
https://medium.com/@cbarkinozer/toolformer-ile-ara%C3%A7-kullanmay%C4%B1-%C3%B6%C4%9Frenen-dil-modelleri-3fce4807bd9f
“Toolformer: Language Models Can Teach Themselves to Use Tools” paper’s summary.
Abstract
Language models (LMs) exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpler and smaller models excel. In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds. We introduce Toolformer, a model trained to decide which APIs to call when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate various tools, including a calculator, a Q&A system, a search engine, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modelling abilities.
Summary
- Language models (LMs) can teach themselves to use external tools via simple APIs
- Toolformer is a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction
- Toolformer incorporates a range of tools, including a calculator, a Q&A system, a search engine, a translation system, and a calendar
- Toolformer achieves improved zero-shot performance across various downstream tasks without sacrificing its core language modelling abilities
Limitations of Current Language Models
- Current language models have limitations in accessing up-to-date information, a tendency to hallucinate facts, difficulties in understanding low-resource languages, a lack of mathematical skills, and unawareness of the progression of time
Proposed Solution: Toolformer
- Toolformer is a model that learns to use tools in a self-supervised way without requiring large amounts of human annotations
- Toolformer allows the LM to decide for itself when and how to use which tool, enabling a more comprehensive use of tools not tied to specific tasks
Methodology
- Toolformer uses large LMs with in-context learning to generate datasets with potential API calls
- A self-supervised loss is used to determine which API calls help predict future tokens
- The LM is finetuned on the useful API calls
Results
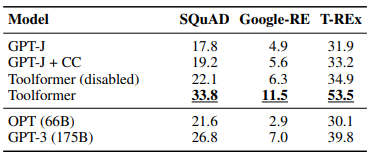
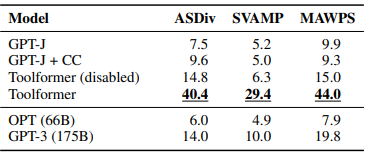
- Toolformer achieves stronger zero-shot results compared to larger models on various tasks
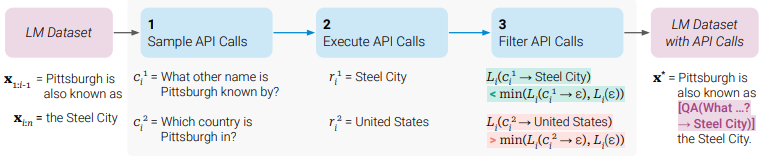
API Call Integration
- API calls are inserted into text sequences using special tokens to mark the start and end of each call
- The dataset is converted into an augmented dataset with API calls through sampling, executing, and filtering API calls
- The LM is finetuned on the augmented dataset, allowing it to use different tools using API calls
Tools for addressing different shortcomings of regular LMs:
- Question-answering system based on Atlas (Izacard et al, 2022)
- Calculator for simple numeric calculations
- Search engine that returns text snippets from Wikipedia
- Machine translation system for translating phrases into English
- Calendar API that returns the current date
Testing the model’s ability to use tools:
- Selected downstream tasks where at least one tool is useful
- Evaluated performance in zero-shot settings
- Verified that tool use does not hurt core language modelling abilities
- Investigated how model size affects the ability to learn using tools
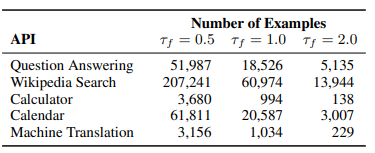
Dataset generation:
- Used a subset of CCNet as the language modelling dataset
- Defined heuristics to filter texts for which API calls are more likely to be helpful
Model finetuning:
- Finetuned the language model on the augmented dataset with API calls
- Used GPT-J as the baseline model without tool use
- Evaluated performance on various downstream tasks
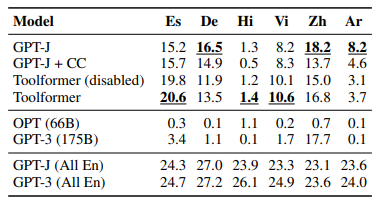
- The EuroParl corpus is included in the evaluation of models (Koehn, 2005; Gao et al, 2020).
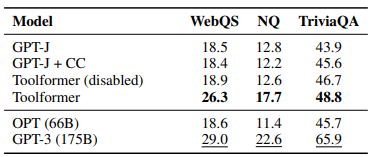
- GPT-3 performs better than other models on a variant of MLQA where both context and question are provided in English.
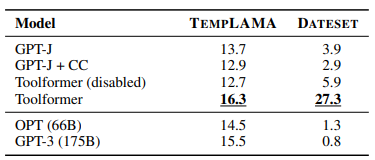
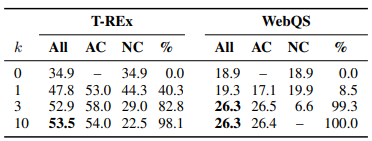
- Toolformer outperforms all baselines on TEMPLAMA and DATESET datasets.
- Improvements in TEMPLAMA are mostly attributed to Wikipedia search and question-answering tools, not the calendar tool.
- Toolformer makes use of the calendar tool for 54.8% of examples in DATESET.
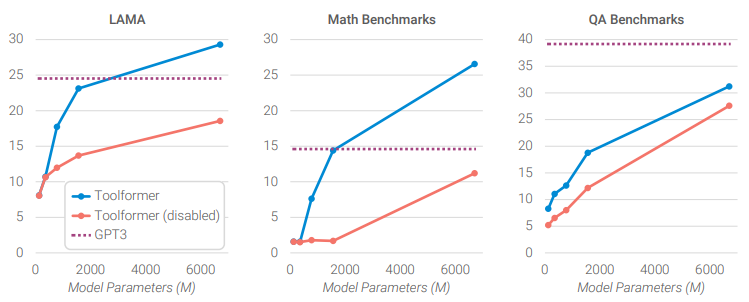
- Toolformer’s language modelling performance does not degrade through finetuning with API calls.
- The ability to leverage provided tools emerges at around 775M parameters for GPT-J and smaller models achieve similar performance with or without tools.
- The modified decoding strategy leads to more API calls as the value of k increases.
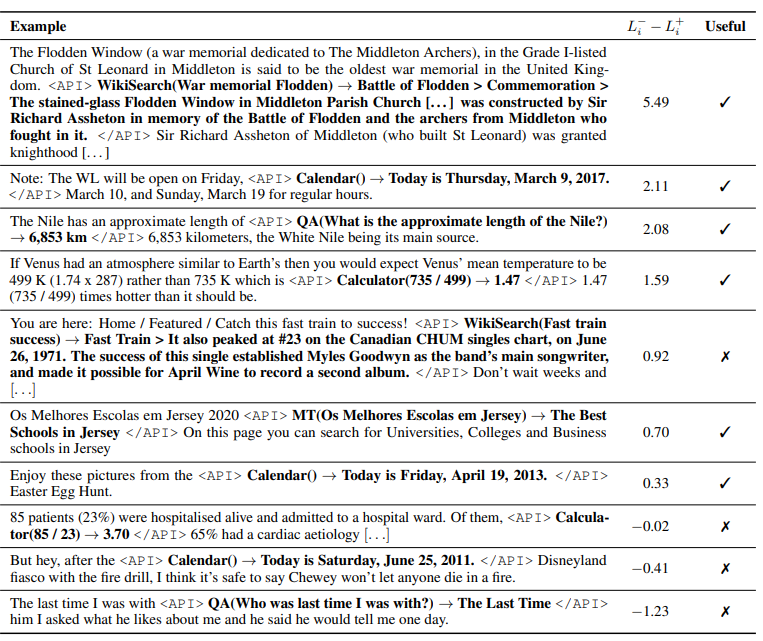
- API calls with high values of L−i − L+i are typically useful, while low values do not provide useful information.
- Various approaches augment language models with additional textual information during pretraining.
- Toolformer learns to explicitly ask for the right information instead of relying on additional information provided during pretraining.
- Several approaches aim to equip language models with the ability to use external tools.
- Toolformer uses self-supervised learning to learn how and when to use tools without requiring specific prompts.
- Bootstrapping techniques are used to improve Toolformer by training on its predictions after applying certain criteria. — Toolformer is a language model that learns how to use different tools via API calls.
- Toolformer improves the zero-shot performance of a GPT-J model.
- The calculator tool supports basic mathematical operations and does not return results for invalid equations.
- The calculator tool is filtered based on documents containing numbers or specific sequences.
- The calendar tool extracts the date from the URL and filters out texts without a date.
- The machine translation tool uses a 600M parameter NLLB model and filters out English text chunks.
- The machine translation tool removes API calls where the input appears after the call.
- The Wikipedia search tool allows users to look up information using a search term.
- The question-answering tool prompts users to add API calls to answer questions.
- The multilingual question-answering tool uses templates to answer questions about dates.
- The MLQA dataset randomly selects 500 “current dates” to create the dataset. — The Calendar tool randomly selects a past or future date within a four-year range.
- The selected date is used to fill query templates in Table 11.
- An example of a query using the first template is “How many days ago was August 14, 2020?”
- If called, the Calendar tool would return the presumed current date as “Today is Sunday, November 20, 2020.”
Conclusion
We have introduced Toolformer, a language model that learns in a self-supervised way how to use different tools such as search engines, calculators, and translation systems via simple API calls. This is done by finetuning on a large number of sampled API calls that are filtered based on whether they reduce perplexity on future tokens. Toolformer considerably improves the zero-shot performance of a 6.7B parameter GPT-J model, enabling it even to outperform a much larger GPT-3 model on a range of different downstream tasks.
Figures




Prompts
Below, we list the prompts used to sample API calls for each tool considered.
Question Answering
We use the following prompt for the question-answering tool:
Your task is to add calls to a Question
Answering API to a piece of text.
The questions should help you get
information required to complete the
text. You can call the API by writing
"[QA(question)]" where "question" is the
question you want to ask. Here are some
examples of API calls:
Input: Joe Biden was born in Scranton,
Pennsylvania.
Output: Joe Biden was born in [QA("Where
was Joe Biden born?")] Scranton,
[QA("In which state is Scranton?")]
Pennsylvania.
Input: Coca-Cola, or Coke, is a
carbonated soft drink manufactured by
the Coca-Cola Company.
Output: Coca-Cola, or [QA("What other
name is Coca-Cola known by?")] Coke, is
a carbonated soft drink manufactured by
[QA("Who manufactures Coca-Cola?")] the
Coca-Cola Company.
Input: x
Output:Calculator
We use the following prompt for the calculator:
Your task is to add calls to a
Calculator API to a piece of text.
The calls should help you get
information required to complete the
text. You can call the API by writing
"[Calculator(expression)]" where
"expression" is the expression to be
computed. Here are some examples of API
calls:
Input: The number in the next term is 18
+ 12 x 3 = 54.
Output: The number in the next term is
18 + 12 x 3 = [Calculator(18 + 12 * 3)]
54.
Input: The population is 658,893 people.
This is 11.4% of the national average of
5,763,868 people.
Output: The population is 658,893 people.
This is 11.4% of the national average of
[Calculator(658,893 / 11.4%)] 5,763,868
people.
Input: A total of 252 qualifying matches
were played, and 723 goals were scored
(an average of 2.87 per match). This is
three times less than the 2169 goals
last year.
Output: A total of 252 qualifying
matches were played, and 723 goals were
scored (an average of [Calculator(723
/ 252)] 2.87 per match). This is twenty
goals more than the [Calculator(723 -
20)] 703 goals last year.
Input: I went to Paris in 1994 and
stayed there until 2011, so in total,
it was 17 years.
Output: I went to Paris in 1994 and
stayed there until 2011, so in total, it
was [Calculator(2011 - 1994)] 17 years.
Input: From this, we have 4 * 30 minutes
= 120 minutes.
Output: From this, we have 4 * 30
minutes = [Calculator(4 * 30)] 120
minutes.
Input: x
Output:Wikipedia Search
We use the following prompt for the Wikipedia search tool:
Your task is to complete a given piece
of text. You can use a Wikipedia Search
API to look up information. You can do
so by writing "[WikiSearch(term)]" where
"term" is the search term you want to
look up. Here are some examples of API
calls:
Input: The colors on the flag of Ghana
have the following meanings: red is for
the blood of martyrs, green for forests,
and gold for mineral wealth.
Output: The colors on the flag of Ghana
have the following meanings: red is for
[WikiSearch("Ghana flag red meaning")]
the blood of martyrs, green for forests,
and gold for mineral wealth.
Input: But what are the risks during
production of nanomaterials? Some
nanomaterials may give rise to various
kinds of lung damage.
Output: But what are the risks
during production of nanomaterials?
[WikiSearch("nanomaterial production
risks")] Some nanomaterials may give
rise to various kinds of lung damage.
Input: Metformin is the first-line drug
for patients with type 2 diabetes and
obesity.
Output: Metformin is the first-line drug
for [WikiSearch("Metformin first-line
drug")] patients with type 2 diabetes
and obesity.
Input: x
Output:Machine Translation
We use the following prompt for the machine translation tool:
Your task is to complete a given piece
of text by using a Machine Translation
API.
You can do so by writing "[MT(text)]"
where text is the text to be translated
into English.
Here are some examples:
Input: He has published one book: O
homem suprimido (“The Supressed Man”)
Output: He has published one book: O
homem suprimido [MT(O homem suprimido)]
(“The Supressed Man”)
Input: In Morris de Jonge’s Jeschuah,
der klassische jüdische Mann, there is a
description of a Jewish writer
Output: In Morris de Jonge’s Jeschuah,
der klassische jüdische Mann [MT(der
klassische jüdische Mann)], there is a
description of a Jewish writer
Input: 南 京 高 淳 县 住 房 和 城 乡 建 设 局 城 市 新
区 设 计 a plane of reference Gaochun is
one of seven districts of the provincial
capital Nanjing
Output: [MT(南京高淳县住房和城乡建设局 城市新
区 设 计)] a plane of reference Gaochun is
one of seven districts of the provincial
capital Nanjing
Input: x
Output:Calendar
We use the following prompt for the calendar tool:
Your task is to add calls to a Calendar
API to a piece of text. The API calls
should help you get information required
to complete the text. You can call the
API by writing "[Calendar()]" Here are
some examples of API calls:
Input: Today is the first Friday of the
year.
Output: Today is the first [Calendar()]
Friday of the year.
Input: The president of the United
States is Joe Biden.
Output: The president of the United
States is [Calendar()] Joe Biden.
Input: The current day of the week is
Wednesday.
Output: The current day of the week is
[Calendar()] Wednesday.
Input: The number of days from now until
Christmas is 30.
Output: The number of days from now
until Christmas is [Calendar()] 30.
Input: The store is never open on the
weekend, so today it is closed.
Output: The store is never open on the
weekend, so today [Calendar()] it is
closed.
Input: x
Output:









0 Comments