
https://cbarkinozer.medium.com/devasa-apilerle-ba%C4%9Flant%C4%B1l%C4%B1-b%C3%BCy%C3%BCk-dil-modeli-gorilla-llm-4a2deb84ef37
Let's review the “Gorilla: Large Language Model Connected with Massive APIs” article.

This paper challenges traditional RAG concepts and shows that fine-tuning models in API datasets can yield incredible results. Other articles in this area, such as ToolLLM, are also very influential and should be examined.
Abstract
Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety of tasks, such as mathematical reasoning and program synthesis. However, their potential to effectively use tools via API calls remains unfulfilled. This is a challenging task even for today’s state-of-the-art LLMs such as GPT-4, largely due to their inability to generate accurate input arguments and their tendency to hallucinate the wrong usage of an API call. We release Gorilla, a finetuned LLaMA-based model that surpasses the performance of GPT-4 on writing API calls. When combined with a document retriever, Gorilla demonstrates a strong capability to adapt to test-time document changes, enabling flexible user updates or version changes. It also substantially mitigates the issue of hallucination, commonly encountered when prompting LLMs directly. To evaluate the model’s ability, we introduce APIBench, a comprehensive dataset consisting of HuggingFace, TorchHub, and TensorHub APIs. The successful integration of the retrieval system with Gorilla demonstrates the potential for LLMs to use tools more accurately, keep up with frequently updated documentation, and consequently increase the reliability and applicability of their outputs. Gorilla’s code, model, data, and demo are available at https://gorilla.cs.berkeley.edu.
Summary
Important Points
- We construct, APIBench, a large corpus of APIs with complex and often overlapping functionality by scraping ML APIs (models) from public model hubs.
- We also generate 10 synthetic user question prompts per API using Self-Instruct [42]. Thus, each entry in the dataset becomes an instruction reference API pair.
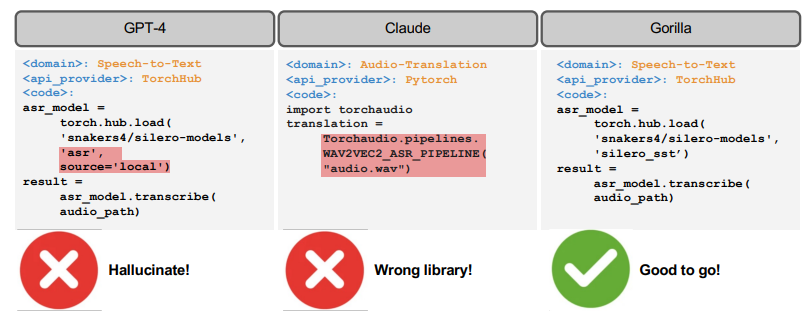
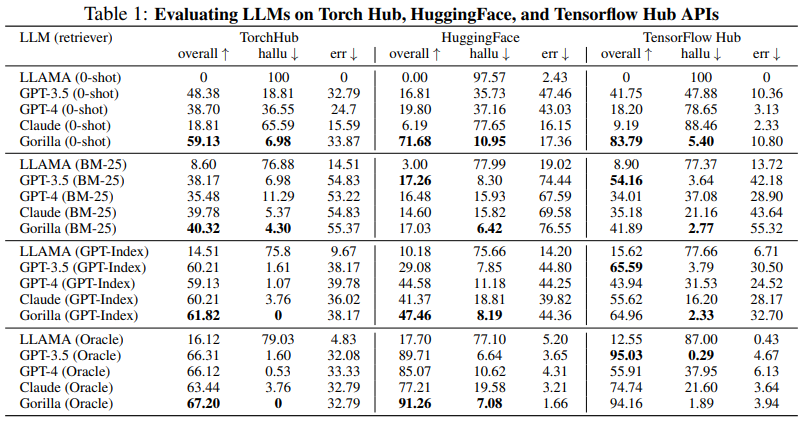
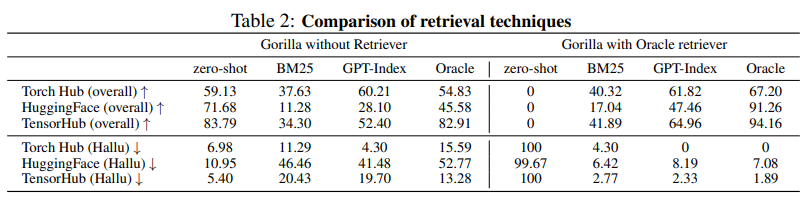
- We then finetune Gorilla, a LLaMA-7B-based model with document retrieval using our dataset. We find that Gorilla significantly outperforms GPT-4 in terms of API functionality accuracy as well as reducing hallucination errors.
- Finally, we demonstrate Gorilla’s ability to understand and reason about constraints by present our AST tree matching evaluation metric.
- Researchers have proposed an array of strategies to prompt LLMs to perform better in coding tasks, including in-context learning, task decomposition, and self-debugging. Besides prompting, there have also been efforts to pretrain language models specifically for code generation.
- Guided by the self-instruct paradigm, we employed GPT-4 to generate synthetic instruction data. We provided three in-context examples, along with a reference API documentation, and tasked the model with generating real-world use cases that call upon the API. We specifically instructed the model to refrain from using any API names or hints when creating instructions.
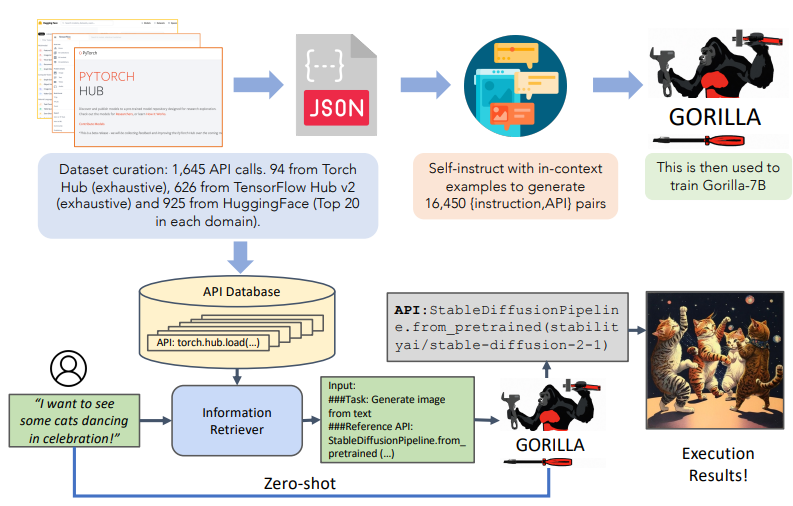
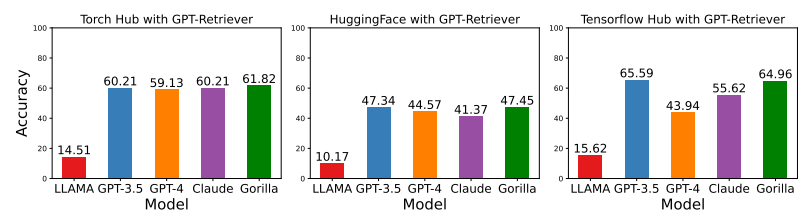
- Our model Gorilla, is retrieve-aware finetuned LLaMA-7B model, specifically for API calls. As shown in Fig 3, we employ self-instruct to generate {instruction, API} pairs. To fine-tune LLaMA, we convert this to a user-agent chat-style conversation, where each data-point is a conversation with one round each for the user and the agent. We then perform standard instruction finetuning on the base LLaMA-7B model. For our experiments, we train Gorilla with and without the retriever.
- For training with retriever, the instruction-tuned dataset, also has an ad-
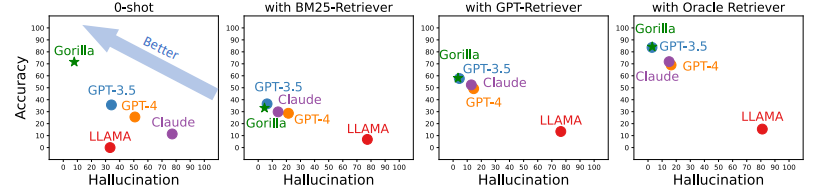
ditional “Use this API documentation for reference: <retrieved_API_doc_JSON>” appended to the user prompt. Through this, we aim to teach the LLM to parse the second half of the question to answer the first half. We demonstrate that this a) makes the LLM adapt to test-time changes in API documentation, and b) improves performance from in-context learning, and finally c) show that it reduces hallucination error. Surprisingly, we find that augmenting a LLM with retrieval, does not always lead to improved performance, and can at-times hurt performance. - Gorilla Inference During Inference, the user provides the prompt in natural language. This can be for a simple task (e.g, “I would like to identify the objects in an image”), or they can specify a vague goal, (.e.g, “I am going to the zoo, and would like to track animals”). Gorilla, similar to training, can be used for inference in two modes: zero-shot and with retrieval. In zero-shot, this prompt (with NO further prompt tuning) is fed to the Gorilla LLM model when then returns the API call that will help in accomplishing the task and/or goal. In retrieval mode, the retriever (either of BM25 or GPT-Index) first retrieves the most up-to-date API documentation stored in the API Database. This is then concatenated to the user prompt along with the message Use this API documentation for reference: before feeding it to Gorilla. The output of Gorilla is an API to be invoked. Besides the concatenation as described, we do NO further prompt tuning in our system. While we do have a system to execute these APIs, that is not a focus of this paper.
Advances in Large Language Models (LLMs)
- • Recent advances in LLMs have enabled significant new capabilities, including natural dialogue, mathematical reasoning, and program synthesis [10, 5, 32, 6, 29, 30].
- • Despite these advances, LLMs are still fundamentally limited by the information they can store in a fixed set of weights and the things they can compute using a static computation graph and limited context.
- • By empowering LLMs to use tools, we can grant access to vastly larger and changing knowledge bases and accomplish complex computational tasks [33, 26, 39, 37, 2].
Challenges in LLMs’ Tool Usage
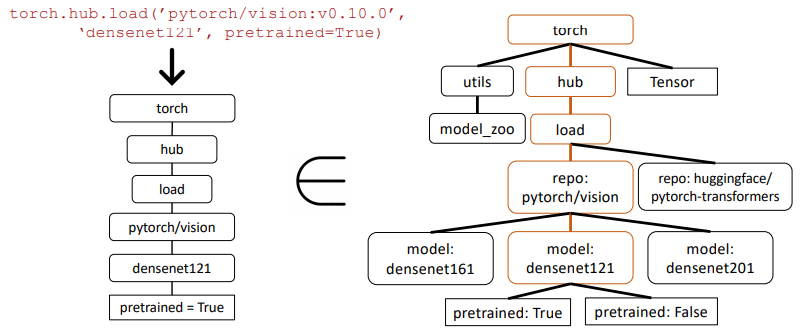
- • Large-scale integration of tools into LLMs requires rethinking the approach to how we integrate tools, as it is not possible to describe the full set of APIs in a single context [35, 24].
- • Many of the APIs will have overlapping functionality with nuanced limitations and constraints.
- • Simply evaluating LLMs in this new setting requires new benchmarks.
APIBench: A Comprehensive Dataset for Evaluating LLMs
- • APIBench is a large corpus of APIs with complex and often overlapping functionality, constructed by scraping ML APIs from public model hubs, including TorchHub, TensorHub, and HuggingFace [42].
- • The dataset includes 94 API calls from TorchHub, 696 API calls from TensorHub, and the most downloaded 20 models per task category from HuggingFace.
- • Each entry in the dataset becomes an instruction reference API pair, with 10 synthetic user question prompts per API generated using Self-Instruct [42].
Gorilla: A LLaMA-7B-based Model with Document Retrieval
- • Gorilla, a LLaMA-7B-based model with document retrieval, significantly outperforms GPT-4 in terms of API functionality accuracy and reducing hallucination errors [42].
- • The retrieval-aware training of Gorilla enables the model to adapt to changes in the API documentation.
Evaluation and Training of LLMs with API Calls
- • Prior works have primarily aimed at showcasing the potential of “prompting” LLMs rather than establishing a systematic method for evaluation and training [35, 24, 41, 1].
- • The focus of the paper is on systematic evaluation and building a pipeline for future use.
Fine-tuning LLMs for Tool Usage and Program Synthesis
- • Gorilla emphasizes enhancing the LLMs’ ability to utilize millions of tools, as opposed to refining their conversational skills [40, 38, 9].
- • The paper pioneers the study of fine-tuning a base model by supplementing it with information retrieval.
- • Researchers have proposed various strategies to prompt LLMs for better performance in coding tasks, including in-context learning, task decomposition, and self-debugging [44, 18, 7, 17, 46, 8, 36].
- • Previous efforts generally focus on specific tools or specific domains, while the paper aims to explore a vast array of tools (i.e., API calls) in an open-ended fashion.
Nuanced Understanding and Challenges for LLMs in API Calls
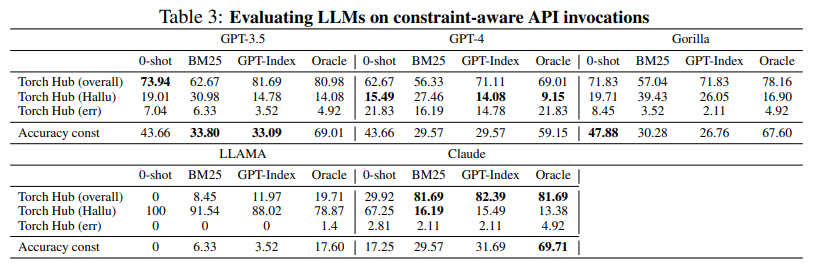
- • LLMs need a nuanced understanding of machine learning API calls, with constraints like parameter size and lower bounds on accuracy.
- • An example prompt, “Invoke an image classification model that uses less than 10M parameters, but maintains an ImageNet accuracy of at least 70%”, highlights the challenge of interpreting and responding accurately.
Retriever-Aware Training for APIs
- • Fine-tuning an LLM for APIs is necessary due to the complex constraints accompanying API calls.
- • Retriever-Aware training involves appending API documentation to the user prompt, teaching the LLM to parse the second half to answer the first half.
- • This method improves performance from in-context learning, adapts to test-time changes in API documentation, and reduces hallucination errors.
Adaptability of Gorilla to Test-Time Changes in API Documentation
- • Gorilla can adapt to test-time changes in API documentation, which helps it maintain accuracy and relevance over time.
- • It can adjust to shifts in API sources, which is important as organizations may change their preferred model registries.
- • This adaptability makes Gorilla a robust and reliable tool for API calls, significantly enhancing its practical utility.
Understanding and Respecting Constraints
- • Gorilla can understand and respect constraints such as accuracy, number of learnable parameters, size on disk, peak memory consumption, FLOPS, etc.
- • It can identify the appropriate API for a given task based on these constraints, such as cost and latency.
- • Gorilla outperforms the best-performing model GPT-3.5 when using retrievals and has the highest accuracy in the Zero-shot case.
Gorilla’s Ability to Navigate APIs
- • Gorilla can navigate APIs while considering the trade-offs between different constraints.
- • This ability is significant for large language models (LLMs) as they interact with tools in the wider world.
Introduction of Gorilla
- • Gorilla is a new novel pipeline for finetuning LLMs to call APIs.
- • The finetuned model’s performance surpasses prompting the state-of-the-art LLM (GPT-4) in three massive datasets.
- • Gorilla generates reliable API calls to ML models without hallucination and can satisfy constraints while picking APIs.
- Addressing Potential Downsides of ML APIs
- • The research releases an extensive dataset of over 11,000 instruction-API pairs to foster a deeper understanding of these APIs.
- • This resource will serve the wider community as a valuable tool for studying and benchmarking existing APIs, contributing to a more fair and optimized usage of machine learning.
Dataset Details
- • The dataset comprises three distinct domains: Torch Hub, Tensor Hub, and HuggingFace.
- • Each entry within this dataset is rich in detail, carrying critical pieces of information that further illuminate the nature of the data.
- • With each API, a set of 10 unique instructions is generated to ensure comprehensive understanding and effective utilization.
Conclusion
LLMs are swiftly gaining popularity across diverse domains. In our study, we spotlight techniques designed to enhance the LLM’s ability to accurately identify the appropriate API for a specific task — a significant but often overlooked aspect in the advancement of this technology. Since APIs function as a universal language enabling diverse systems to communicate effectively, their correct usage can boost the ability of LLMs to interact with tools in the wider world. In this paper, we propose Gorilla, a new novel pipeline for finetuning LLMs to call APIs. The fine-tuned model’s performance surpasses prompting the state-of-the-art LLM (GPT-4) in three massive datasets we collected. Gorilla generates reliable API calls to ML models without hallucination, demonstrates an impressive capability to adapt to test-time API usage changes, and can satisfy constraints while picking APIs.
Figures


Resource
Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety…arxiv.org










0 Comments