
https://cbarkinozer.medium.com/autogenin-%C3%A7ok-ajanl%C4%B1-konu%C5%9Fma-yap%C4%B1s%C4%B1yla-yeni-nesil-llm-uygulamalar%C4%B1-1695793b5a92
Look at the “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation” paper.

With this paper, Microsoft Research introduced new ideas about multi-agent communication patterns. This is one of the most significant recent papers on autonomous agents.
Abstract
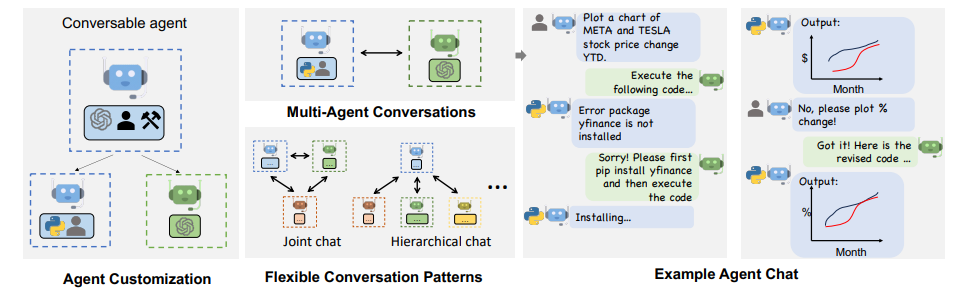
AutoGen is an open-source framework that allows developers to build LLM applications via multiple agents that can converse with each other to accomplish tasks. AutoGen agents are customizable, conversable, and can operate in various modes that employ combinations of LLMs, human inputs, and tools. Using AutoGen, developers can also flexibly define agent interaction behaviours. Both natural language and computer code can be used to program flexible conversation patterns for different applications. AutoGen serves as a generic infrastructure to build diverse applications of various complexities and LLM capacities. Empirical studies demonstrate the effectiveness of the framework in many example applications, with domains ranging from mathematics, coding, question answering, operations research, online decision-making, entertainment, etc.
Summary
- AutoGen is an open-source framework that enables developers to build LLM (large language model) applications via multiple agents that can converse with each other to accomplish tasks.
- AutoGen agents are customizable, conversable, and can operate in various modes that employ combinations of LLMs, human inputs, and tools.
- Developers can flexibly define agent interaction behaviours using natural language or computer code for programming conversation patterns.
- AutoGen serves as a generic framework for building diverse applications of various complexities and LLM capacities.
- Empirical studies demonstrate the effectiveness of the framework in many example applications, with domains ranging from mathematics, coding, question answering, operations research, online decision-making, entertainment, etc.
- Benefits of Multi-Agent Conversations for LLM ApplicationsAuto-Reply Mechanism in AutoGen
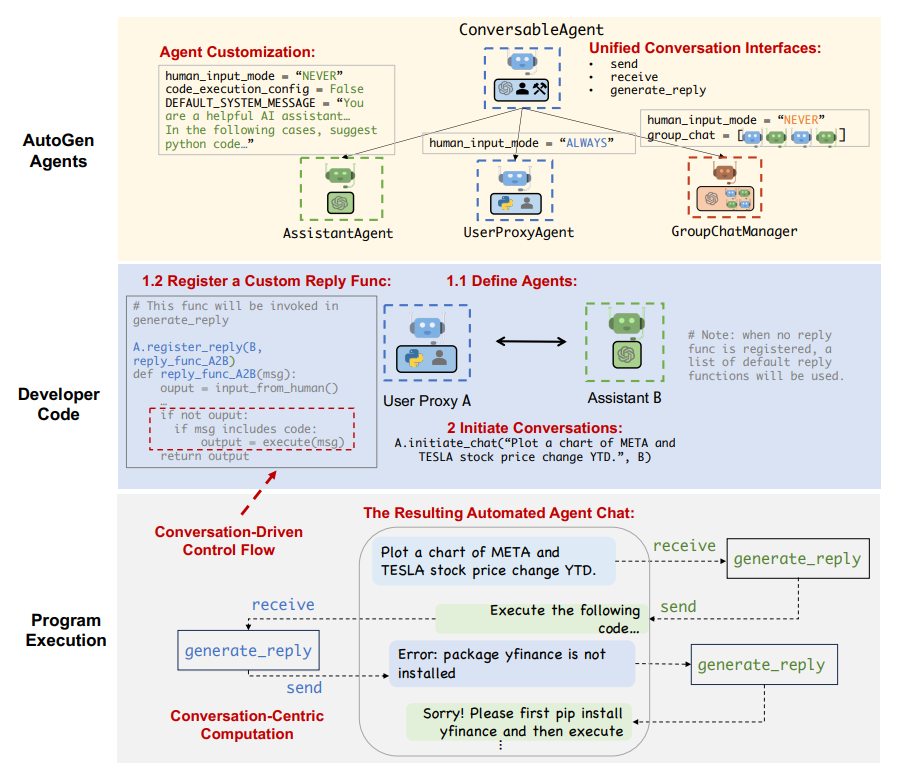
- The auto-reply mechanism in AutoGen is a decentralized, modular, and unified way to define workflow, allowing the conversation to proceed automatically (Eleti et al, 2023).
Control in AutoGen
- AutoGen allows control via programming and natural language, using LLMs (large language models) to control the conversation flow with natural language prompts.
- Programming-language control is also possible in AutoGen, with Python code used to specify termination conditions, human input mode, and tool execution logic.
- AutoGen supports flexible control transition between natural and programming language, with the transition from code to natural-language control achieved via LLM inference and the transition from natural language to code control via LLM-proposed function calls.
Conversation Programming Paradigm
- AutoGen supports multi-agent conversations of diverse patterns, including static conversation with predefined flow and dynamic conversation flows with multiple agents.
- Customized generate reply function and function calls are used to achieve dynamic conversation flows, with AutoGen also supporting more complex dynamic group chat via built-in GroupChatManager.
Applications of AutoGen
- AutoGen has been used to develop high-performance multi-agent applications, including math problem solving, retrieval-augmented code generation and question answering, decision-making in real-world environments, and multi-agent coding.
Math Problem Solving with AutoGen
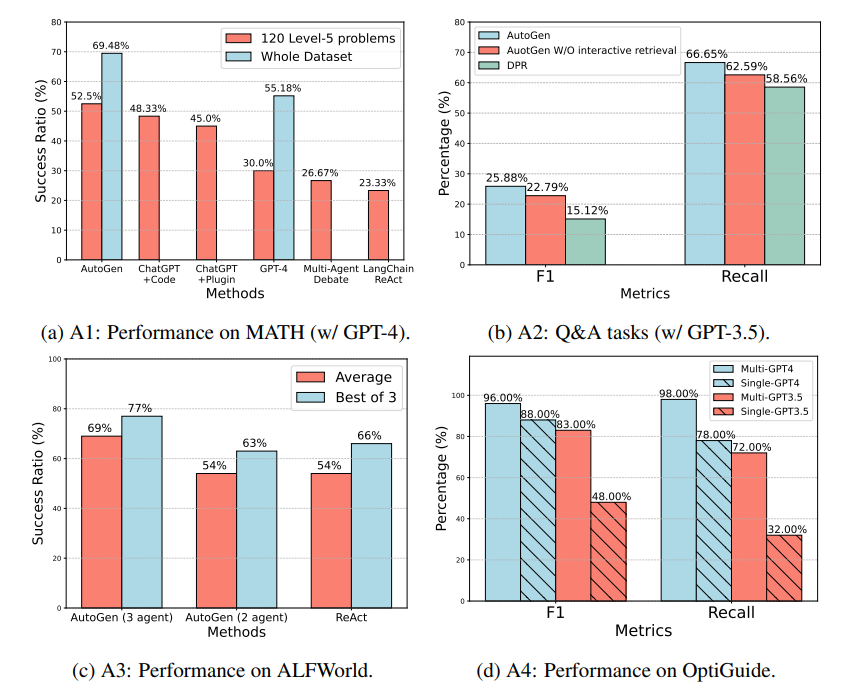
- AutoGen has been used to build a system for autonomous math problem solving, with built-in agents yielding better performance compared to alternative approaches, including open-source methods and commercial products.
- AutoGen has also been used to demonstrate a human-in-the-loop problem-solving process, with the system effectively incorporating human inputs to solve challenging problems that cannot be solved without humans.
Retrieval-Augmented Code Generation and Question Answering
- AutoGen has been used to build a Retrieval-Augmented Generation (RAG) system named Retrieval-augmented Chat, which consists of a Retrieval-augmented User Proxy agent and a Retrieval-augmented Assistant agent.
- Retrieval-augmented Chat has been evaluated in both question-answering and code-generation scenarios, with the interactive retrieval mechanism playing a non-trivial role in the process.
Decision-Making in Text World Environments
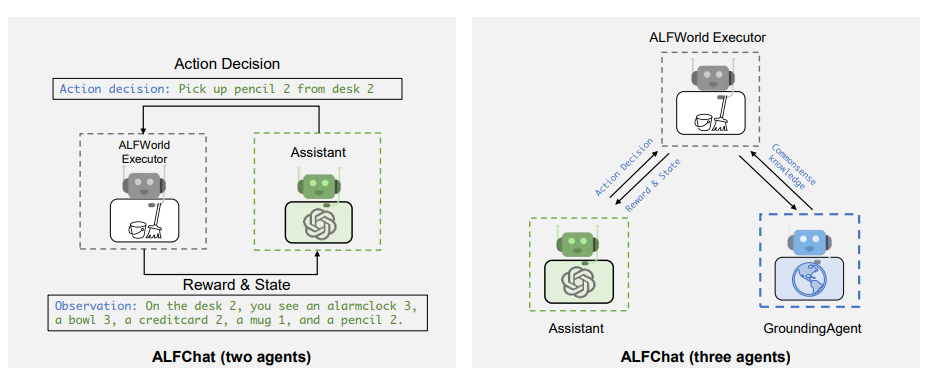
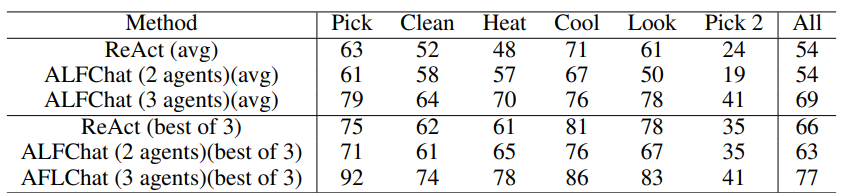
- AutoGen has been used to develop effective applications that involve interactive or online decision-making, with a two-agent system implemented to solve tasks from the ALFWorld benchmark.
- A grounding agent has been introduced to supply crucial commonsense knowledge, significantly enhancing the system’s ability to avoid getting entangled in error loops.
Multi-Agent Coding
- AutoGen has been used to build a multi-agent coding system based on OptiGuide, with the core workflow code reduced from over 430 lines to 100 lines, leading to significant productivity improvement.
- The multi-agent design has been shown to boost the F-1 score in identifying unsafe code by 8% and 35%.
Role-play Prompts in Task Consideration
- In a pilot study of 12 manually crafted complex tasks, utilizing a role-play prompt led to more effective consideration of conversation context and role alignment, resulting in a higher success rate and fewer LLM calls (Hong et al, 2023).
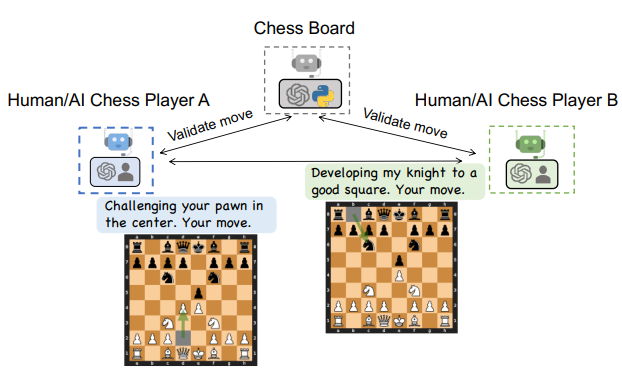
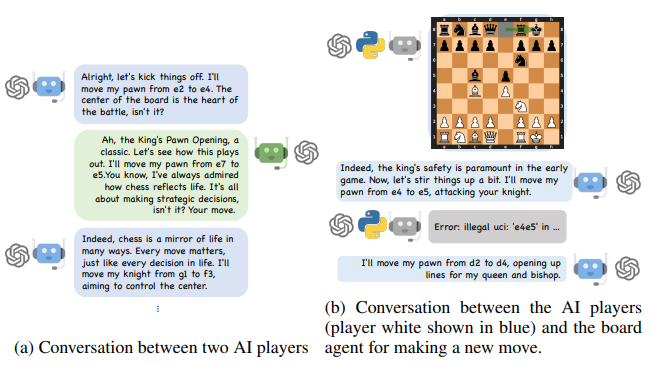
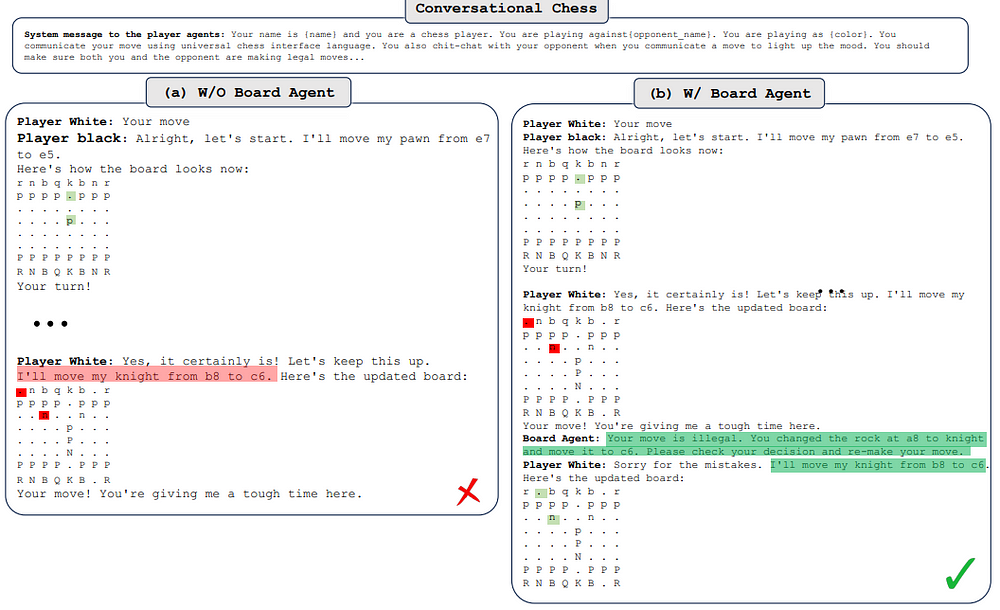
Conversational Chess Using AutoGen
- Conversational Chess is a natural language interface game featuring built-in agents for players and a board agent to provide information and validate moves based on standard rules.
- AutoGen enables two essential features in Conversational Chess: natural, flexible, and engaging game dynamics, and grounding to maintain game integrity by checking each proposed move for legality.
AutoGen: A Unified Conversation Interface
- AutoGen is an open-source library that incorporates the paradigms of conversable agents and conversation programming, utilizing capable agents well-suited for multi-agent cooperation.
- It features a unified conversation interface among the agents, along with auto-reply mechanisms, which help establish an agent-interaction interface that capitalizes on the strengths of chat-optimized LLMs with broad capabilities while accommodating a wide range of applications.
Recommendations for Using Agents in AutoGen
- Consider using built-in agents first, such as AssistantAgent and UserProxyAgent, and customize them based on human input mode, termination condition, code execution configuration, and LLM configuration.
- Start with a simple conversation topology, such as the two-agent chat or group chat setup, and try to reuse built-in reply methods based on LLM, tool, or human before implementing a custom reply method.
- When developing a new application with UserProxyAgent, start with humans always in the loop, and consider using other libraries/packages when necessary for specific applications or tasks.
Future Work
- Designing optimal multi-agent workflows, creating highly capable agents, and enabling scale, safety, and human agency are important research directions for AutoGen.
- Building fail-safes against cascading failures, mitigating reward hacking, out-of-control and undesired behaviours, maintaining effective human oversight, and understanding the appropriate level and pattern of human involvement are crucial for the safe and ethical use of AutoGen agents.
Instructions for Solving Tasks
- Follow the language skill or code-based approach to solve tasks, depending on the requirement.
- If using code, provide the full code instead of partial code or code changes.
- Include the script type in the code block and use the ‘print’ function for the output.
- Check the execution result and fix any errors before re-outputting the code.
- Analyze the problem and revisit assumptions if the task is not solved even after the code is executed successfully.
- Include verifiable evidence in the response if possible.
- Reply “TERMINATE” in the end when everything is done.
Evaluation of Math Problem-Solving Systems
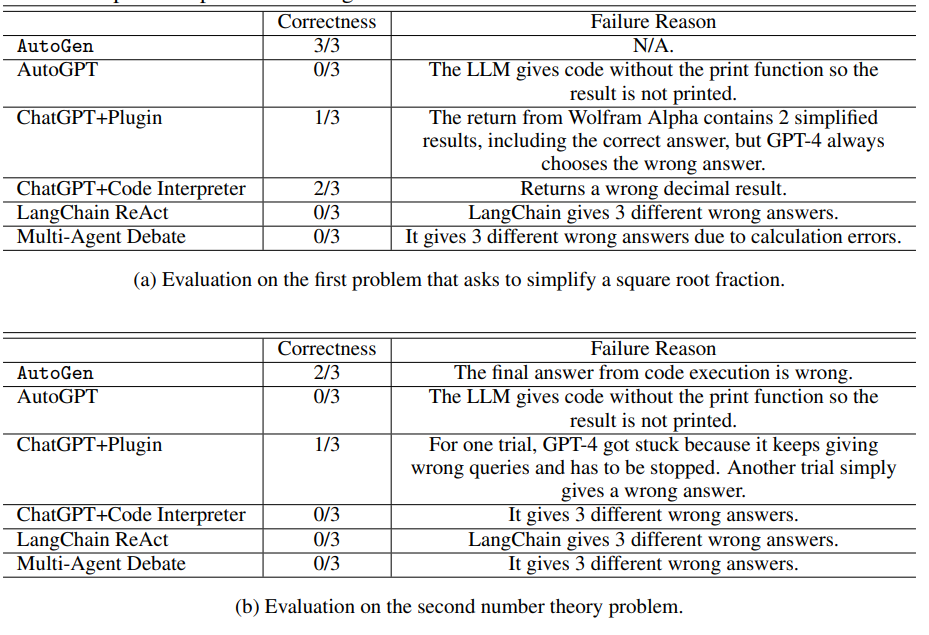
- AutoGen achieves the highest problem-solving success rate among the compared methods.
- ChatGPT+Code Interpreter and ChatGPT+Plugin struggle to solve certain problems.
- AutoGPT fails on problems due to code execution issues.
- LangChain agent fails on problems, producing incorrect answers in all trials.
Human-in-the-loop Problem Solving
- AutoGen consistently solved the problem across all three trials.
- ChatGPT+Code Interpreter and ChatGPT+Plugin managed to solve the problem in two out of three trials.
- AutoGPT was unable to yield a correct solution in any of the trials.
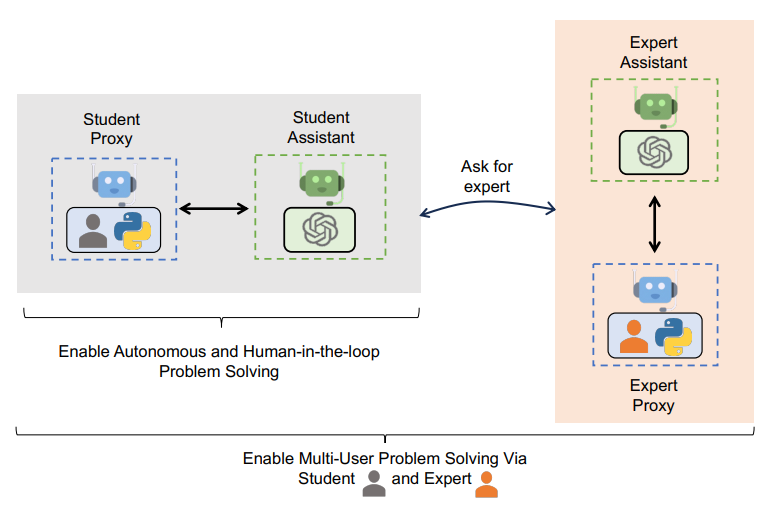
Multi-User Problem Solving
- AutoGen can be used to construct a system involving multiple real users for collectively solving a problem with the assistance of LLMs.
- A student interacts with an LLM assistant to address problems, and the LLM automatically resorts to the expert when necessary.
- The expert is supposed to respond to the problem statement or the request to verify the solution to a problem.
- After the conversation between the expert and the expert’s assistant, the final message is sent back to the student assistant as the response to the initial message.
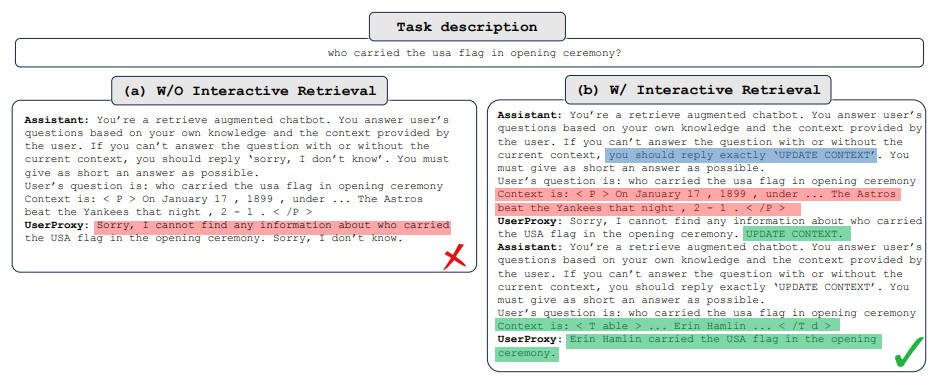
Retrieval-Augmented Chat Workflow
- The Retrieval-Augmented User Proxy retrieves document chunks based on the embedding similarity and sends them along with the question to the Retrieval-Augmented Assistant.
- The Retrieval-Augmented Assistant generates code or text as answers based on the question and context provided.
- If the LLM is unable to produce a satisfactory response, it replies with “Update Context” to the Retrieval-Augmented User Proxy.
- If the response includes code blocks, the Retrieval-Augmented User Proxy executes the code and sends the output as feedback.
- If human input solicitation is enabled, individuals can proactively send any feedback, including “Update Context”, to the Retrieval-Augmented Assistant.
Limitations of Math Problem-Solving Systems
- BabyAGI, CAMEL, and MetaGPT are not suitable choices for solving math problems out of the box.
- MetaGPT begins developing software to address the problem but most of the time, it does not solve the problem.
- The LLM gives code without the print function so the result is not printed.
- The return from Wolfram Alpha contains 2 simplified results, including the correct answer, but GPT-4 always chooses the wrong answer.
- LangChain gives 3 different wrong answers due to calculation errors.
Scenario 1: Evaluation of Natural Questions QA Dataset
- Retrieval-Augmented Chat’s end-to-end question-answering performance is evaluated using the Natural Questions dataset (Kwiatkowski et al, 2019).
- 5,332 non-redundant context documents and 6,775 queries are collected from HuggingFace.
- A document collection is created based on the entire context corpus and stored in the vector database.
- The system utilizes Retrieval-Augmented Chat to answer the questions.
- The advantages of the interactive retrieval feature are demonstrated through an example from the NQ dataset.
- The LLM assistant (GPT-3.5-turbo) replies “Sorry, I cannot find any information about who carried the USA flag in the opening ceremony.
- UPDATE CONTEXT.” when it can’t answer the question.
- The agent can generate the correct answer to the question after the context is updated.
- An experiment is conducted using the same prompt as illustrated in (Adlakha et al, 2023) to investigate the advantages of AutoGen W/O interactive retrieval.
- The F1 score and Recall for the first 500 questions are 23.40% and 62.60%, respectively.
- Approximately 19.4% of questions in the Natural Questions dataset trigger an “Update Context” operation, resulting in additional LLM calls.
Scenario 2: Code Generation Leveraging Latest APIs from the Codebase
- The question is “How can I use FLAML to perform a classification task and use Spark for parallel training? Train for 30 seconds and force cancel jobs if the time limit is reached.”.
- The original GPT-4 model is unable to generate the correct code due to its lack of knowledge regarding Spark-related APIs.
- With Retrieval-Augmented Chat, the latest reference documents are provided as context.
- GPT-4 generates the correct code blocks by setting use spark and force cancel to True.
Observation: ALFWorld (Shridhar et al, 2021)
- ALFWorld is a synthetic language-based interactive decision-making task that simulates real-world household scenes.
- The agent needs to extract patterns from the few-shot examples provided and combine them with the agent’s general knowledge of household environments to fully understand task rules.
Figures















0 Comments