
Turkish summary of Deeplearningai's short course "Preprocessing Unstructured Data for LLM Applications".

Preprocessing of Data for LLMs
RAG is the process of basing LLM answers on external information that ensures their accuracy. RAG applications load the context into the database, then fetch relevant context pieces upon request and send them as requests to LLMs.
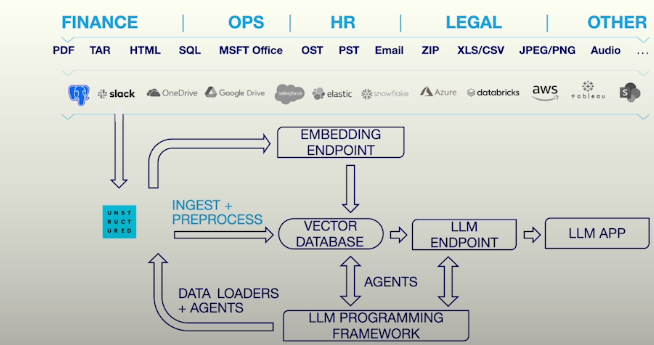
Companies' data sources can be in different formats such as PDF, Word, email or HTML.
Documents have elements: Headings, tables, list elements, images and texts.
Elements of documents also have metadata, which provide more detailed information about the elements. These metadata are useful for hybrid searching or retrieving resource-related information. Some metadata: information such as file name, file type, page number and section.
Why is data preprocessing difficult?
- Different document types have different clues, such as visual or symbolic, for element types.
- Standardization is needed to process the content of different document types.
- Different document formats, such as forms and articles, may need different data extraction methods.
- Extracting metadata requires knowing the document structure.
Normalization of Content
Documents are available in various formats such as PDF, Word, EPUB, Markdown. The first step in data preprocessing is to convert raw documents into a common format that contains common structures such as titles and text.
Normalized formats allow any document to be processed the same regardless of its source format. This could include filtering out unwanted elements such as titles or alt text, or splitting document elements into parts.
Normalization reduces transaction costs. Initial document processing steps are the most expensive parts of the process, regardless of source format. Operations such as chunking on normalized outputs are costless. Normalization allows you to experience documents without breaking them into different parts without reprocessing them.
Data Serialization
Serializing data allows the results of document processing to be reusable.
The advantage of the JSON format is that it is popular and well-known, it is a standard HTTP response, it can be used in many programming languages, and it can be converted to JSONL format and converted to streaming.
HTML pages are also a very important data type. Being able to process HTML data allows you to automatically integrate fresh data from the internet directly into your system.

Microsoft PowerPoint is widely used in consulting to present ideas, strategies and conclusions that are important for developing the knowledge base of the LLM. Extraction involves parsing elements in PowerPoint slides, such as bulleted paragraphs, slide notes, figures, and tables. Python libraries such as pptx are navigated and extract textual or visual information from slides.
from IPython.display import JSON
import json
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.partition.html import partition_html
from unstructured.partition.pptx import partition_pptx
from unstructured.staging.base import dict_to_elements, elements_to_json
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)Sample Document: Medium Blog HTML Page
from IPython.display import Image
Image(filename="images/HTML_demo.png", height=600, width=600)
filename = "example_files/medium_blog.html"
elements = partition_html(filename=filename)
element_dict = [el.to_dict() for el in elements]
example_output = json.dumps(element_dict[11:15], indent=2)
print(example_output)
JSON(example_output)Sample Document: MSFT PowerPoint on OpenAI
Image(filename="images/pptx_slide.png", height=600, width=600)
filename = "example_files/msft_openai.pptx"
elements = partition_pptx(filename=filename)
element_dict = [el.to_dict() for el in elements]
JSON(json.dumps(element_dict[:], indent=2))Sample Document: Chain of Thought PDF
Image(filename="images/cot_paper.png", height=600, width=600)
filename = "example_files/CoT.pdf"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy='hi_res',
pdf_infer_table_structure=True,
languages=["eng"],
)
try:
resp = s.general.partition(req)
print(json.dumps(resp.elements[:3], indent=2))
except SDKError as e:
print(e)
JSON(json.dumps(resp.elements, indent=2))Metadata Extraction and Shredding
Metadata provides additional information about content extracted from source documents. One type of metadata is information about the document itself, such as the filename, source URL, and file type. In RAG systems, metadata provides filtering options for hybrid searching.
In the case of a large number of documents, there may be too many semantically similar matches. Users may also want the most up-to-date information rather than the most semantically similar match. Hybrid search is a search strategy that combines semantic search with other information retrieval techniques such as filtering and keyword searching. For these cases, metadata in documents can be used as a filtering option.
import logging
logger = logging.getLogger()
logger.setLevel(logging.CRITICAL)
import json
from IPython.display import JSON
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.chunking.basic import chunk_elements
from unstructured.chunking.title import chunk_by_title
from unstructured.staging.base import dict_to_elements
import chromadb
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)Sample Document: Winter Sports in Switzerland EPUB
from IPython.display import Image
Image(filename='images/winter-sports-cover.png', height=400, width=400)
Image(filename="images/winter-sports-toc.png", height=400, width=400) Run the document via Unstructured API
filename = "example_files/winter-sports.epub"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(files=files)
try:
resp = s.general.partition(req)
except SDKError as e:
print(e)
JSON(json.dumps(resp.elements[0:3], indent=2))Find items associated with sections
[x for x in resp.elements if x['type'] == 'Title' and 'hockey' in x['text'].lower()]
chapters = [
"THE SUN-SEEKER",
"RINKS AND SKATERS",
"TEES AND CRAMPITS",
"ICE-HOCKEY",
"SKI-ING",
"NOTES ON WINTER RESORTS",
"FOR PARENTS AND GUARDIANS",
]
chapter_ids = {}
for element in resp.elements:
for chapter in chapters:
if element["text"] == chapter and element["type"] == "Title":
chapter_ids[element["element_id"]] = chapter
break
chapter_to_id = {v: k for k, v in chapter_ids.items()}
[x for x in resp.elements if x["metadata"].get("parent_id") == chapter_to_id["ICE-HOCKEY"]][0]Upload documents to a vector database
client = chromadb.PersistentClient(path="chroma_tmp", settings=chromadb.Settings(allow_reset=True))
client.reset()
collection = client.create_collection(
name="winter_sports",
metadata={"hnsw:space": "cosine"}
)
# Below code takes a little
for element in resp.elements:
parent_id = element["metadata"].get("parent_id")
chapter = chapter_ids.get(parent_id, "")
collection.add(
documents=[element["text"]],
ids=[element["element_id"]],
metadatas=[{"chapter": chapter}]
)See items in Vector DB
results = collection.peek()
print(results["documents"])Perform hash search with metadata
result = collection.query(
query_texts=["How many players are on a team?"],
n_results=2,
where={"chapter": "ICE-HOCKEY"},
)
print(json.dumps(result, indent=2))Breaking Content into Pieces
Vector databases require fragmentation of documents to perform RAG transactions because LLMs have a limit on the number of tokens that can be processed at a time. Depending on how the document is fragmented, the same query may yield different answers. The most basic way to divide a document into pieces is to divide it into pieces of the same size. If the structure of the document is known, it can be divided into parts so that the natural structure is preserved.
The optimal segmentation approach is as follows: First, the document is separated according to its sub-elements, such as headings and subheadings. These sub-parts are then added to the parts until the part limit is reached. When moving to a new track, symbols are added to indicate that you are moving to a new track. For example, a new title can be added when a semantically new section is reached. Additionally, consecutive parts can be merged if they do not exceed the part limit.
Below is an example where the same page is divided by the number of characters at the top and by document elements at the bottom:

elements = dict_to_elements(resp.elements)
chunks = chunk_by_title(
elements,
combine_text_under_n_chars=100,
max_characters=3000,
)
JSON(json.dumps(chunks[0].to_dict(), indent=2))
len(elements)
len(chunks)Preprocessing PDFs and Images
Many types of documents, such as HTML, Word documents, and markup, contain formatting information. These documents can be pre-processed with rule-based parsers. For other documents, such as PDFs and images, formatting information is visual. Document Image Analysis (DIA) allows us to extract formatting information and text from the raw image of a document.
The 2 most popular document image analysis methods are document layout detection and image transformers. Document layout detection uses an object detection model to draw and label bounding boxes around layout elements in the document image.
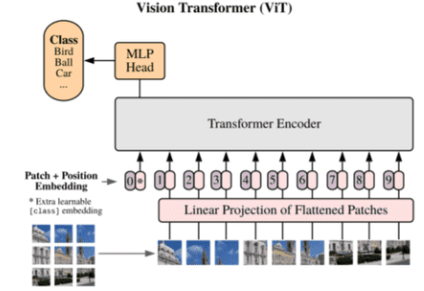
Vision transformer models take an image of a document as input and produce a text representation of a structured output such as JSON. VITs may also optionally receive a text prompt.
In document layout detection, a computer vision model such as YOLOX or Detectron2 is used to identify and classify bounding boxes. The text inside these boxes is then extracted using object character recognition (OCR) when necessary. For some documents, such as PDFs, text can be extracted directly from the documents without OCR.
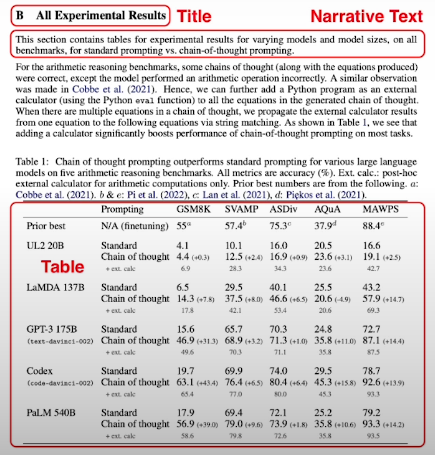
Document Layout Models have a fixed set of element types and take advantage of bounding box information. The disadvantage is that it requires 2 model calls and is less flexible.
In Vision Transformers, input images are passed to the encoder and the decoder produces text output. Document Understanding Architecture (DONUT) is a common architecture for VITs. In this approach, there is no need for OCRs as the input image is directly converted to text. VITs can train the model to output a valid JSON string with structured document output.
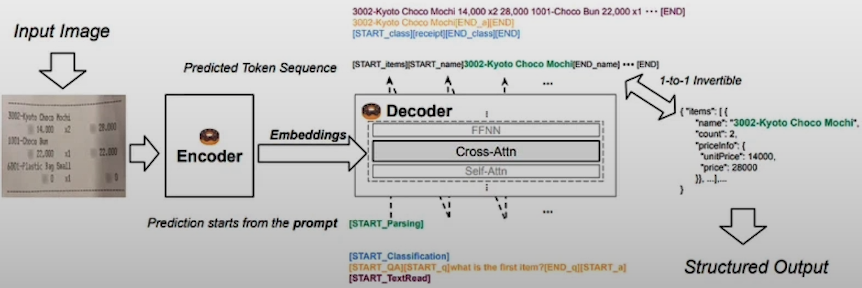
Vision Transformers is more flexible with non-standard document types. They adapt more easily to new ontologies. The disadvantage is that the model is prone to hallucinations due to its productivity. VITs are computationally expensive.
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.partition.html import partition_html
from unstructured.partition.pdf import partition_pdf
from unstructured.staging.base import dict_to_elements
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)Sample Document: News in PDF and HTML
from IPython.display import Image
Image(filename="images/el_nino.png", height=600, width=600) Render the document as HTML
filename = "example_files/el_nino.html"
html_elements = partition_html(filename=filename)
for element in html_elements[:10]:
print(f"{element.category.upper()}: {element.text}")Process the Document with Document Layout Detection
filename = "example_files/el_nino.pdf"
pdf_elements = partition_pdf(filename=filename, strategy="fast")
for element in pdf_elements[:10]:
print(f"{element.category.upper()}: {element.text}")
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy="hi_res",
hi_res_model_name="yolox",
)
try:
resp = s.general.partition(req)
dld_elements = dict_to_elements(resp.elements)
except SDKError as e:
print(e)
for element in dld_elements[:10]:
print(f"{element.category.upper()}: {element.text}")
import collections
len(html_elements)
html_categories = [el.category for el in html_elements]
collections.Counter(html_categories).most_common()
len(dld_elements)
dld_categories = [el.category for el in dld_elements]
collections.Counter(dld_categories).most_common()Extracting Tables
Some industries, such as finance and insurance, deal heavily with structured data embedded within unstructured data, which are tables within documents. It would be useful to extract tables from documents to implement situations such as table questions and answers. Table transformers, image transformers and OCR post-processing can be used. Tables can also be output in HTML format to preserve structure. OCR post-processing is fast and accurate for well-running tables but requires statistical or rule-based parsing, is less flexible, and does not link back to the image's bounding boxes.
Table transformers are models that define bounding boxes for table cells and convert the output to HTML. To implement table transformers, first define the tables using the document layout model. Then pass the table through the table transformer. Table transformers can trace cells back to the original bounding boxes. The disadvantage is the need for multiple expensive model calls.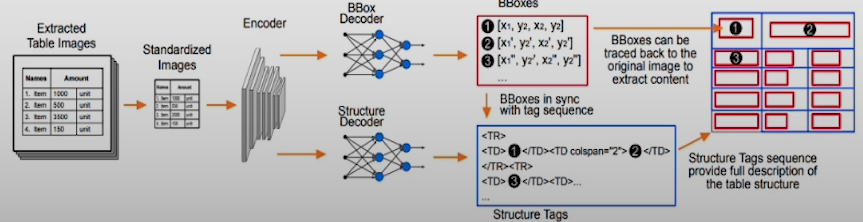
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.staging.base import dict_to_elements
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
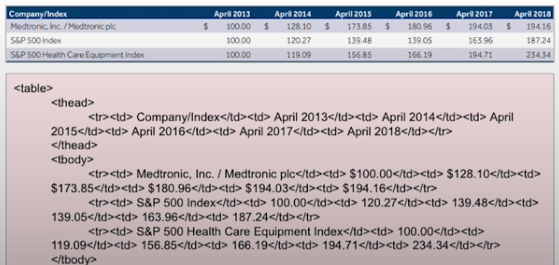
)Sample Document: Embedded Images and Tables
from IPython.display import Image
Image(filename="images/embedded-images-tables.jpg", height=600, width=600) Process the Document and Extract Tables
filename = "example_files/embedded-images-tables.pdf"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy="hi_res",
hi_res_model_name="yolox",
skip_infer_table_types=[],
pdf_infer_table_structure=True,
)
try:
resp = s.general.partition(req)
elements = dict_to_elements(resp.elements)
except SDKError as e:
print(e)
tables = [el for el in elements if el.category == "Table"]
tables[0].text
table_html = tables[0].metadata.text_as_html
from io import StringIO
from lxml import etree
parser = etree.XMLParser(remove_blank_text=True)
file_obj = StringIO(table_html)
tree = etree.parse(file_obj, parser)
print(etree.tostring(tree, pretty_print=True).decode())
from IPython.core.display import HTML
HTML(table_html)
from langchain_openai import ChatOpenAI
from langchain_core.documents import Document
from langchain.chains.summarize import load_summarize_chain
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
chain.invoke([Document(page_content=table_html)])Creating RAG Bot
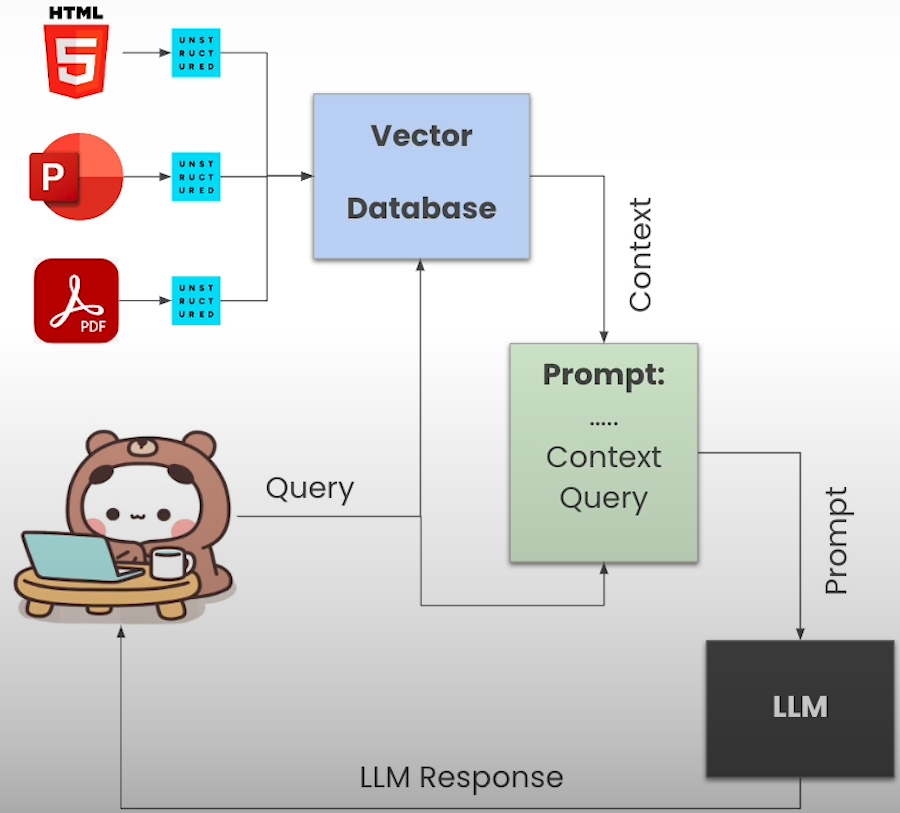
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.chunking.title import chunk_by_title
from unstructured.partition.md import partition_md
from unstructured.partition.pptx import partition_pptx
from unstructured.staging.base import dict_to_elements
import chromadb
from Utils import Utils
utils = Utils()
DLAI_API_KEY = utils.get_dlai_api_key()
DLAI_API_URL = utils.get_dlai_url()
s = UnstructuredClient(
api_key_auth=DLAI_API_KEY,
server_url=DLAI_API_URL,
)Sample Application: Questions and Answers about the Donut Model
from IPython.display import Image
Image(filename='images/donut_paper.png', height=400, width=400)
Image(filename='images/donut_slide.png', height=400, width=400)
Image(filename='images/donut_readme.png', height=600, width=600) Pre-process PDFs
filename = "example_files/donut_paper.pdf"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy="hi_res",
hi_res_model_name="yolox",
pdf_infer_table_structure=True,
skip_infer_table_types=[],
)
try:
resp = s.general.partition(req)
pdf_elements = dict_to_elements(resp.elements)
except SDKError as e:
print(e)
pdf_elements[0].to_dict()
tables = [el for el in pdf_elements if el.category == "Table"]
table_html = tables[0].metadata.text_as_html
from io import StringIO
from lxml import etree
parser = etree.XMLParser(remove_blank_text=True)
file_obj = StringIO(table_html)
tree = etree.parse(file_obj, parser)
print(etree.tostring(tree, pretty_print=True).decode())
Image(filename='images/donut_references.png', height=400, width=400)
reference_title = [
el for el in pdf_elements
if el.text == "References"
and el.category == "Title"
][0]
reference_title.to_dict()
references_id = reference_title.id
for element in pdf_elements:
if element.metadata.parent_id == references_id:
print(element)
break
pdf_elements = [el for el in pdf_elements if el.metadata.parent_id != references_id]Filter titles
Image(filename='images/donut_headers.png', height=400, width=400)
headers = [el for el in pdf_elements if el.category == "Header"]
headers[1].to_dict()
pdf_elements = [el for el in pdf_elements if el.category != "Header"]Preprocessing a PowerPoint Slide
filename = "example_files/donut_slide.pptx"
pptx_elements = partition_pptx(filename=filename)Preprocessing the README
filename = "example_files/donut_readme.md"
md_elements = partition_md(filename=filename)Uploading documents to Vector DB
elements = chunk_by_title(pdf_elements + pptx_elements + md_elements)
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
documents = []
for element in elements:
metadata = element.metadata.to_dict()
del metadata["languages"]
metadata["source"] = metadata["filename"]
documents.append(Document(page_content=element.text, metadata=metadata))
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 6}
)
from langchain.prompts.prompt import PromptTemplate
from langchain_openai import OpenAI
from langchain.chains import ConversationalRetrievalChain, LLMChain
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
template = """You are an AI assistant for answering questions about the Donut document understanding model.
You are given the following extracted parts of a long document and a question. Provide a conversational answer.
If you don't know the answer, just say "Hmm, I'm not sure." Don't try to make up an answer.
If the question is not about Donut, politely inform them that you are tuned to only answer questions about Donut.
Question: {question}
=========
{context}
=========
Answer in Markdown:"""
prompt = PromptTemplate(template=template, input_variables=["question", "context"])
llm = OpenAI(temperature=0)
doc_chain = load_qa_with_sources_chain(llm, chain_type="map_reduce")
question_generator_chain = LLMChain(llm=llm, prompt=prompt)
qa_chain = ConversationalRetrievalChain(
retriever=retriever,
question_generator=question_generator_chain,
combine_docs_chain=doc_chain,
)
qa_chain.invoke({
"question": "How does Donut compare to other document understanding models?",
"chat_history": []
})["answer"]
filter_retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1, "filter": {"source": "donut_readme.md"}}
)
filter_chain = ConversationalRetrievalChain(
retriever=filter_retriever,
question_generator=question_generator_chain,
combine_docs_chain=doc_chain,
)
filter_chain.invoke({
"question": "How do I classify documents with DONUT?",
"chat_history": [],
"filter": filter,
})["answer"]Resource
[1] Deeplearning.ai, (Nisan 2024), Preprocessing Unstructured Data For LLM Applications:
https://learn.deeplearning.ai/courses/preprocessing-unstructured-data-for-llm-applications/










0 Comments