
https://cbarkinozer.medium.com/pythonun-benzersiz-%C3%B6zellikleri-nelerdir-b%C3%B6l%C3%BCm-1-a46371d8e9d3
Let’s go over the Python peculiarities and unique features that you should be aware of.

Python has been the most popular language since June 2020, according to the TIOBE index. It is a high-level, interpreted, general-purpose programming language developed by Guido van Rossum and first released in 1991.
Python is an object-oriented programming (OOP) language that is compatible with Windows, Linus, Apple iOS, and Google OS operating systems. It has a robust core standard library, many open source frameworks and libraries that are part of the Python Ecosystem, is a simple general-purpose programming language, and supports unit testing.
Python is a dynamically typed language in which data can be stored as a mutable object at runtime, allowing it to be altered after creation.
Python uses identifiers to name things. An identifier begins with a letter A (or a) through Z (or z), or an underscore (_) followed by a zero, additional letters, underscores, or any numeral (0 to 9). Examples include last_name, _last_name, last_name_1, and so on. It is quite crucial to 14. Primitive variables. These are the most basic data structures, hence their “primitive” name. They are capable of storing only one value. Follow the Python naming conventions outlined in the PEP 8-Style Guide for Python Code. This collection of documents discusses Python standards, code organization, and development best practices.
Primitive Data Structures in Python
Primitive data structures are the language’s built-in data structures that can only store one value. These include integers, floats, strings, and booleans. Although certain types are provided here, you do not declare them; the Python interpreter determines the type of the variable at runtime.
Non-Primitive Data Structures in Python
In Python, non-primitive data structures represent both sorted and unordered sequences of objects. These include lists, tuples, dictionaries, sets, and frozensets. A mutable object can be altered after it has been created, but an immutable object cannot. Built-in objects like integer, float, Boolean, text, and tuple are immutable. Other built-in objects, like list, set, and dictionary, are mutable.
String Manipulation
Python string objects are immutable. You can obtain a character from a string but cannot modify it.
print(string_value[5]) # valid
string_value[5] = "m" # not validFunction
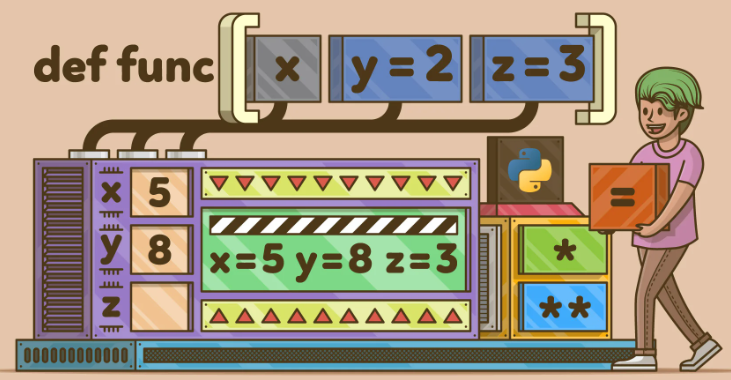
A function is a reusable piece of code that is designed to complete a specific task. In general, the goal of writing functions in computer programming is to build a sub-program that may be called as many times as necessary. This will reduce code duplication wherever possible. Functions are the primary components of class objects (they can exist even when there are no classes, contrary to some languages), and their names must adhere to the Python naming standard.
Python utilizes three types of functions:
- Python interpreters include built-in functions. For example, “print()” prints any object to the console.
- User-defined functions are created by users to meet their specific software requirements.
- Anonymous functions are defined without a name. Anonymous functions are defined with the “lambda” keyword. In general, these functions are faster in Python.
Python employs the “docstring” term (the text in triple quotes) to document modules, functions, and classes in the same way as it does comments. A “docstring” is a string literal that appears as the first statement within a module, function, or class.
Python Parameter Pass Type: By default, Python passes parameters as references and does not support output parameters like other languages. To pass by value, a copy of the real parameter’s value is created in memory. When a pass-by reference (by address) occurs, a duplicate of the original parameter’s address is retained.
In Python, the if __name__ == ‘__main__’ statement determines whether the module name matches the built-in variable __main__. It instructs the module to start after this line. It is good programming practice to begin any Python program using the usual main statement.
Sometimes you don’t know what the default parameter value is. In some circumstances, the “None” keyword can be used to specify a null or no value at all. It is vital to note that None is not synonymous with 0, False, Null, or an empty string. None of them is a distinct data type.
Method overloading occurs when two or more functions share the same name but have distinct input arguments. Python supports function overloading. Instead of employing multiple functions to accomplish the required task(s), you can encapsulate everything in a single function, significantly decreasing the amount of code.
*args and **kwargs: We may not know the exact number of input parameters to pass to a function. In this instance, use the following syntax: single-asterisk parameters *args or double-asterisk **kwargs. Because *args is used to transmit a variable-length argument list to the function, we can pass as many parameters as needed to the calling function. The double-asterisk option **kwargs can be used to pass a variable-length dictionary structure to this function.
Variable Scopes
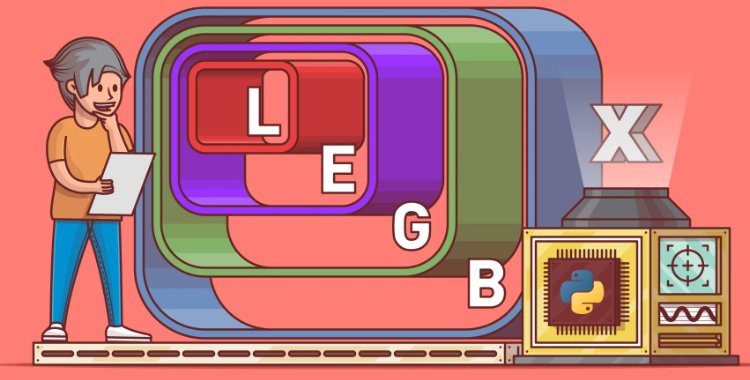
The place in the program where a name (variable) is defined is referred to as scope. Python has two types of variable scopes.
- Local variables refer to any variable defined within a function.
- Global variables refer to any variable defined outside the function. If a global keyword is used within the function, the variable becomes global for the entire program. Global variable declarations are not commonly used in Python anymore.
Nested Functions
A nested function is defined within another function. The nested function can access the enclosing function’s variables as read-only. To modify the value of any of these variables in the nested function, they must be defined explicitly with the nonlocal keyword.
Nested functions are not very common, however, they are used for:
- Encapsulation: A function’s scope can be limited to the function it is enclosing. This can be handy for grouping related operations and avoiding polluting the global namespace.
- Nested functions can help you organize code logically. When one function is closely related to another, it is appropriate to nest it within the larger function.
- Closure: Inner functions can access the surrounding function’s variables even after the outer function has finished executing. This enables you to write closures, which are functions that retain the state of their enclosing scope when returned.
- Readability and Maintainability: Nesting functions allow you to keep related functionality together, making the code easier to read and maintain.
You cannot call the inner function from the outside unless you require the inner function to return itself and generate a reference to the outer function.
def outer_function():
def inner_function():
print("Inside inner function")
return inner_function
my_function = outer_function()
# Call the inner function from outside
my_function()Lambda Functions
Lambda functions are known as anonymous functions because they do not have a name. The return statement is not required because it always returns a value. The most effective way to use these functions is within another standard def function. Lambda functions are typically preferred when the function is too simple and may be written in a single line.
# Regular function
def square(x):
return x ** 2
# Equivalent lambda function
square_lambda = lambda x: x ** 2
# Using the functions
print(square(5)) # Output: 25
print(square_lambda(5)) # Output: 25Lambda functions are commonly employed in circumstances requiring a short, anonymous function, such as map(), filter(), or sorted(). Here are few examples:
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers) # Output: [1, 4, 9, 16, 25]
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # Output: [2, 4, 6, 8, 10]
pairs = [(1, 5), (3, 2), (8, 6)]
sorted_pairs = sorted(pairs, key=lambda pair: pair[1])
print(sorted_pairs) # Output: [(3, 2), (8, 6), (1, 5)]Flow Control

I’ll skip the core flow control elements like while loops, for loops, if-else statements, and so on, presuming you’re already familiar with them. Python, unlike various other languages (such as C and Java), does not include a built-in do-while loop. You may get comparable functionality by using a while loop with a conditional check at the end. The function “range(start, stop, step)” allows you to specify how many iterations are performed.
How can you make your loops run faster?
- Using Vectorized Operations
When doing elementwise array operations, use numpy or pandas as much as possible.
import numpy as np
# Example: Element-wise multiplication of two arrays
a = np.array([1, 2, 3, 4, 5])
b = np.array([6, 7, 8, 9, 10])
result = a * b # Vectorized operation
print(result)- Minimizing Function Calls Inside Loops
def square(x):
return x ** 2
numbers = [1, 2, 3, 4, 5]
squared_numbers = [square(num) for num in numbers] # Function call inside loop
# Good practice: Compute outside loop
squared_numbers = [num ** 2 for num in numbers] # Avoids function call inside loop- Using List Comprehensions
# List comprehension for generating squares of numbers
numbers = [1, 2, 3, 4, 5]
squared_numbers = [num ** 2 for num in numbers] # List comprehension- Preallocating Memory
# Preallocate memory for a large list
size = 1000000
result = [0] * size # Preallocate memory
# Use result in a loop
for i in range(size):
result[i] = i * 2- Using Built-in Functions
# Example: Using map() for applying a function to a list
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x ** 2, numbers))- Using Iterators
# Example: Using range() as an iterator
for i in range(1000000): # Use iterator instead of list
pass- Using Cython or Numba
# Example using Numba for just-in-time compilation
from numba import jit
@jit
def square(x):
return x ** 2
result = square(5) # Just-in-time compiled functionInput/Output

The “input()” function lets the software interact with the user. The “print()” function can be used to display the data entered by the user.
File IO
We open files in Python to read and write data. The access mode defined in the “open(mode, [buffering])” function determines the file-related action.
The modes are:
- The “r” mode is used for reading files solely.
- The “w” mode allows for editing and adding new information to a file, but erases any existing files with the same name.
- The “a” appending mode adds new data to the end of a file. New information is automatically put at the end.
- “r+” refers to a read-and-write mode that allows for simultaneous file operations.
To write to a file, use the “write()” function.
file_test = open("test.txt", "w")
file_test.write( "Python is a great language.\nSure!\n")
file_test.close()The application runs from the same location as the test.txt file is written. As you can see, the created file object “file_test” must be closed to free its memory resources.
Obtaining all material from a file:
file_test = open("test.txt", "r")
print(file_test.read())Getting all of the material line by line.
file_test = open("test.txt", "r")
for item in file_test:
print(item)If you want to return one line from a file, use the “readline()” method. The standard syntax for this method is “file.readline(size)”, with the “size” parameter optional. It indicates the number of bytes from the line that will be returned. The default number is -1, indicating the entire line.
file_test = open("test.txt", "r")
lines = file_test.readline(6)Working with files in Python necessitates knowledge of their location path. Python offers a “pathlib” package for working with files and paths. To use this library, the path or file name must be supplied to the “Path()” object with forward slashes.
from pathlib import Path
# Define the file path
file_path = Path("path/to/your/file.txt")
# Check if the file exists
if file_path.exists():
print("File exists.")
# Read the contents of the file
with open(file_path, "r") as file:
content = file.read()
print("File content:")
print(content)
else:
print("File does not exist.")The file’s intended buffer size is specified by the optional “buffering” argument in the “open(mode, [buffering])” function. 0 denotes no buffering, 1 means line buffering, and any other positive value indicates that a buffer of roughly that size (in bytes) should be utilized. Negative buffering indicates that the system default should be used. If not specified, the system default will be utilized.
Logging in Python
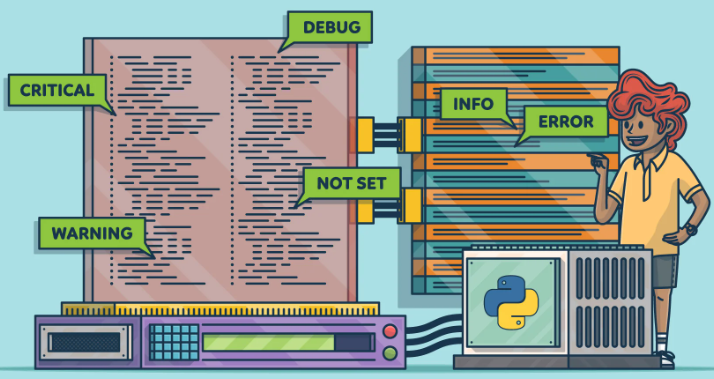
Print() should not be used in production code; instead, use logging. Logging data in the appropriate places allows you to easily diagnose faults and analyze program performance for future improvements. as general, data is stored as text files and/or database tables. To log data in Python, use the “import logging” statement to load the built-in logging module.
Logging levels
The log messages include five levels of event severity:
- DEBUG: This logs messages while programming debugging. It is frequently used to see the return values of variables and functions.
- The INFO command logs any program-related information.
- WARNING: This is used to log warning messages. It is frequently used to identify preventing information that may have occurred during program execution.
- ERROR: This logs any errors that happened while the program was running. In general, these messages contain precise error information such as the error line of code, the date and time of the problem, the function and module file names where the issue occurred, and so on.
- CRITICAL — This logs critical errors. It is frequently used to identify generic application crashes.
Basic configuration
These levels are specified in the basic configuration method basicConfig(**kwargs). This method’s arguments are as follows:
- level: The event severity level (DEBUG, INFO, WARNING, ERROR, and CRITICAL).
- filename: This is the file path and name.
- filemode: If a filename is specified, the file is opened in this mode. The default value is a, which represents append.
- Format: This is the message format.
Example:
import logging
logging.basicConfig(filename="app.log", filemode="w", format="%(name)s
- %(levelname)s - %(message)s")
logging.warning("This message gets logged as warning.")Modules and Packages
A module is a file containing Python code that can specify functions, classes, and variables. Modular programming is the technique of breaking down huge programming tasks into smaller, more manageable sub-units or modules. Individual modules can be combined as building blocks to create huge enterprise business systems. This sort of programming has the following advantages:
- Simplicity: A module often focuses on a small area of the program. This makes development, debugging, and testing much easier.
- Maintainability: Modules can be easily updated and new features added without affecting the entire program. This will allow for more collaboration among team members.
- Reusability refers to how functionality produced in one module can be easily reused in other areas of the program. This avoids the need for redundant code.
- Scoping-Modules are often defined as separate namespaces to avoid clashes between identifiers in different parts of the program.
Importlib.reload() allows you to reload a single module’s code without restarting Python. If you make modifications to mymodule and want to implement those changes without restarting your Python script or interpreter, use importlib.reload() as follows:
import importlib
import mymodule
importlib.reload(mymodule)Module vs package: In Python, a module is a code file with the.py extension. Modules are used to reuse code by making external calls from the code. A package is defined as a folder containing one or more Python modules. A package is used in a module to hierarchically organize module namespaces, or it can be imported at the top of the code using dot notation.










0 Comments