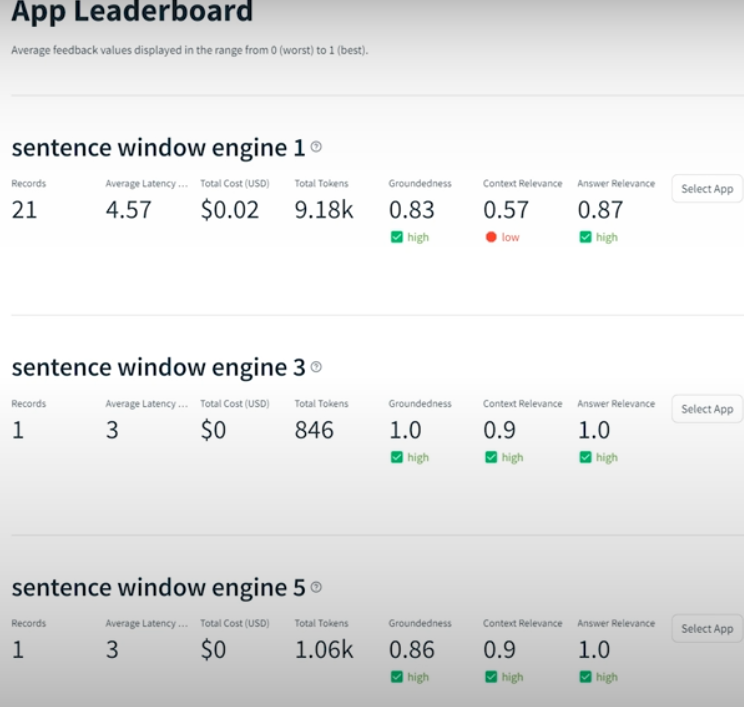
Experiment results with sentence windows 1,3 and 5 comparison:
Auto-Merging Retrieval
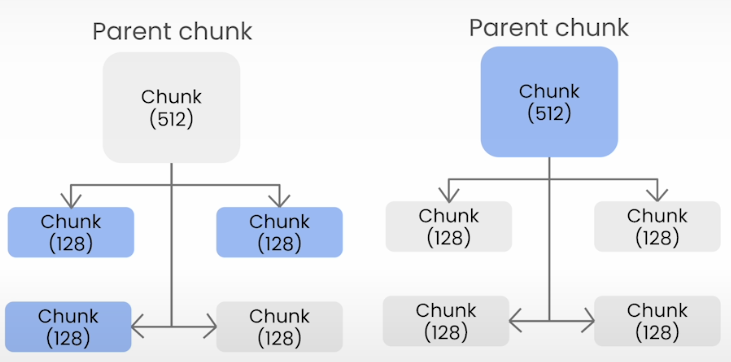
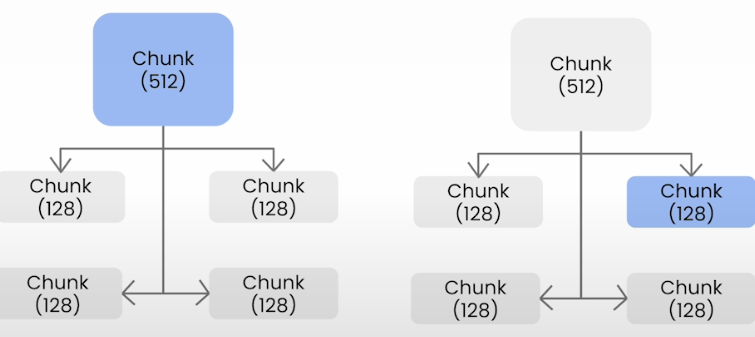
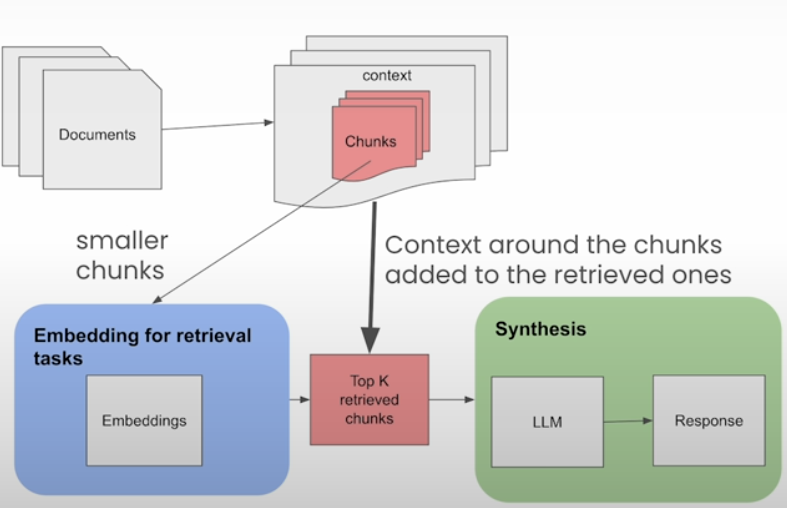
I'm retrieving a bunch of fragmented context chunks to add to the LLM context menu, and the fragmentation becomes worse as the chunk size decreases.
Create a structure of smaller chunks linked to parent chunks. If a collection of smaller chunks linked to parent chunks surpasses a certain threshold, the smaller chunks are "merged" into the larger parent chunk.
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
print(type(documents), "\n")
print(len(documents), "\n")
print(type(documents[0]))
print(documents[0])Auto-merging retrieval setup
from llama_index import Document
document = Document(text="\n\n".join([doc.text for doc in documents]))
from llama_index.node_parser import HierarchicalNodeParser
# create the hierarchical node parser w/ default settings
node_parser = HierarchicalNodeParser.from_defaults(
chunk_sizes=[2048, 512, 128]
)
nodes = node_parser.get_nodes_from_documents([document])
from llama_index.node_parser import get_leaf_nodes
leaf_nodes = get_leaf_nodes(nodes)
print(leaf_nodes[30].text)
nodes_by_id = {node.node_id: node for node in nodes}
parent_node = nodes_by_id[leaf_nodes[30].parent_node.node_id]
print(parent_node.text)
Building the index
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
from llama_index import ServiceContext
auto_merging_context = ServiceContext.from_defaults(
llm=llm,
embed_model="local:BAAI/bge-small-en-v1.5",
node_parser=node_parser,
)
from llama_index import VectorStoreIndex, StorageContext
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
automerging_index = VectorStoreIndex(
leaf_nodes, storage_context=storage_context, service_context=auto_merging_context
)
automerging_index.storage_context.persist(persist_dir="./merging_index")
# This block of code is optional to check
# if an index file exist, then it will load it
# if not, it will rebuild it
import os
from llama_index import VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index import load_index_from_storage
if not os.path.exists("./merging_index"):
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
automerging_index = VectorStoreIndex(
leaf_nodes,
storage_context=storage_context,
service_context=auto_merging_context
)
automerging_index.storage_context.persist(persist_dir="./merging_index")
else:
automerging_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="./merging_index"),
service_context=auto_merging_context
)Defining the retriever and running the query engine
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.retrievers import AutoMergingRetriever
from llama_index.query_engine import RetrieverQueryEngine
automerging_retriever = automerging_index.as_retriever(
similarity_top_k=12
)
retriever = AutoMergingRetriever(
automerging_retriever,
automerging_index.storage_context,
verbose=True
)
rerank = SentenceTransformerRerank(top_n=6, model="BAAI/bge-reranker-base")
auto_merging_engine = RetrieverQueryEngine.from_args(
automerging_retriever, node_postprocessors=[rerank]
)
auto_merging_response = auto_merging_engine.query(
"What is the importance of networking in AI?"
)
from llama_index.response.notebook_utils import display_response
display_response(auto_merging_response)Putting it all Together
import os
from llama_index import (
ServiceContext,
StorageContext,
VectorStoreIndex,
load_index_from_storage,
)
from llama_index.node_parser import HierarchicalNodeParser
from llama_index.node_parser import get_leaf_nodes
from llama_index import StorageContext, load_index_from_storage
from llama_index.retrievers import AutoMergingRetriever
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.query_engine import RetrieverQueryEngine
def build_automerging_index(
documents,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="merging_index",
chunk_sizes=None,
):
chunk_sizes = chunk_sizes or [2048, 512, 128]
node_parser = HierarchicalNodeParser.from_defaults(chunk_sizes=chunk_sizes)
nodes = node_parser.get_nodes_from_documents(documents)
leaf_nodes = get_leaf_nodes(nodes)
merging_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
)
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
if not os.path.exists(save_dir):
automerging_index = VectorStoreIndex(
leaf_nodes, storage_context=storage_context, service_context=merging_context
)
automerging_index.storage_context.persist(persist_dir=save_dir)
else:
automerging_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=save_dir),
service_context=merging_context,
)
return automerging_index
def get_automerging_query_engine(
automerging_index,
similarity_top_k=12,
rerank_top_n=6,
):
base_retriever = automerging_index.as_retriever(similarity_top_k=similarity_top_k)
retriever = AutoMergingRetriever(
base_retriever, automerging_index.storage_context, verbose=True
)
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model="BAAI/bge-reranker-base"
)
auto_merging_engine = RetrieverQueryEngine.from_args(
retriever, node_postprocessors=[rerank]
)
return auto_merging_engine
from llama_index.llms import OpenAI
index = build_automerging_index(
[document],
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
save_dir="./merging_index",
)
query_engine = get_automerging_query_engine(index, similarity_top_k=6)TruLens Evaluation
Auto-emerging is complementary to sentence window retrieval.
from trulens_eval import Tru
Tru().reset_database()Two layers
auto_merging_index_0 = build_automerging_index(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="merging_index_0",
chunk_sizes=[2048,512],
)
auto_merging_engine_0 = get_automerging_query_engine(
auto_merging_index_0,
similarity_top_k=12,
rerank_top_n=6,
)
from utils import get_prebuilt_trulens_recorder
tru_recorder = get_prebuilt_trulens_recorder(
auto_merging_engine_0,
app_id ='app_0'
)
eval_questions = []
with open('generated_questions.text', 'r') as file:
for line in file:
# Remove newline character and convert to integer
item = line.strip()
eval_questions.append(item)
def run_evals(eval_questions, tru_recorder, query_engine):
for question in eval_questions:
with tru_recorder as recording:
response = query_engine.query(question)
run_evals(eval_questions, tru_recorder, auto_merging_engine_0)
from trulens_eval import Tru
Tru().get_leaderboard(app_ids=[])
Tru().run_dashboard()Three layers
auto_merging_index_1 = build_automerging_index(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="merging_index_1",
chunk_sizes=[2048,512,128],
)
auto_merging_engine_1 = get_automerging_query_engine(
auto_merging_index_1,
similarity_top_k=12,
rerank_top_n=6,
)
tru_recorder = get_prebuilt_trulens_recorder(
auto_merging_engine_1,
app_id ='app_1'
)
run_evals(eval_questions, tru_recorder, auto_merging_engine_1)
from trulens_eval import Tru
Tru().get_leaderboard(app_ids=[])
Tru().run_dashboard()Evaluate for:
Honesty includes answer relevance, context relevance, embedding distance, groundedness, BLUE, ROUGE, custom evaluations, and summary quality.
Harmlessness includes PII detection, jailbreaks, toxicity, stereotyping, and bespoke evaluations.
Sentiment, coherence, language mismatch, custom judgments, and conciseness are all useful considerations.
Resource
[1] Deeplearning.ai, (2024), Building and Evaluating Advanced RAG Applications
[https://www.deeplearning.ai/short-courses/building-evaluating-advanced-rag/]










0 Comments