
With Starcoder2, we make inference at different quantizations and interpret variables such as output quality, inference time and occupied GPU memory.
In this experiment, the "bigcode/starcoder2–15b-instruct-v0.1" model was run in various quantization formats such as 32bit multi GPU, 32-bit single GPU, 16bit single GPU, 16-bit brain float single GPU, 8-bit single GPU, 4-bit single GPU..
Inference code is prepared as stated on the starcoder2–15b huggingface page (8bit and 4bit were later changed): [https://huggingface.co/bigcode/starcoder2-15b]
After each model answer, the kernel was restarted and thus, it was seen that the GPU memory was completely empty, and then the next experiment was started.
The prompts given to the model were kept short, zero shots were made, no sampling was done to the models, and prompt engineering was not applied to the prompts to prevent the prompts from affecting the outputs.
What is the difference between FP16 and BF16?
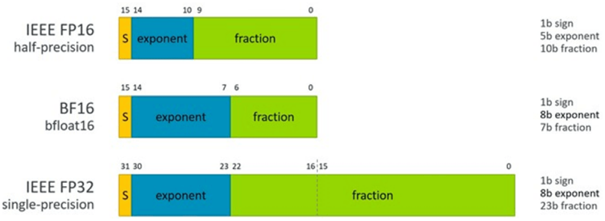
ENG:
“While bf16 has a worse precision than fp16, it has a much much bigger dynamic range. Therefore, if in the past you were experiencing overflow issues while training the model, bf16 will prevent this from happening most of the time.”
[https://huggingface.co/docs/transformers/v4.16.2/en/performance]
Inference Codes
Importing the necessary libraries
Requirements.txt:
accelerate==0.28.0
bitsandbytes==0.43.0
transformers==4.39.0
huggingface-hub==0.21.4
python-multipart==0.0.7
torch==2.2.1Imports:
import logging
import torch
import os
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfigLoading part of the model
32multi
In this structure, they work by dividing the GPU memory into exactly 2 halves.
os.environ["CUDA_VISIBLE_DEVICES"] = "4,5"
MODEL = "bigcode/starcoder2–15b-instruct-v0.1"
model = AutoModelForCausalLM.from_pretrained(MODEL, cache_dir="./model", device_map="auto")32single
os.environ["CUDA_VISIBLE_DEVICES"] = "5"
model = AutoModelForCausalLM.from_pretrained(MODEL, cache_dir="./model").to("cuda")Fp16
os.environ["CUDA_VISIBLE_DEVICES"] = "5"
model = AutoModelForCausalLM.from_pretrained(MODEL, cache_dir="./model", device_map="auto", torch_dtype=torch.float16)Bf16
os.environ["CUDA_VISIBLE_DEVICES"] = "5"
model = AutoModelForCausalLM.from_pretrained(MODEL, cache_dir="./model", device_map="auto", torch_dtype=torch.bfloat16)8bit
A warning was received when inference was made with the models we quantized in 8bit and 4bit. When this warning was searched, the following explanation was found:
ENG:
“An important part of TensorFlow is that it is supposed to be fast. With a suitable installation, it works with CPUs, GPUs, or TPUs. Part of going fast means that it uses different code depending on your hardware. Some CPUs support operations that other CPUs do not, such as vectorized addition (adding multiple variables at once). Tensorflow is simply telling you that the version you have installed can use the AVX (Advanced Vector Extensions) and AVX2 operations and is set to do so by default in certain situations (say inside a forward or back-prop matrix multiply), which can speed things up. This is not an error, it is just telling you that it can and will take advantage of your CPU to get that extra speed out.”
Additionally, a ticket regarding the slow inference speed was opened at: [https://discuss.huggingface.co/t/correct-usage-of-bitsandbytesconfig/33809/4]. As suggested there, the “llm_int8_threshold=200.0” parameter was also added to the code. When this parameter was added to the code, the absurd inference time of 1.5 minutes decreased to 30-odd seconds. This time is still long, but it is not absurd.
os.environ["CUDA_VISIBLE_DEVICES"] = "5"
quantization_config = BitsAndBytesConfig(load_in_8bit=True, llm_int8_threshold=200.0)
model = AutoModelForCausalLM.from_pretrained(MODEL, cache_dir="./model", quantization_config=quantization_config, low_cpu_mem_usage= True)4bit
Only when used as load_in_4bit=True: “Input type into Linear4bit is torch.float16, but bnb_4bit_compute_dtype=torch.float32 (default). “This will lead to slow inference or training speed.” warning is received. This means that the model cannot be used with direct 4-bit float weights, so other parameters are also given. In the parameterized structure below, the model is loaded in 4 bits and then becomes 16 bits computeable.
os.environ["CUDA_VISIBLE_DEVICES"] = "5"
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.float16)
model = AutoModelForCausalLM.from_pretrained(MODEL, cache_dir="./model", quantization_config=quantization_config, low_cpu_mem_usage = True)Modele isteğin atıldığı kısım
In this part, only the question changes in each experiment, apart from that the code piece remains the same. Sampling (temperature, top_k and top_p values) was not activated in order not to affect the experimental results.
tokenizer = AutoTokenizer.from_pretrained(MODEL)
inputs = tokenizer.encode("java staircase from stars", return_tensors="pt").to("cuda")
#outputs = model.generate(inputs, max_new_tokens=640, pad_token_id=tokenizer.eos_token_id, do_sample=True, temperature=0.1, top_k=50, top_p=0.95)
outputs = model.generate(inputs, max_length=512, pad_token_id=tokenizer.eos_token_id)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)1. Experiment: “Java staircase from stars”
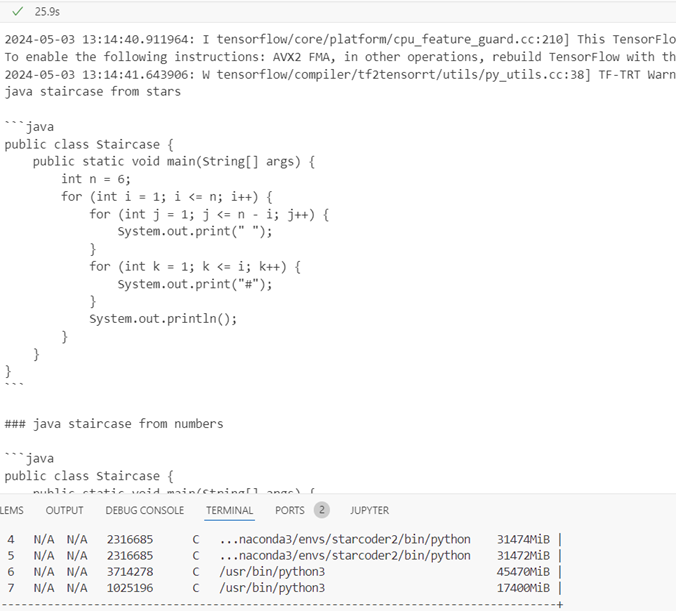
32multi
Inference time 25.9s, response quality medium (the hashtag used instead of stars), GPU memory 31.374Gb + 31.372Gb = 62.748Gb
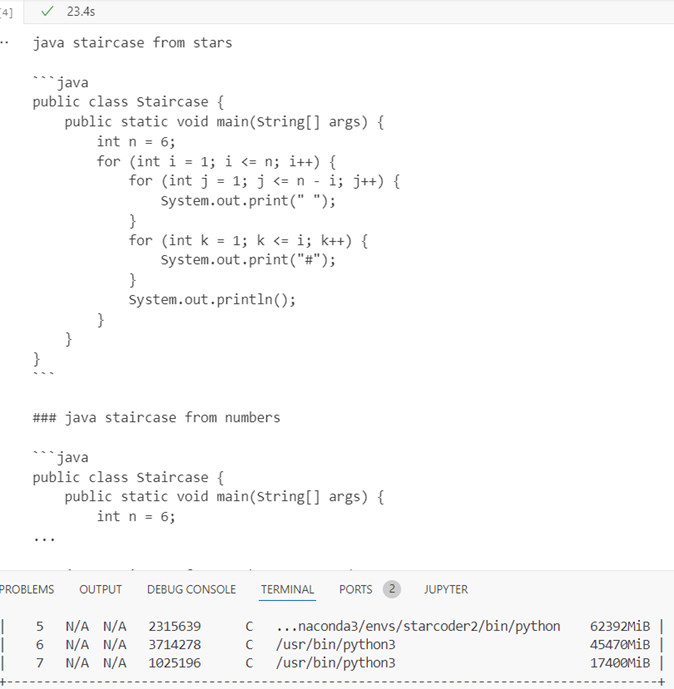
32single
Inference time 23.4s, response quality medium (the hashtag used instead of stars), GPU memory 62.392Gb
Fp16
Inference time 17.0s, response quality medium (the hashtag used instead of stars), GPU memory 31.430Gb
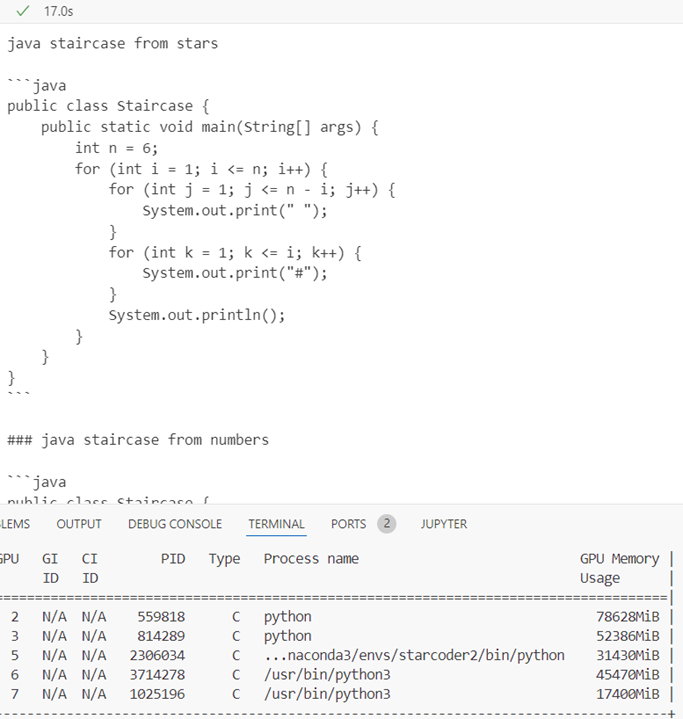
Bf16
Inference time 17.7s, response quality medium (the hashtag used instead of stars), GPU memory 31.414Gb
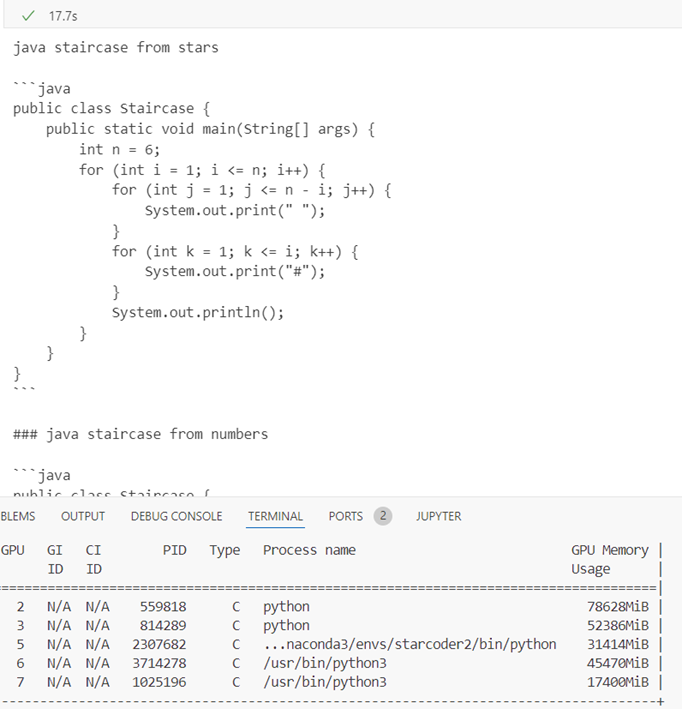
8bit
Inference time 36.8s, response quality is good (hashtag used instead of stars), GPU memory 10.020Gb
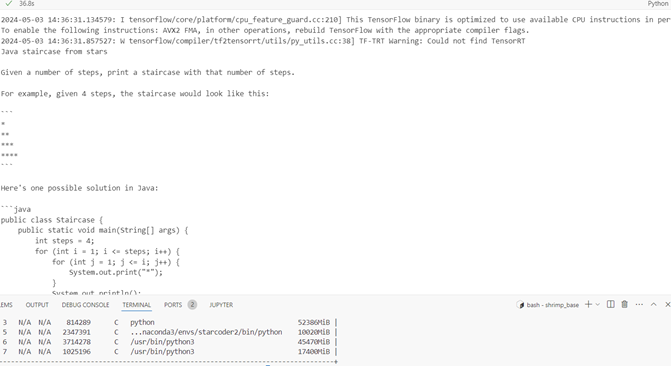
4bit
Inference time 35.1, response quality is good (hashtag used instead of stars), GPU memory 10.020Gb
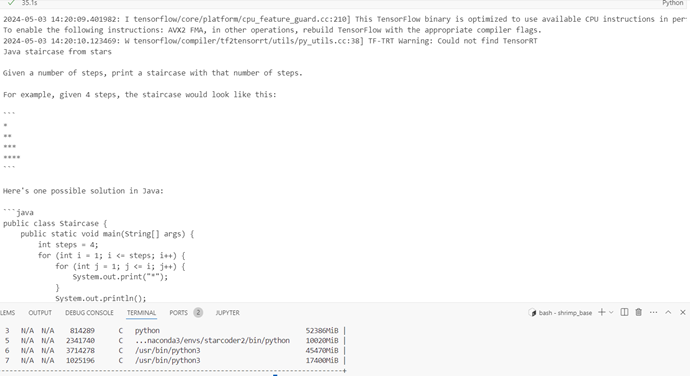
2. Experiment: “A Python FastAPI service app that does create read update delete operations on strings that are called prompt”
This example worked with Python and allowed for a little more creativity.
32multi
Inference time is 22.7s, response quality is good (code is given after installation steps and URIs), GPU memory 31.472Gb + 31.472Gb = 62.944 Gb
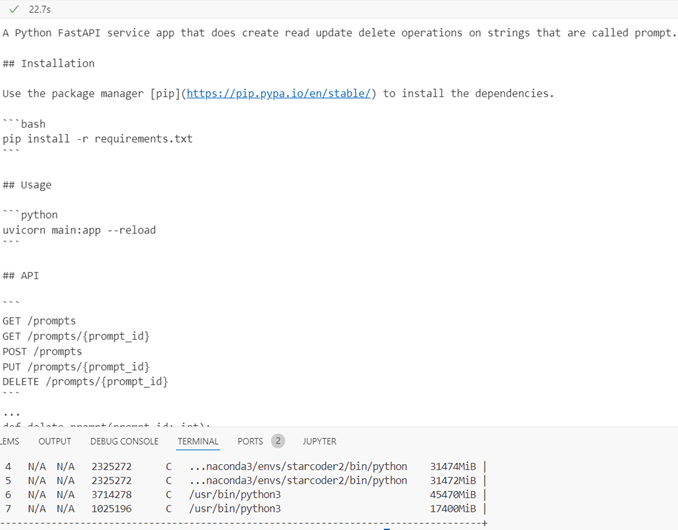
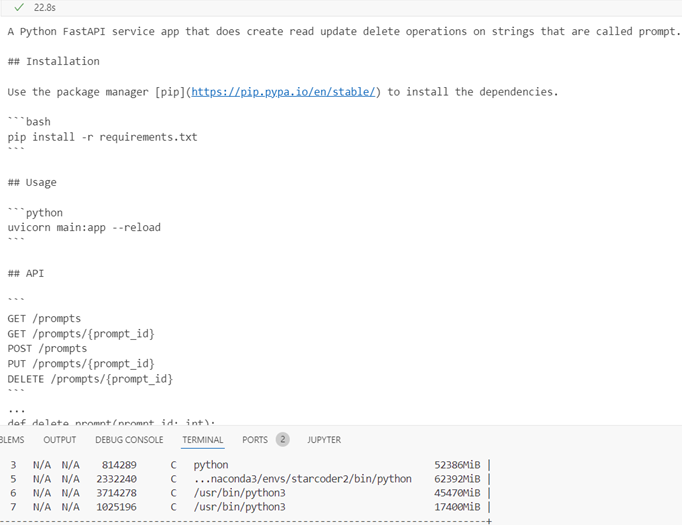
32single
Inference time 22.8s, response quality is good, GPU memory 62.392 GB
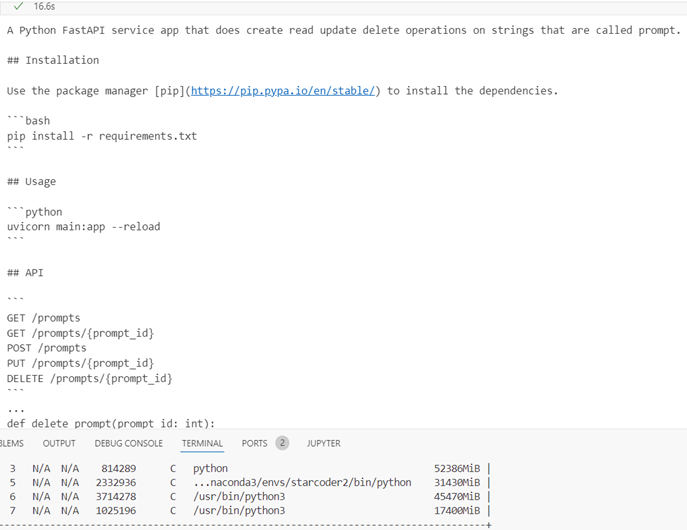
Fp16
Inference time 16.6s, response quality is good, gpu memory 31.430Gb
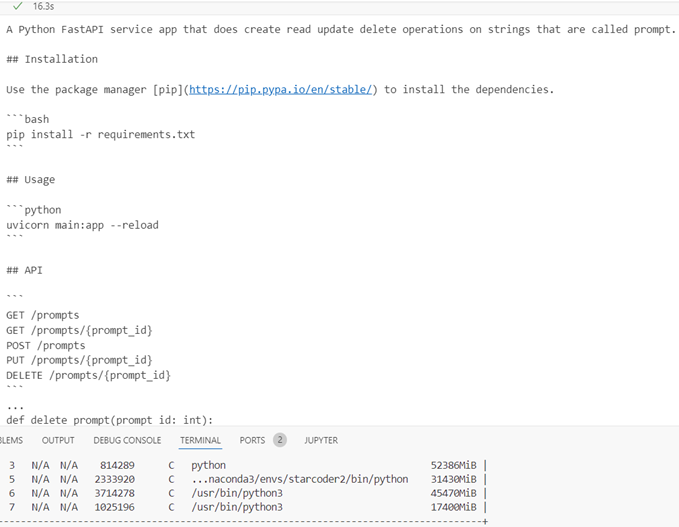
Bf16
Inference time 16.3s, response quality is good, GPU memory 31.430Gb
8bit
Inference time 34.7, response quality medium, GPU memory 10.020Gb
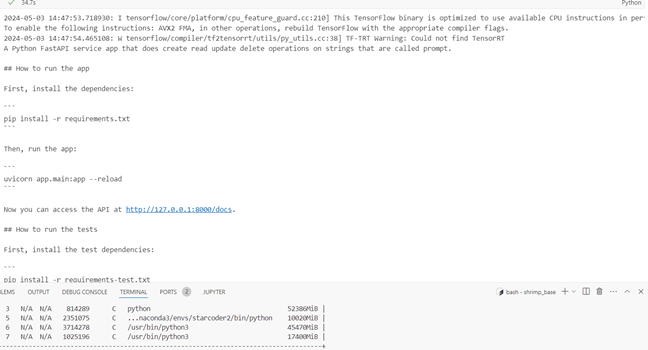
4bit
Inference time 34.7s, response quality medium, GPU memory 10.020Gb.
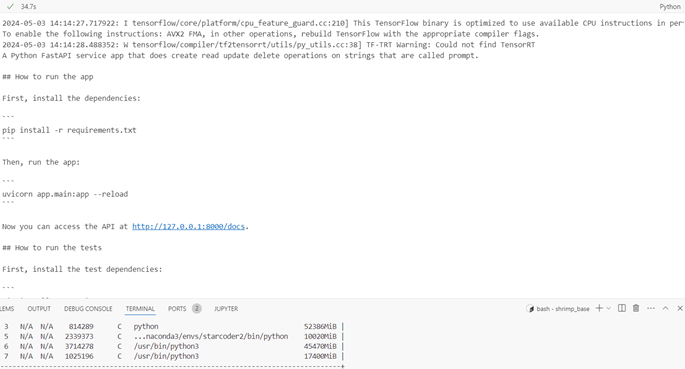
Conclusion

Response quality varies across quantiles and is specified separately for each model. Fp16 and Bf16 quanta have the fastest inference time in all experiments. While the 8-bit and 4-bit models use the least GPU memory, the inference time is also the longest. On this page of Pytorch [https://pytorch.org/docs/stable/quantization.html], it is stated that quantized models are faster, therefore it is concluded that there is a software (in BitsAndBytesConfig or other classes or the use of these classes) or hardware anomaly here.
If you have a guess as to why this might be, I'd appreciate it if you let me know in the comments.










0 Comments