
Summary of Deeplearning.ai's "Efficiently Serving LLMs" course.

Text Generation
We'll look at text generation with autoregressive generation models.
Let us import the essential packages:
import matplotlib.pyplot as plt
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizerLet's load the LLM; we'll be using GPT2 throughout this course.
model_name = "./models/gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)Let's look at the model's architecture:
print(model)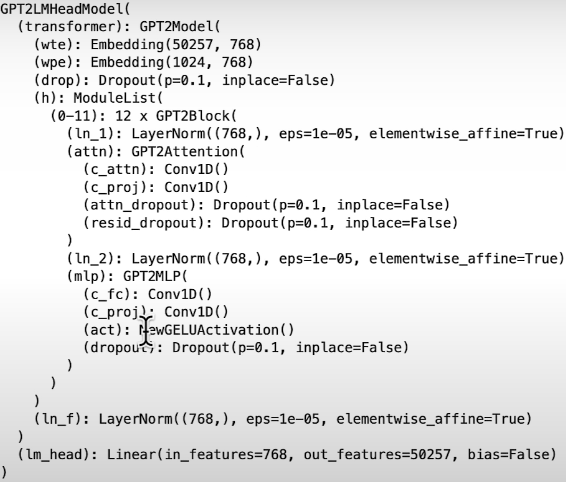
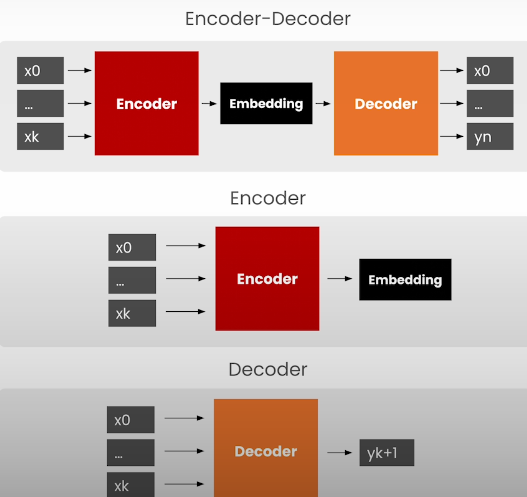
GPT-2 is a decoding-only model. LLMs can be encoders, decoders, or both, and the differences are shown below:
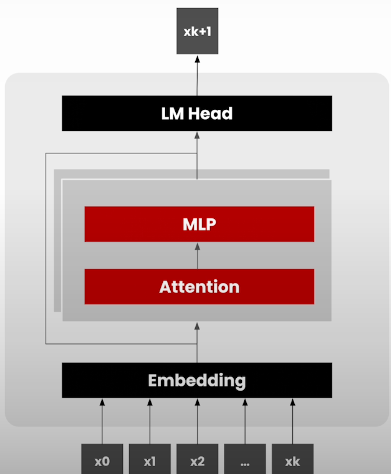
What is an autoregressive model?
Autoregressive models are a type of machine learning (ML) model that uses prior inputs to predict the next component in a sequence.
We begin by tokenizing the input prompt.
prompt = "The quick brown fox jumped over the"
inputs = tokenizer(prompt, return_tensors="pt")
inputsPass the inputs to the model and retrieve the logits to determine the most likely next token:
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
print(logits.shape) # torch.Size([1,7,50257]) # batch_size, sequence_length, vocabulary_size (possible token types)
last_logits = logits[0, -1, :]
next_token_id = last_logits.argmax()
next_token_idDecode the most likely token:
tokenizer.decode(next_token_id)Print the 10 most likely next words:
top_k = torch.topk(last_logits, k=10)
tokens = [tokenizer.decode(tk) for tk in top_k.indices]
tokensConcatenate the input with the most likely tokens:
next_inputs = {
"input_ids": torch.cat(
[inputs["input_ids"], next_token_id.reshape((1, 1))],
dim=1
),
"attention_mask": torch.cat(
[inputs["attention_mask"], torch.tensor([[1]])],
dim=1
),
}
print(next_inputs["input_ids"],
next_inputs["input_ids"].shape)
print(next_inputs["attention_mask"],
next_inputs["attention_mask"].shape)Optimizing token production in several phases.
The helper function below generates the next tokens given a collection of input tokens.
def generate_token(inputs):
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
last_logits = logits[0, -1, :]
next_token_id = last_logits.argmax()
return next_token_idUse the helper method to create several tokens in a loop. Track the time it takes to generate each token.
generated_tokens = []
next_inputs = inputs
durations_s = []
for _ in range(10):
t0 = time.time()
next_token_id = generate_token(next_inputs)
durations_s += [time.time() - t0]
next_inputs = {
"input_ids": torch.cat(
[next_inputs["input_ids"], next_token_id.reshape((1, 1))],
dim=1),
"attention_mask": torch.cat(
[next_inputs["attention_mask"], torch.tensor([[1]])],
dim=1),
}
next_token = tokenizer.decode(next_token_id)
generated_tokens.append(next_token)
print(f"{sum(durations_s)} s")
print(generated_tokens)Plot the time it takes to generate tokens. The x-axis here represents the token number. The y-axis represents the time to generate a token in milliseconds (ms).
plt.plot(durations_s)
plt.show()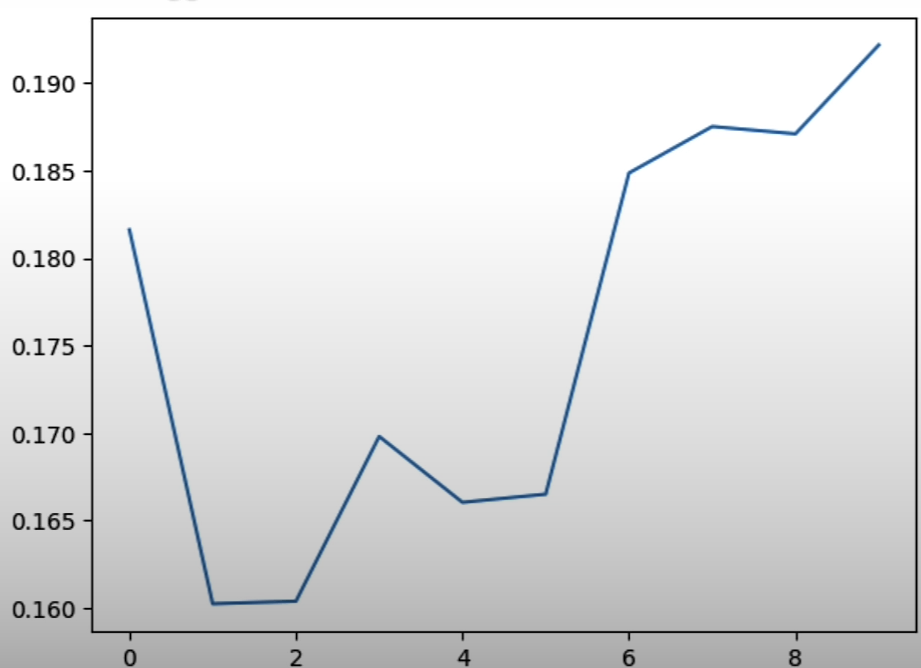
KV-caching speeds up text production.
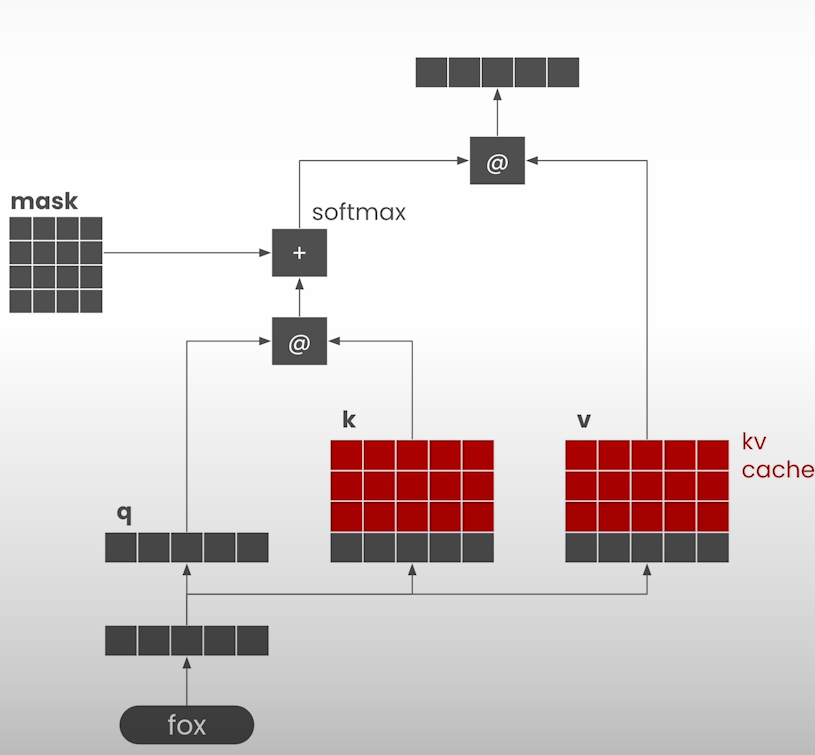
KV-caching is a strategy for speeding up token generation that involves keeping some tensors in the attention head for later usage in generation steps. Change the generate helper function to return the next token and the key/value tensors.
def generate_token_with_past(inputs):
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
last_logits = logits[0, -1, :]
next_token_id = last_logits.argmax()
return next_token_id, outputs.past_key_valuesGenerate 10 tokens with the revised helper function.
generated_tokens = []
next_inputs = inputs
durations_cached_s = []
for _ in range(10):
t0 = time.time()
next_token_id, past_key_values = \
generate_token_with_past(next_inputs)
durations_cached_s += [time.time() - t0]
next_inputs = {
"input_ids": next_token_id.reshape((1, 1)),
"attention_mask": torch.cat(
[next_inputs["attention_mask"], torch.tensor([[1]])],
dim=1),
"past_key_values": past_key_values,
}
next_token = tokenizer.decode(next_token_id)
generated_tokens.append(next_token)
print(f"{sum(durations_cached_s)} s")
print(generated_tokens)Compare the execution time of the KV-cache function to the original helper function.
plt.plot(durations_s)
plt.plot(durations_cached_s)
plt.show()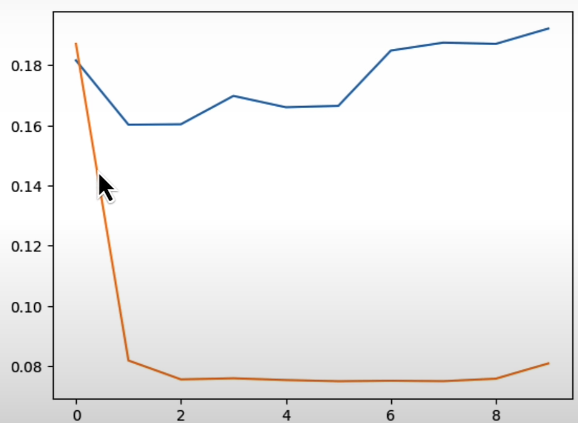
Batching
We will learn how to combine many requests into a single one.
Let's import the necessary packages and load the LLM.
import matplotlib.pyplot as plt
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from tqdm import tqdm
model_name = "./models/gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)Re-use the KV-cache text creation function from the previous subject
prompt = "The quick brown fox jumped over the"
inputs = tokenizer(prompt, return_tensors="pt")
def generate_token_with_past(inputs):
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
last_logits = logits[0, -1, :]
next_token_id = last_logits.argmax()
return next_token_id, outputs.past_key_values
def generate(inputs, max_tokens):
generated_tokens = []
next_inputs = inputs
for _ in range(max_tokens):
next_token_id, past_key_values = \
generate_token_with_past(next_inputs)
next_inputs = {
"input_ids": next_token_id.reshape((1, 1)),
"attention_mask": torch.cat(
[next_inputs["attention_mask"], torch.tensor([[1]])],
dim=1
),
"past_key_values": past_key_values,
}
next_token = tokenizer.decode(next_token_id)
generated_tokens.append(next_token)
return "".join(generated_tokens)
tokens = generate(inputs, max_tokens=10)
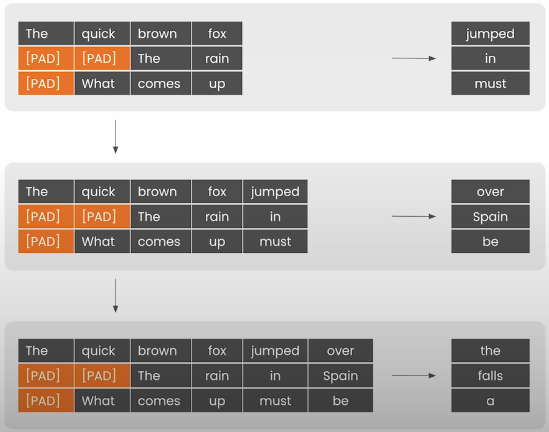
print(tokens)Insert padding tokens into the model to prepare batches of prompts.
# Define PAD Token = EOS Token = 50256
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
# pad on the left so we can append new tokens on the right
tokenizer.padding_side = "left"
tokenizer.truncation_side = "left"Tokenize the list of prompts. Add padding to ensure that all prompts have the same number of tokens as the longest one.
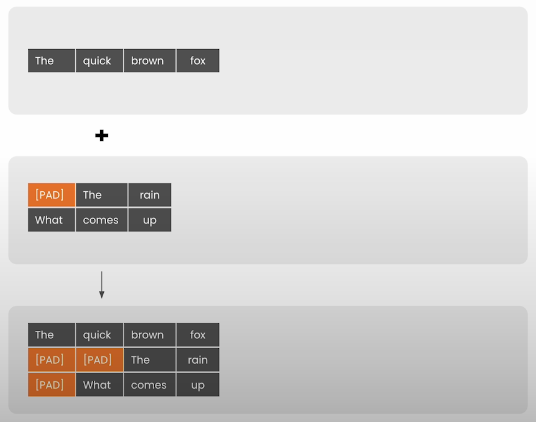
# multiple prompts of varying lengths to send
# to the model at once
prompts = [
"The quick brown fox jumped over the",
"The rain in Spain falls",
"What comes up must",
]
# note: padding=True ensures the padding token
# will be inserted into the tokenized tensors
inputs = tokenizer(prompts, padding=True, return_tensors="pt")print("input_ids:", inputs["input_ids"])
print("shape:", inputs["input_ids"].shape)
print("attention_mask:", inputs["attention_mask"])
print("shape:", inputs["attention_mask"].shape)Add position IDs to keep track of the original order of tokens in each prompt. Padding tokens are set to 1, and the first genuine token appears at position 0.
# position_ids tell the transformer the ordinal position
# of each token in the input sequence
# for single input inference, this is just [0 .. n]
# for n tokens, but for batch inference,
# we need to 0 out the padding tokens at the start of the sequence
attention_mask = inputs["attention_mask"]
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)Pass tokens to the model to calculate logits:
# same as before, but include the position_ids
with torch.no_grad():
outputs = model(position_ids=position_ids, **inputs)
logits = outputs.logitsRetrieve the most likely token for each prompt:
last_logits = logits[:, -1, :]
next_token_ids = last_logits.argmax(dim=1) Print the next token ids:
print(next_token_ids)Convert the token IDs into strings:
next_tokens = tokenizer.batch_decode(next_token_ids)
next_tokensLet’s put it all together
Generates n tokens with past:
def generate_batch_tokens_with_past(inputs):
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
last_logits = logits[:, -1, :]
next_token_ids = last_logits.argmax(dim=1)
return next_token_ids, outputs.past_key_valuesGenerate all tokens for some max tokens:
def generate_batch(inputs, max_tokens):
# create a list of tokens for every input in the batch
generated_tokens = [
[] for _ in range(inputs["input_ids"].shape[0])
]
attention_mask = inputs["attention_mask"]
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)
next_inputs = {
"position_ids": position_ids,
**inputs
}
for _ in range(max_tokens):
next_token_ids, past_key_values = \
generate_batch_tokens_with_past(next_inputs)
next_inputs = {
"input_ids": next_token_ids.reshape((-1, 1)),
"position_ids": next_inputs["position_ids"][:, -1].unsqueeze(-1) + 1,
"attention_mask": torch.cat([
next_inputs["attention_mask"],
torch.ones((next_token_ids.shape[0], 1)),
], dim=1),
"past_key_values": past_key_values,
}
next_tokens = tokenizer.batch_decode(next_token_ids)
for i, token in enumerate(next_tokens):
generated_tokens[i].append(token)
return ["".join(tokens) for tokens in generated_tokens]Call the generate_batch function and print out the generated tokens:
generated_tokens = generate_batch(inputs, max_tokens=10)
for prompt, generated in zip(prompts, generated_tokens):
print(prompt, f"\x1b[31m{generated}\x1b[0m\n")Throughput vs Latency
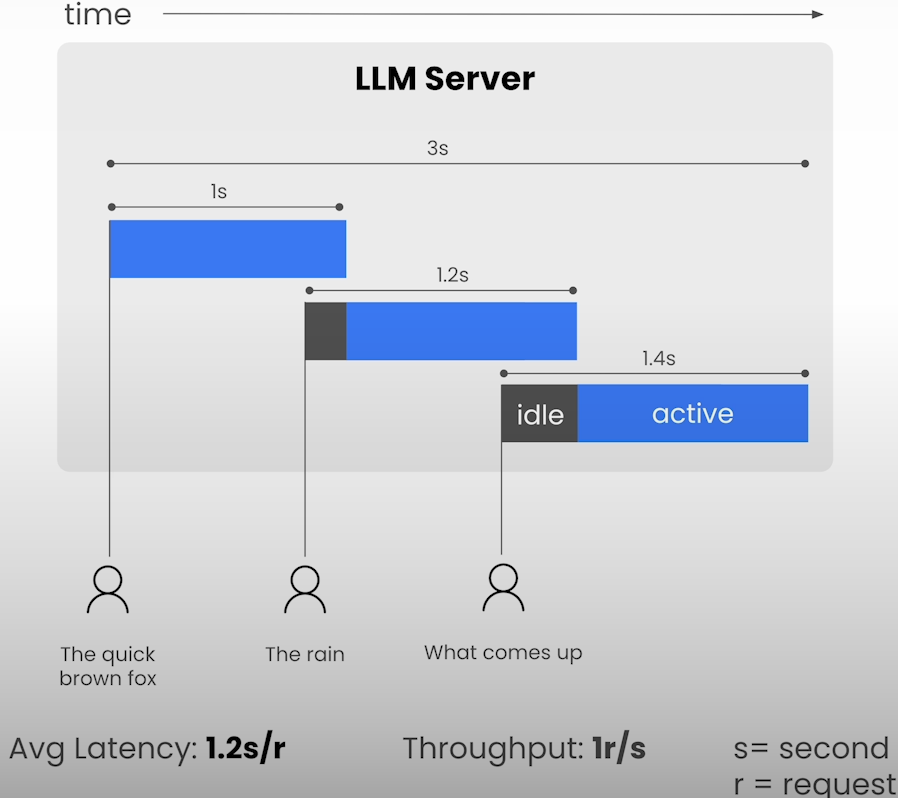
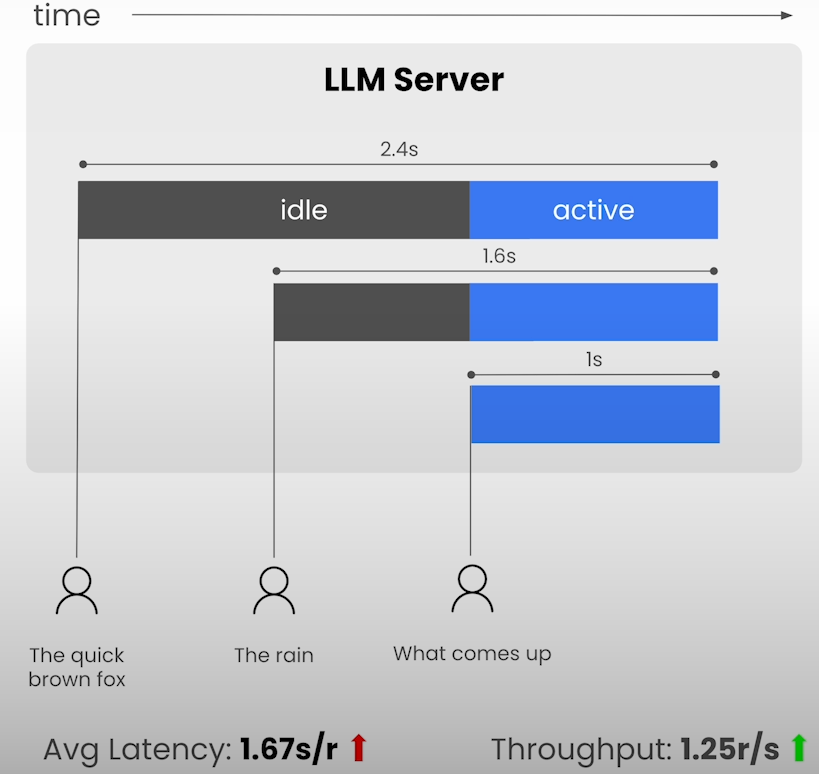
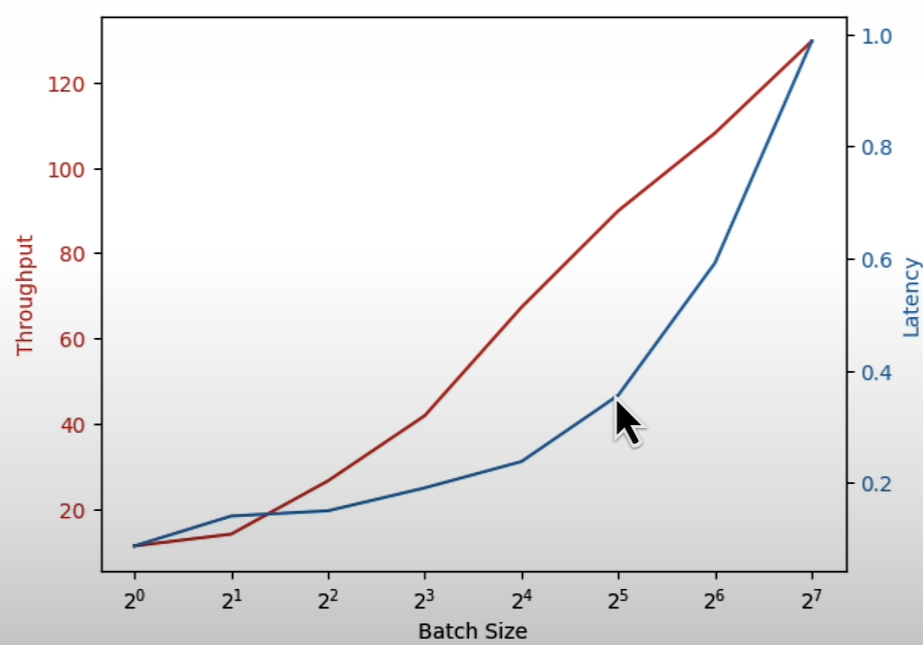
Investigate the impact of batching on latency (the time it takes to generate each token). Observe the fundamental tradeoff between throughput and delay.
# constants
max_tokens = 10
# observations
durations = []
throughputs = []
latencies = []
batch_sizes = [2**p for p in range(8)]
for batch_size in batch_sizes:
print(f"bs= {batch_size}")
# generate tokens for batch and record duration
t0 = time.time()
batch_prompts = [
prompts[i % len(prompts)] for i in range(batch_size)
]
inputs = tokenizer(
batch_prompts, padding=True, return_tensors="pt"
)
generated_tokens = generate_batch(inputs, max_tokens=max_tokens)
duration_s = time.time() - t0
ntokens = batch_size * max_tokens
throughput = ntokens / duration_s
avg_latency = duration_s / max_tokens
print("duration", duration_s)
print("throughput", throughput)
print("avg latency", avg_latency)
print()
durations.append(duration_s)
throughputs.append(throughput)
latencies.append(avg_latency)Let’s plot the throughput and latency observations against the batch size
def render_plot(x, y1, y2, x_label, y1_label, y2_label):
# Create a figure and a set of subplots
fig, ax1 = plt.subplots()
# Plot the first line (throughput)
color = 'tab:red'
ax1.set_xlabel(x_label)
ax1.set_ylabel(y1_label, color=color)
ax1.plot(x, y1, color=color)
ax1.tick_params(axis='y', labelcolor=color)
# Set the x-axis to be log-scaled
ax1.set_xscale('log', base=2)
# Instantiate a second axes that shares the same x-axis
ax2 = ax1.twinx()
color = 'tab:blue'
ax2.set_ylabel(y2_label, color=color) # we already handled the x-label with ax1
ax2.plot(x, y2, color=color)
ax2.tick_params(axis='y', labelcolor=color)
plt.show()render_plot(
batch_sizes,
throughputs,
latencies,
"Batch Size",
"Throughput",
"Latency"
)
Continuous Batching
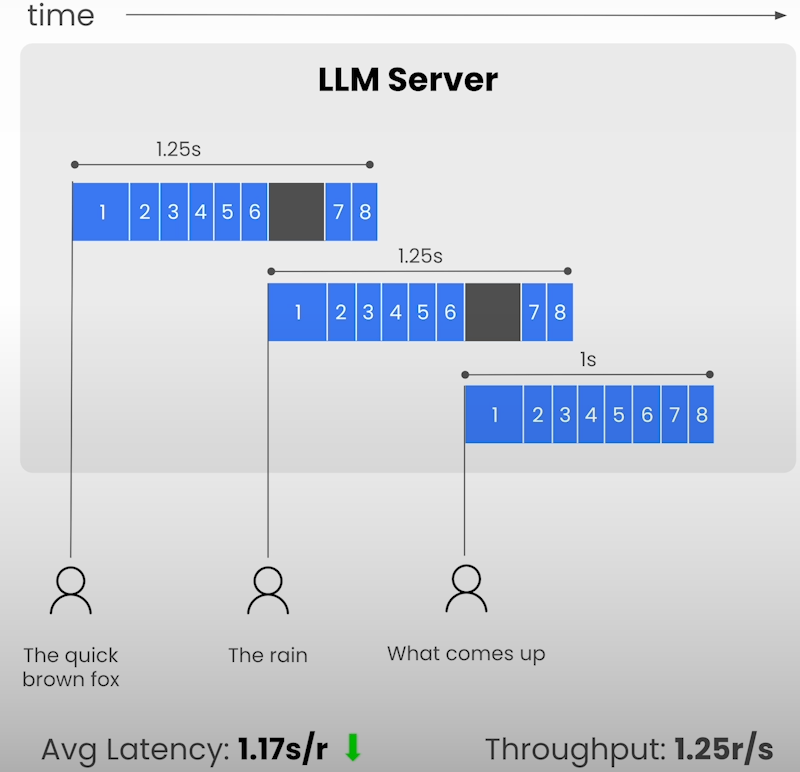
The main idea behind continuous batching is to constantly swap out requests from a finished batch for requests in the queue that are waiting to be processed.
Import required packages and load the LLM
# Import all needed functions from Lesson 1 and 2
import helpers
from helpers import init_batch, generate_next_token
from helpers import merge_batches, filter_batch
import copy
import matplotlib.pyplot as plt
import numpy as np
import random
import time
import torch
import torch.nn.functional as F
from tqdm import tqdm
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "./models/gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)Add padding tokens to the model to prepare batches of prompts
# Define PAD Token = EOS Token = 50256
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
# pad on the left so we can append new tokens on the right
tokenizer.padding_side = "left"
tokenizer.truncation_side = "left"
# multiple prompts of varying lengths to send to the model at once
prompts = [
"The quick brown fox jumped over the",
"The rain in Spain falls",
"What comes up must",
]
# note: padding=True ensures the padding token will be inserted into the tokenized tensors
inputs = tokenizer(prompts, padding=True, return_tensors="pt")Define needed functions for batching
def generate_batch_tokens_with_past(inputs):
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
last_logits = logits[:, -1, :]
next_token_ids = last_logits.argmax(dim=1)
return next_token_ids, outputs.past_key_values
def generate_batch(inputs, max_tokens):
# create a list of tokens for every input in the batch
generated_tokens = [[] for _ in range(inputs["input_ids"].shape[0])]
attention_mask = inputs["attention_mask"]
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)
next_inputs = {
"position_ids": position_ids,
**inputs
}
for _ in range(max_tokens):
next_token_ids, past_key_values = generate_batch_tokens_with_past(next_inputs)
next_inputs = {
"input_ids": next_token_ids.reshape((-1, 1)), # '-1' here means the remaining elements for this dim
"position_ids": next_inputs["position_ids"][:, -1].unsqueeze(-1) + 1, # increment last, discard the rest
"attention_mask": torch.cat([
next_inputs["attention_mask"],
torch.ones((next_token_ids.shape[0], 1)), # concatenate vector of 1's with shape [batch_size]
], dim=1),
"past_key_values": past_key_values,
}
next_tokens = tokenizer.batch_decode(next_token_ids)
for i, token in enumerate(next_tokens):
generated_tokens[i].append(token)
return ["".join(tokens) for tokens in generated_tokens]Define the requests to be processed
# seed the random number generator so our results are deterministic
random.seed(42)
# constants
queue_size = 32
batch_size = 8
# requests waiting to be processed
# requests are tuples (prompt, max_tokens)
request_queue = [
(prompts[0], 100 if i % batch_size == 0 else 10)
for i in range(queue_size)
]
request_queue[:8]
batches = [
request_queue[i:i + batch_size]
for i in range(0, len(request_queue), batch_size)
]
len(batches)
batches[0]Processing batches
# generate tokens for all batches and record duration
t0 = time.time()
with tqdm(total=len(batches), desc=f"bs={batch_size}") as pbar:
for i, batch in enumerate(batches):
# to accommodate all the requests with our
# current implementation, we take the max of
# all the tokens to generate among the requests
batch_max_tokens = [b[1] for b in batch]
max_tokens = max(batch_max_tokens)
pbar.set_postfix({'max_tokens': max_tokens})
batch_prompts = [b[0] for b in batch]
inputs = tokenizer(
batch_prompts, padding=True, return_tensors="pt")
generate_batch(inputs, max_tokens=max_tokens)
pbar.update(1)
duration_s = time.time() - t0
print("duration", duration_s)Let’s try continuous batching
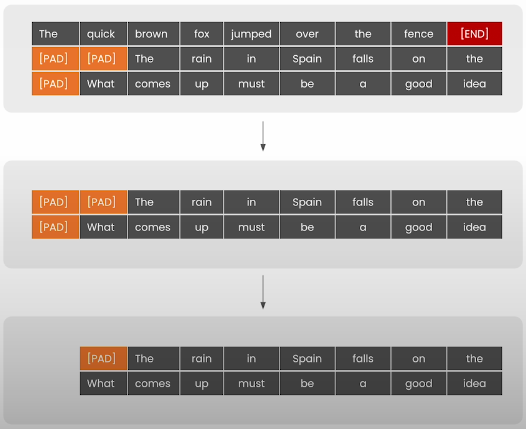
This time, rather than processing each batch to completion, you will use continuous batching to dynamically swap in and out inputs from the queue.
# seed the random number generator so our results are deterministic
random.seed(42)
# constants
queue_size = 32
batch_size = 8
# requests waiting to be processed
# this time requests are tuples (prompt, max_tokens)
request_queue = [
(prompts[0], 100 if i % batch_size == 0 else 10)
for i in range(queue_size)
]
t0 = time.time()
with tqdm(total=len(request_queue), desc=f"bs={batch_size}") as pbar:
# first, let's seed the initial cached_batch
# with the first `batch_size` inputs
# and run the initial prefill step
batch = init_batch(request_queue[:batch_size])
cached_batch = generate_next_token(batch)
request_queue = request_queue[batch_size:]
# continue until both the request queue is
# fully drained and every input
# within the cached_batch has completed generation
while (
len(request_queue) > 0 or
cached_batch["input_ids"].size(0) > 0
):
batch_capacity = (
batch_size - cached_batch["input_ids"].size(0)
)
if batch_capacity > 0 and len(request_queue) > 0:
# prefill
new_batch = init_batch(request_queue[:batch_capacity])
new_batch = generate_next_token(new_batch)
request_queue = request_queue[batch_capacity:]
# merge
cached_batch = merge_batches(cached_batch, new_batch)
# decode
cached_batch = generate_next_token(cached_batch)
# remove any inputs that have finished generation
cached_batch, removed_indices = filter_batch(cached_batch)
pbar.update(len(removed_indices))
duration_s = time.time() - t0
print("duration", duration_s)Quantization

Quantization helps reduce the memory overhead of a model and enables running inference with larger LLMs.
Zero point quantization
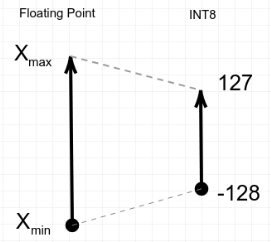
Zero-point quantization is a technique for converting the original floating point range into an 8-bit range (INT8).
Import required packages and load the LLM
import copy
import matplotlib.pyplot as plt
import numpy as np
import random
import time
import torch
import torch.nn.functional as F
from tqdm import tqdm
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.models.gpt2.modeling_gpt2 import GPT2Model
from utils import generate
model_name = "./models/gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Define PAD Token = EOS Token = 50256
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
# pad on the left so we can append new tokens on the right
tokenizer.padding_side = "left"
tokenizer.truncation_side = "left"Define a Float 32 type
# fix dtype post quantization to "pretend" to be fp32
def get_float32_dtype(self):
return torch.float32
GPT2Model.dtype = property(get_float32_dtype)
model.get_memory_footprint()Define a quantization function
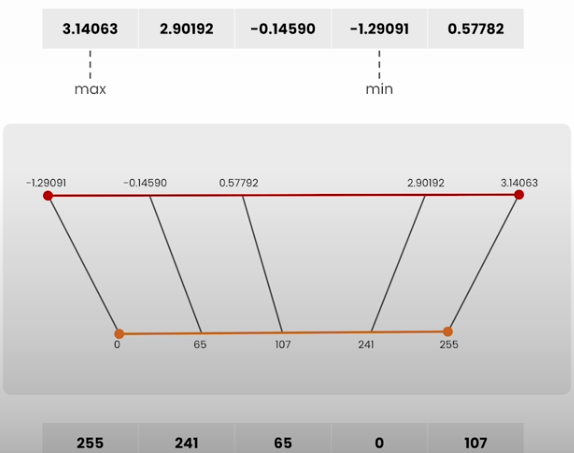
def quantize(t):
# obtain range of values in the tensor to map between 0 and 255
min_val, max_val = t.min(), t.max()
# determine the "zero-point", or value in the tensor to map to 0
scale = (max_val - min_val) / 255
zero_point = min_val
# quantize and clamp to ensure we're in [0, 255]
t_quant = (t - zero_point) / scale
t_quant = torch.clamp(t_quant, min=0, max=255)
# keep track of scale and zero_point for reversing quantization
state = (scale, zero_point)
# cast to uint8 and return
t_quant = t_quant.type(torch.uint8)
return t_quant, state
t = model.transformer.h[0].attn.c_attn.weight.data
print(t, t.shape)
t_q, state = quantize(t)
print(t_q, t_q.min(), t_q.max())Define a dequantization function
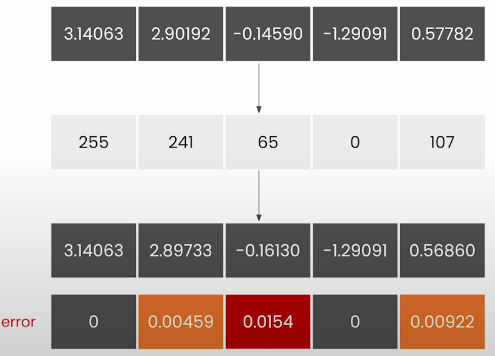
def dequantize(t, state):
scale, zero_point = state
return t.to(torch.float32) * scale + zero_point
t_rev = dequantize(t_q, state)
print(t_rev)
torch.abs(t - t_rev)
response_expected = generate(
model,
tokenizer,
[("The quick brown fox jumped over the", 10)]
)[0]
response_expectedLet’s apply the quantization technique to the entire model
def quantize_model(model):
states = {}
for name, param in model.named_parameters():
param.requires_grad = False
param.data, state = quantize(param.data)
states[name] = state
return model, states
quant_model, states = quantize_model(model)
quant_model.get_memory_footprint()
def size_in_bytes(t):
return t.numel() * t.element_size()
sum([
size_in_bytes(v[0]) + size_in_bytes(v[1])
for v in states.values()
])
def dequantize_model(model, states):
for name, param in model.named_parameters():
state = states[name]
param.data = dequantize(param.data, state)
return model
dequant_model = dequantize_model(quant_model, states)
dequant_model.get_memory_footprint()
response_expected = generate(
dequant_model,
tokenizer,
[("The quick brown fox jumped over the", 10)]
)[0]
response_expectedLow-Rank Adaptation (LoRA)
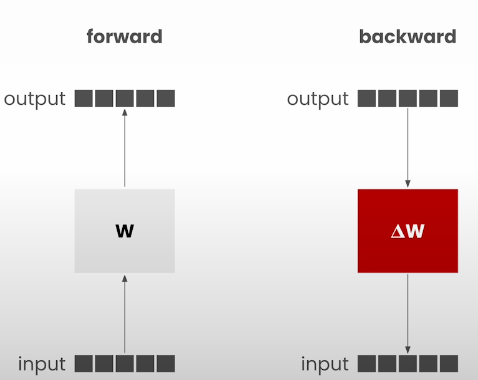
Let’s explore the idea of serving fine-tuned LLMs trained using Low-Rank Adaptation (LoRA).
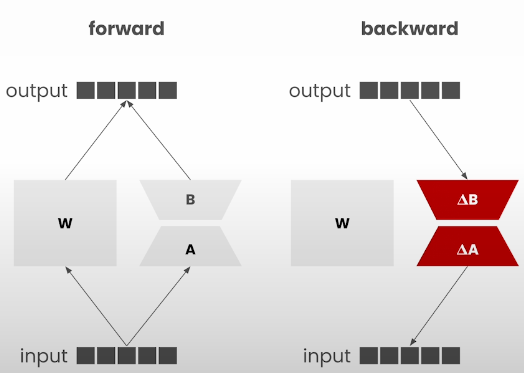
In Low-Rank Adaptation, we merely fine-tune the weight adapter. This allows us to save and share training results. Models can carry significant amounts of memory (e.g., a 7B model has 14GB memory). However, with this approach, adapters contain around ~20* parameter count MB, such as a 7B model's adapter, which holds 140 MB memory. You may also simply switch between adapters in runtime, eliminating the need to change models (model unloading and loading can take time).
Importing required packages:
import copy
import matplotlib.pyplot as plt
import numpy as np
import random
import time
import torch
import torch.nn.functional as F
from tqdm import tqdm
# set the seed so we get the same results from here on for each run
torch.manual_seed(42)Creating a test model:
class TestModel(torch.nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.embedding = torch.nn.Embedding(10, hidden_size)
self.linear = torch.nn.Linear(hidden_size, hidden_size)
self.lm_head = torch.nn.Linear(hidden_size, 10)
def forward(self, input_ids):
x = self.embedding(input_ids)
x = self.linear(x)
x = self.lm_head(x)
return x
# set a reasonably large hidden size to illustrate the small fraction of
# params needed to be added for LoRA
hidden_size = 1024
model = TestModel(hidden_size)
# dummy inputs
input_ids = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7]])
# toy example of a detokenizer.
# The vocabulary only consists of 10 words (different colors)
detokenizer = [
"red",
"orange",
"yellow",
"green",
"blue",
"indigo",
"violet",
"magenta",
"marigold",
"chartreuse",
]Reuse the generate token function from Lesson 2:
# this is the same generation step as we saw in lesson 2 (batching)
def generate_token(model, **kwargs):
with torch.no_grad():
logits = model(**kwargs)
last_logits = logits[:, -1, :]
next_token_ids = last_logits.argmax(dim=1)
return [detokenizer[token_id] for token_id in next_token_ids]
# generate one token
next_token = generate_token(model, input_ids=input_ids)[0]
next_token
# dummy input tensor
# shape: (batch_size, sequence_length, hidden_size)
X = torch.randn(1, 8, 1024)Let’s set up the LoRA computation:
# LoRA A and B tensors
# A has shape (hidden_size, rank)
# B has shape (rank, hidden_size)
lora_a = torch.randn(1024, 2)
lora_b = torch.randn(2, 1024)
W = model.linear.weight
W.shape
W2 = lora_a @ lora_b
W2.shape
# Compare number of elements of A and B with number of elements of W
# W here has shape (hidden_size, hidden_size)
lora_numel = lora_a.numel() + lora_b.numel()
base_numel = W.numel()
print("|A+B| / |W|:", lora_numel / base_numel)Let’s run the LoRA computation
# the @ symbol is used for matrix multiplication in Python
# compute the output of X @ W (the original linear layer)
base_output = model.linear(X)
# compute the output of X @ A @ B (the added lora adapter)
lora_output = X @ lora_a @ lora_b
# sum them together
total_output = base_output + lora_output
# output should have the same shape as the original output:
# (batch_size, sequence_length, hidden_size)
total_output.shape
class LoraLayer(torch.nn.Module):
def __init__(self, base_layer, r):
super().__init__()
self.base_layer = base_layer
d_in, d_out = self.base_layer.weight.shape
self.lora_a = torch.randn(d_in, r)
self.lora_b = torch.randn(r, d_out)
def forward(self, x):
y1 = self.base_layer(x)
y2 = x @ self.lora_a @ self.lora_b
return y1 + y2
# wrap the linear layer of our toy model, use rank 2
lora_layer = LoraLayer(model.linear, 2)
lora_layer(X).shape
model.linear = lora_layer
modelLet’s try the generated token after adding the LoRA layer:
next_token = generate_token(model, input_ids=input_ids)
next_token[0]Multi-LoRA inference
Example uses for several LoRAs:
1. Training on many types of data. For example, code completion assistants are trained on various sections of a code repository.
2. Combining many similar jobs. For example, automating customer service operations like ticket classification, priority, and routing.
3. Supporting several renters. For example, allowing several enterprise users to fine-tune and serve adapters from a single base model.
Import required packages
import copy
import matplotlib.pyplot as plt
import numpy as np
import random
import time
import torch
import torch.nn.functional as F
from tqdm import tqdmLet’s create a new model
We'll start by building an expansion to the model from lesson 5. It includes a new helper function for computing the LoRA layer step with several LoRAs in a batch.
class AbstractMultiLoraModel(torch.nn.Module):
def __init__(self):
super().__init__()
# hidden_size = 10
# set this so low to ensure we are not
# compute-bound by the linear layer
# this is only an issue when running on CPU,
# for GPUs we can set this much
# higher and still avoid being compute bound
self.embedding = torch.nn.Embedding(10, 10)
self.linear = torch.nn.Linear(10, 10)
self.lm_head = torch.nn.Linear(10, 10)
def linear_lora(
self,
x: torch.Tensor, # (batch_size, seq_len, in_features)
loras_a: torch.Tensor, # (num_loras, in_features, rank)
loras_b: torch.Tensor, # (num_loras, rank, out_features)
lora_indices: torch.LongTensor, # (batch_size,)
) -> torch.Tensor:
# y[i] = x[i] @ loras_a[lora_idx] @ loras_b[lora_idx]
raise NotImplementedError()
def forward(self, input_ids, loras_a, loras_b, lora_indices):
x = self.embedding(input_ids)
x = self.linear_lora(x, loras_a, loras_b, lora_indices)
x = self.lm_head(x)
return xUsing a loop
Our first attempt to infer across several LoRAs will be simple: loop over each row in the batch and apply the appropriate LoRA using an index mapping: 'batch_index → lora_index'.
class LoopMultiLoraModel(AbstractMultiLoraModel):
def linear_lora(
self,
x: torch.Tensor, # (batch_size, seq_len, in_features)
loras_a: torch.Tensor, # (num_loras, in_features, lora_rank)
loras_b: torch.Tensor, # (num_loras, lora_rank, out_features)
lora_indices: torch.LongTensor, # (batch_size,)
) -> torch.Tensor:
y = self.linear(x)
for batch_idx, lora_idx in enumerate(lora_indices.numpy()):
lora_a = loras_a[lora_idx]
lora_b = loras_b[lora_idx]
y[batch_idx] += x[batch_idx] @ lora_a @ lora_b
return y
# toy example of a detokenizer. The vocabular only consists of 10 words (different colors)
detokenizer = [
"red",
"orange",
"yellow",
"green",
"blue",
"indigo",
"violet",
"magenta",
"marigold",
"chartreuse",
]
# dummy inputs
input_ids = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7]])
torch.manual_seed(42)
def generate_token(model, **kwargs):
with torch.no_grad():
logits = model(**kwargs)
last_logits = logits[:, -1, :]
next_token_ids = last_logits.argmax(dim=1)
return [detokenizer[token_id] for token_id in next_token_ids]
model = LoopMultiLoraModel()Let’s try it!
We'll attempt this with a few random LoRAs and a fixed tensor of input_ids. If our multi-LoRA generating method is running well, we should get a range of distinct results as we iterate randomly across the LoRAs.
# constants
bs = 1
num_loras = 64
h = 10
r = 2
# create contiguous blocks for 64 random LoRA weights
loras_a = torch.randn(num_loras, h, r)
loras_b = torch.randn(num_loras, r, h)
for i in range(10):
# randomize the LoRAs each iteration
lora_indices = torch.randint(num_loras, (bs,), dtype=torch.long)
next_token = generate_token(
model,
input_ids=input_ids,
loras_a=loras_a,
loras_b=loras_b,
lora_indices=lora_indices,
)
print(next_token)Let’s benchmark our multi-LoRA system!
We will calculate the average delay to generate a single token as the batch size grows, and each element in the batch can have a different LoRA adaptor (selected at random).
# constants
seq_len = 8
vocab_size = 10
nsamples = 500
max_batch_size = 64
def benchmark(model):
avg_latencies = []
for bs in range(1, max_batch_size + 1):
latencies = []
for _ in range(nsamples):
# randomize the inputs and LoRA indices
input_ids = torch.randint(
vocab_size, (bs, seq_len), dtype=torch.long)
lora_indices = torch.randint(
num_loras, (bs,), dtype=torch.long)
# measure the end-to-end latency for
# generating a single token
t0 = time.time()
next_token = generate_token(
model,
input_ids=input_ids,
loras_a=loras_a,
loras_b=loras_b,
lora_indices=lora_indices,
)
latencies.append(time.time() - t0)
# average the latency across all the samples
latency_s = sum(latencies) / len(latencies)
avg_latencies.append(latency_s)
print(bs, latency_s)
return avg_latencies
avg_latencies_loop = benchmark(model)
Let’s visualize it!
x = list(range(1, max_batch_size + 1))
plt.plot(x, avg_latencies_loop, label="loop")
plt.xlabel('Batch Size')
plt.ylabel('Avg Latency (s)')
plt.title('Multi-LoRA latency w.r.t. batch size')
plt.legend()
plt.show()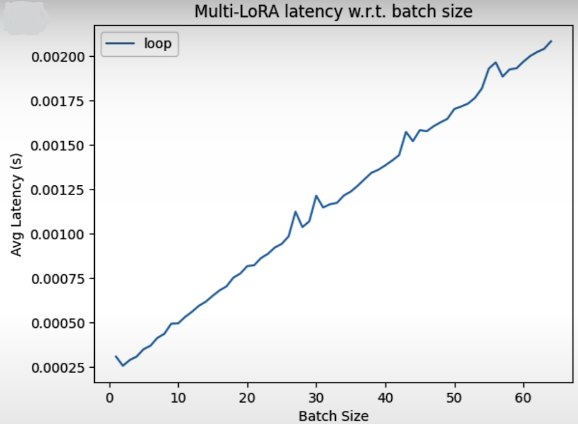
Let’s vectorize the LoRA computation
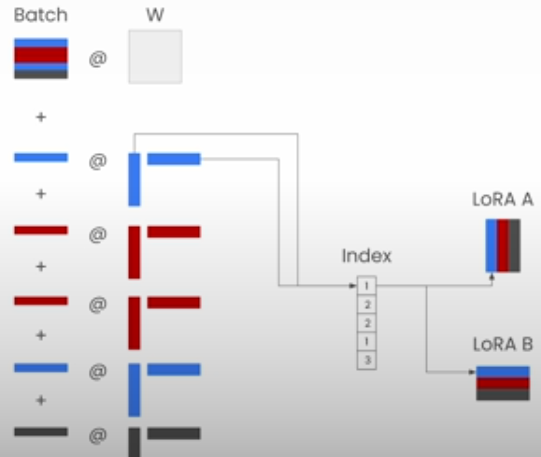
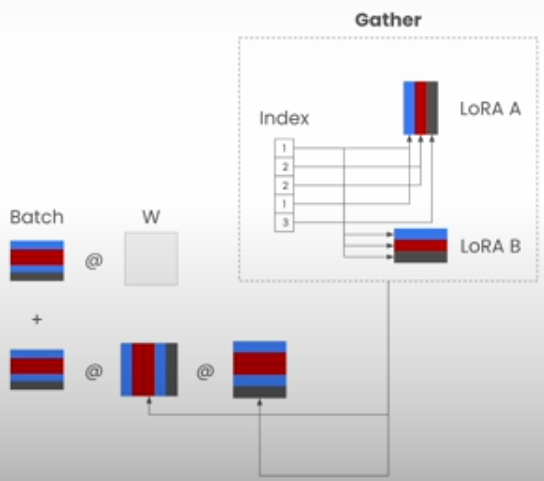
We shall vectorize the LoRA computation as follows:
1. Using 'torch.index_select', combine the LoRA weights from each batch into a single tensor.
2. Run the LoRA computation once for the full input tensor.
class GatheredMultiLoraModel(AbstractMultiLoraModel):
def linear_lora(
self,
x: torch.Tensor, # (batch_size, seq_len, in_features)
loras_a: torch.Tensor, # (num_loras, in_features, lora_rank)
loras_b: torch.Tensor, # (num_loras, lora_rank, out_features)
lora_indices: torch.LongTensor, # (batch_size,)
) -> torch.Tensor:
y = self.linear(x)
# gather the LoRA weights into a new tensor and apply
lora_a = torch.index_select(loras_a, 0, lora_indices) # (batch_size, in_features, lora_rank)
lora_b = torch.index_select(loras_b, 0, lora_indices) # (batch_size, lora_rank, out_features)
y += x @ lora_a @ lora_b
return y
model = GatheredMultiLoraModel()
avg_latencies_gathered = benchmark(model)Let’s visualize it!
x = list(range(1, max_batch_size + 1))
plt.plot(x, avg_latencies_loop, label="loop")
plt.plot(x, avg_latencies_gathered, label="gathered")
plt.xlabel('Batch Size')
plt.ylabel('Avg Latency (s)')
plt.title('Multi-LoRA latency w.r.t. batch size')
plt.legend()
plt.show()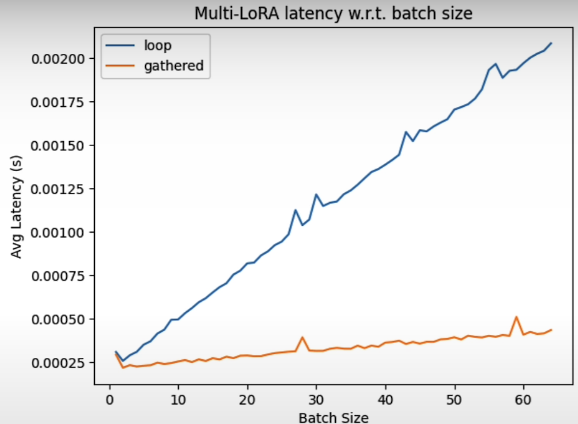
Additional optimization steps:
* Support LoRA adapters of varying grades.
* Support mixed batch requests with and without LoRA adapters.
* Improve the efficiency of the index selection step
* Organize by "segments" of the same specified LoRA adaptor to reduce duplicates in memory
* Implement as a CUDA kernel rather than in PyTorch for better performance.
LoRAX
import asyncio
import json
import time
from typing import List
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
from pydantic import BaseModel, constr
from lorax import AsyncClient, Client
from utils import endpoint_url, headers
client = Client(endpoint_url, headers=headers)Prefill vs Decode (KV Cache)
t0 = time.time()
resp = client.generate("What is deep learning?", max_new_tokens=32)
duration_s = time.time() - t0
print(resp.generated_text)
print("\n\n----------")
print("Request duration (s):", duration_s)
durations_s = []
t0 = time.time()
for resp in client.generate_stream("What is deep learning?", max_new_tokens=32):
durations_s.append(time.time() - t0)
if not resp.token.special:
print(resp.token.text, sep="", end="", flush=True)
t0 = time.time()
print("\n\n\n----------")
print("Time to first token (TTFT) (s):", durations_s[0])
print("Throughput (tok / s):", (len(durations_s) - 1) / sum(durations_s[1:]))
plt.plot(durations_s)
plt.show()Continuous Batching
color_codes = [
"31", # red
"32", # green
"34", # blue
]
def format_text(text, i):
return f"\x1b[{color_codes[i]}m{text}\x1b[0m"
async_client = AsyncClient(endpoint_url, headers=headers)
durations_s = [[], [], []]
async def run(max_new_tokens, i):
t0 = time.time()
async for resp in async_client.generate_stream("What is deep learning?", max_new_tokens=max_new_tokens):
durations_s[i].append(time.time() - t0)
print(format_text(resp.token.text, i), sep="", end="", flush=True)
t0 = time.time()
t0 = time.time()
all_max_new_tokens = [100, 10, 10]
await asyncio.gather(*[run(max_new_tokens, i) for i, max_new_tokens in enumerate(all_max_new_tokens)])
print("\n\n\n----------")
print("Time to first token (TTFT) (s):", [s[0] for s in durations_s])
print("Throughput (tok / s):", [(len(s) - 1) / sum(s[1:]) for s in durations_s])
print("Total duration (s):", time.time() - t0)Multi-LoRA
def run_with_adapter(prompt, adapter_id):
durations_s = []
t0 = time.time()
for resp in client.generate_stream(
prompt,
adapter_id=adapter_id,
adapter_source="hub",
max_new_tokens=64,
):
durations_s.append(time.time() - t0)
if not resp.token.special:
print(resp.token.text, sep="", end="", flush=True)
t0 = time.time()
print("\n\n\n----------")
print("Time to first token (TTFT) (s):", durations_s[0])
print("Throughput (tok / s):", (len(durations_s) - 1) / sum(durations_s[1:]))
pt_hellaswag_processed = \
"""You are provided with an incomplete passage below. Please read the passage and then finish it with an appropriate response. For example:
### Passage: My friend and I think alike. We
### Ending: often finish each other's sentences.
Now please finish the following passage:
### Passage: {ctx}
### Ending: """
ctx = "Numerous people are watching others on a field. Trainers are playing frisbee with their dogs. the dogs"
run_with_adapter(pt_hellaswag_processed.format(ctx=ctx), adapter_id="predibase/hellaswag_processed")
pt_cnn = \
"""You are given a news article below. Please summarize the article, including only its highlights.
### Article: {article}
### Summary: """
article = "(CNN)Former Vice President Walter Mondale was released from the Mayo Clinic on Saturday after being admitted with influenza, hospital spokeswoman Kelley Luckstein said. \"He's doing well. We treated him for flu and cold symptoms and he was released today,\" she said. Mondale, 87, was diagnosed after he went to the hospital for a routine checkup following a fever, former President Jimmy Carter said Friday. \"He is in the bed right this moment, but looking forward to come back home,\" Carter said during a speech at a Nobel Peace Prize Forum in Minneapolis. \"He said tell everybody he is doing well.\" Mondale underwent treatment at the Mayo Clinic in Rochester, Minnesota. The 42nd vice president served under Carter between 1977 and 1981, and later ran for President, but lost to Ronald Reagan. But not before he made history by naming a woman, U.S. Rep. Geraldine A. Ferraro of New York, as his running mate. Before that, the former lawyer was a U.S. senator from Minnesota. His wife, Joan Mondale, died last year."
run_with_adapter(pt_cnn.format(article=article), adapter_id="predibase/cnn")
pt_conllpp = """
Your task is a Named Entity Recognition (NER) task. Predict the category of
each entity, then place the entity into the list associated with the
category in an output JSON payload. Below is an example:
Input: EU rejects German call to boycott British lamb . Output: {{"person":
[], "organization": ["EU"], "location": [], "miscellaneous": ["German",
"British"]}}
Now, complete the task.
Input: {inpt} Output:"""
inpt = "Only France and Britain backed Fischler 's proposal ."
run_with_adapter(pt_conllpp.format(inpt=inpt), adapter_id="predibase/conllpp")
durations_s = [[], [], []]
async def run(prompt, adapter_id, i):
t0 = time.time()
async for resp in async_client.generate_stream(
prompt,
adapter_id=adapter_id,
adapter_source="hub",
max_new_tokens=64,
):
durations_s[i].append(time.time() - t0)
if not resp.token.special:
print(format_text(resp.token.text, i), sep="", end="", flush=True)
t0 = time.time()
t0 = time.time()
prompts = [
pt_hellaswag_processed.format(ctx=ctx),
pt_cnn.format(article=article),
pt_conllpp.format(inpt=inpt),
]
adapter_ids = ["predibase/hellaswag_processed", "predibase/cnn", "predibase/conllpp"]
await asyncio.gather(*[run(prompt, adapter_id, i)
for i, (prompt, adapter_id) in enumerate(zip(prompts, adapter_ids))])
print("\n\n\n----------")
print("Time to first token (TTFT) (s):", [s[0] for s in durations_s])
print("Throughput (tok / s):", [(len(s) - 1) / sum(s[1:]) for s in durations_s])
print("Total duration (s):", time.time() - t0)Bonus: Structured Generation
from pydantic import BaseModel, constr
class Person(BaseModel):
name: constr(max_length=10)
age: int
schema = Person.schema()
resp = client.generate(
"Create a person description for me",
response_format={"type": "json_object", "schema": schema}
)
json.loads(resp.generated_text)
prompt_template = """
Your task is a Named Entity Recognition (NER) task. Predict the category of
each entity, then place the entity into the list associated with the
category in an output JSON payload. Below is an example:
Input: EU rejects German call to boycott British lamb . Output: {{"person":
[], "organization": ["EU"], "location": [], "miscellaneous": ["German",
"British"]}}
Now, complete the task.
Input: {input} Output:"""
# Base Mistral-7B
resp = client.generate(
prompt_template.format(input="Only France and Britain backed Fischler 's proposal ."),
max_new_tokens=128,
)
resp.generated_text
from typing import List
class Output(BaseModel):
person: List[str]
organization: List[str]
location: List[str]
miscellaneous: List[str]
schema = Output.schema()
resp = client.generate(
prompt_template.format(input="Only France and Britain backed Fischler 's proposal ."),
response_format={
"type": "json_object",
"schema": schema,
},
max_new_tokens=128,
)
json.loads(resp.generated_text)
resp = client.generate(
prompt_template.format(input="Only France and Britain backed Fischler 's proposal ."),
adapter_id="predibase/conllpp",
adapter_source="hub",
max_new_tokens=128,
)
json.loads(resp.generated_text)Additional Predibase Resources:
- LoRA Land demo environment: https://predibase.com/lora-land
- Predibase blog articles: https://predibase.com/blog
- LoRAX Github repo: https://github.com/predibase/lorax
Resource
[1] Deeplearning.ai, (2024), Efficiently Serving LLMs:
[https://learn.deeplearning.ai/courses/efficiently-serving-llms/]
0 Comments