
Turkish summary of the Deeplearning.ai "Building Agentic RAG with Llamaindex" course.

We will learn how to create an Agentic RAG, which is a framework for creating research agents capable of reasoning and making decisions based on data.
For example, extracting a portion of a set of research papers based on the input's relevancy is a difficult request that necessitates numerous processing steps. The typical RAG pipeline is suitable for a modest number of documents with straightforward queries. By completing this course, you will be able to take speaking with your papers to the next level by creating autonomous research agents.
First, routing incorporates decision-making to route requests to multiple tools. The next step is tool use, which involves creating an interface for agents to select tools and generate the appropriate arguments for those tools. Finally, there is multi-step reasoning using tools. We will use LLM to execute multi-step reasoning and a variety of tools to retain the memory of that process.
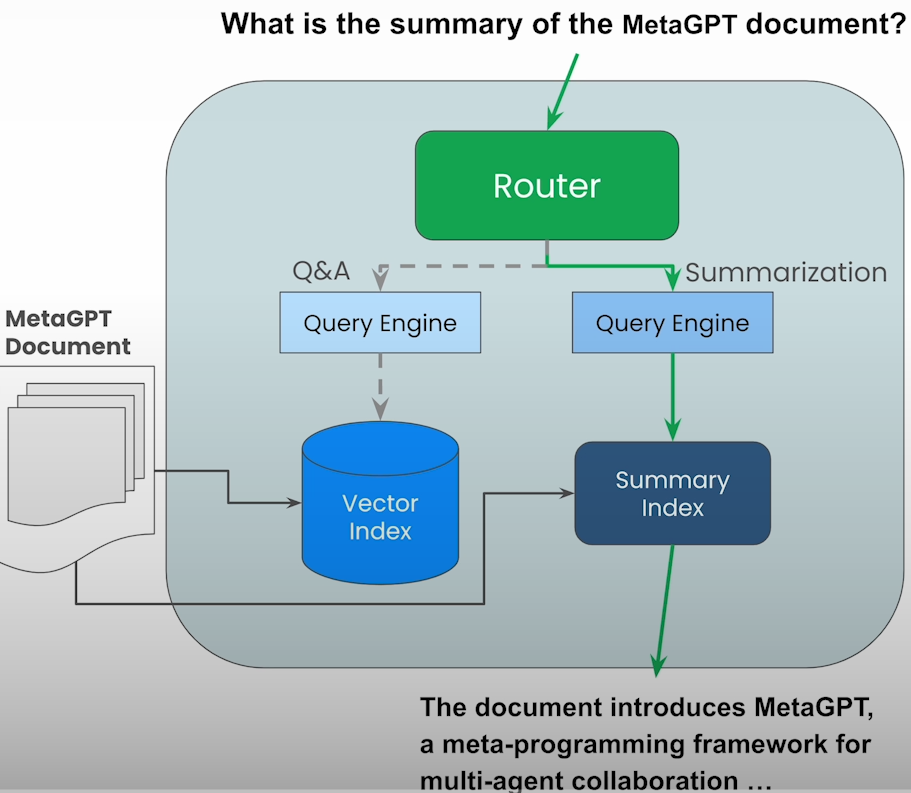
Router Query Engine
Given a query, a router will select one of multiple query engines to perform it. You'll create a small router over a single document that can handle both question answering and summarization.
from helper import get_openai_api_key
OPENAI_API_KEY = get_openai_api_key()
import nest_asyncio
nest_asyncio.apply()Load Data
To download this pdf, use the following code:
!wget “https://openreview.net/pdf?id=VtmBAGCN7o" -O metagpt.pdf
from llama_index.core import SimpleDirectoryReader
# load documents
documents = SimpleDirectoryReader(input_files=["metagpt.pdf"]).load_data()Define LLM and Embedding model
from llama_index.core.node_parser import SentenceSplitter
splitter = SentenceSplitter(chunk_size=1024)
nodes = splitter.get_nodes_from_documents(documents)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
Settings.llm = OpenAI(model="gpt-3.5-turbo")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")Define Summary Index and Vector Index over the Same Data
from llama_index.core import SummaryIndex, VectorStoreIndex
summary_index = SummaryIndex(nodes)
vector_index = VectorStoreIndex(nodes)Define Query Engines and Set Metadata
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
vector_query_engine = vector_index.as_query_engine()
from llama_index.core.tools import QueryEngineTool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to MetaGPT"
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the MetaGPT paper."
),
)Selectors
There are various selectors at your disposal:
The LLM selectors query the associated indexes after using the LLM to produce a parsed JSON result.
Rather than processing raw JSON, the Pydantic selectors employ the OpenAI function calling API to create Pydantic selection objects.
Define Router Query Engine
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=True
)
response = query_engine.query("What is the summary of the document?")
print(str(response))
print(len(response.source_nodes)) # 34
response = query_engine.query(
"How do agents share information with other agents?"
)
print(str(response))
Putting everything together
from utils import get_router_query_engine
query_engine = get_router_query_engine("metagpt.pdf")
response = query_engine.query("Tell me about the ablation study results?")
print(str(response))
Tool Calling
How to utilize an LLM to determine which function to run and how to deduce which parameter to pass via the function.
Tool calling helps identify the right tool and infers required arguments for execution, allowing LLMs to communicate with external environments through a dynamic interface. LLMs are primarily utilized in typical RAG for information synthesis. By adding a layer of query comprehension to a RAG pipeline, tool calling allows users to ask sophisticated questions and receive more accurate answers.
from helper import get_openai_api_key
OPENAI_API_KEY = get_openai_api_key()
import nest_asyncio
nest_asyncio.apply()Define a simple tool
from llama_index.core.tools import FunctionTool
def add(x: int, y: int) -> int:
"""Adds two integers together."""
return x + y
def mystery(x: int, y: int) -> int:
"""Mystery function that operates on top of two numbers."""
return (x + y) * (x + y)
add_tool = FunctionTool.from_defaults(fn=add)
mystery_tool = FunctionTool.from_defaults(fn=mystery)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
response = llm.predict_and_call(
[add_tool, mystery_tool],
"Tell me the output of the mystery function on 2 and 9",
verbose=True
)
print(str(response))
Define an Auto-Retrieval Tool
Loading the data
!wget “https://openreview.net/pdf?id=VtmBAGCN7o" -O metagpt.pdf
from llama_index.core import SimpleDirectoryReader
# load documents
documents = SimpleDirectoryReader(input_files=["metagpt.pdf"]).load_data()
from llama_index.core.node_parser import SentenceSplitter
splitter = SentenceSplitter(chunk_size=1024)
nodes = splitter.get_nodes_from_documents(documents)
print(nodes[0].get_content(metadata_mode="all"))
from llama_index.core import VectorStoreIndex
vector_index = VectorStoreIndex(nodes)
query_engine = vector_index.as_query_engine(similarity_top_k=2)
from llama_index.core.vector_stores import MetadataFilters
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
[
{"key": "page_label", "value": "2"}
]
)
)
response = query_engine.query(
"What are some high-level results of MetaGPT?",
)
print(str(response))
for n in response.source_nodes:
print(n.metadata)
Enhancing Data Retrieval
incorporating metadata filters into the function of a retrieval tool. This function takes a query text as input and optional metadata filters (such page number) to allow for more accurate retrieval. Based on the user's query, the LLM can intelligently infer pertinent metadata filters (such page numbers). Different kinds of metadata filters, such as section IDs, headers, and footers, can be defined.
Define the Auto-Retrieval Tool
from typing import List
from llama_index.core.vector_stores import FilterCondition
def vector_query(
query: str,
page_numbers: List[str]
) -> str:
"""Perform a vector search over an index.
query (str): the string query to be embedded.
page_numbers (List[str]): Filter by set of pages. Leave BLANK if we want to perform a vector search
over all pages. Otherwise, filter by the set of specified pages.
"""
metadata_dicts = [
{"key": "page_label", "value": p} for p in page_numbers
]
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
metadata_dicts,
condition=FilterCondition.OR
)
)
response = query_engine.query(query)
return response
vector_query_tool = FunctionTool.from_defaults(
name="vector_tool",
fn=vector_query
)
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
response = llm.predict_and_call(
[vector_query_tool],
"What are the high-level results of MetaGPT as described on page 2?",
verbose=True
)
for n in response.source_nodes:
print(n.metadata)
Adding other tools
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineTool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(
name="summary_tool",
query_engine=summary_query_engine,
description=(
"Useful if you want to get a summary of MetaGPT"
),
)
response = llm.predict_and_call(
[vector_query_tool, summary_tool],
"What are the MetaGPT comparisons with ChatDev described on page 8?",
verbose=True
)

for n in response.source_nodes:
print(n.metadata)
response = llm.predict_and_call(
[vector_query_tool, summary_tool],
"What is a summary of the paper?",
verbose=True
)
Building an Agent Reasoning Loop
We will learn how to handle user inquiries that call for several steps in this class.
from helper import get_openai_api_key
OPENAI_API_KEY = get_openai_api_key()
import nest_asyncio
nest_asyncio.apply()
!wget "https://openreview.net/pdf?id=VtmBAGCN7o" -O metagpt.pdfSetup the Query Tools
from utils import get_doc_tools
vector_tool, summary_tool = get_doc_tools("metagpt.pdf", "metagpt")Setup Function Calling Agent
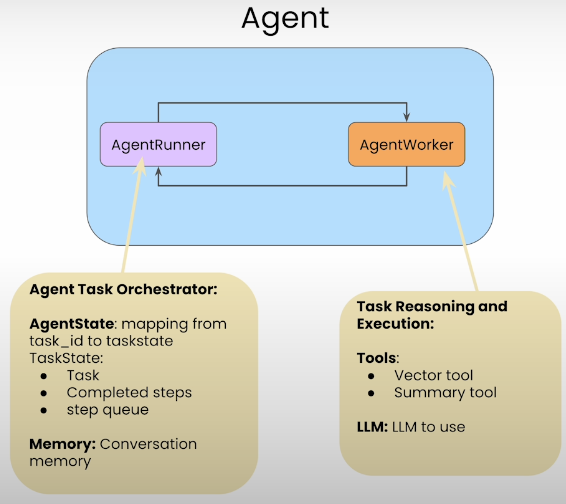
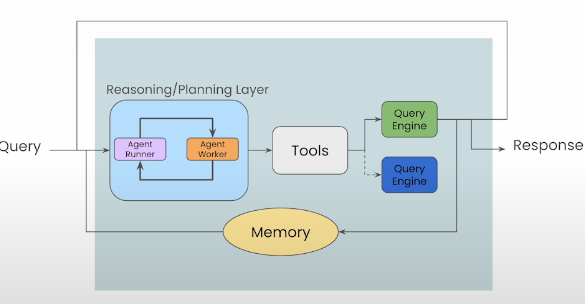
AgentWorker and AgentRunner are the two interoperating parts of Llamaindex agents. Using an LLM and the provided tools—in this case, the vector and summary tools—AgentWorker performs reasoning and task execution. The agent that handles the orchestration is called AgentRunner. Task_id to TaskState mapping, conversation memory, and AgentState are features of AgentRunner. Tasks, finished steps, and a step queue make up TaskState.
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
response = agent.query(
"Tell me about the agent roles in MetaGPT, "
"and then how they communicate with each other."
)
print(response.source_nodes[0].get_content(metadata_mode="all"))
Full Agent Reasoning Loop
It is possible to configure memory modules. By default, memory is a flat list of objects.
response = agent.chat(
"Tell me about the evaluation datasets used."
)
response = agent.chat("Tell me the results over one of the above datasets.")
Agent Control
We can steer and debug the outcome by manipulating the agent's action flow.
The principal advantages:
Decoupling Task Creation and Execution: This gives users the freedom to plan task completion times based on their requirements.
Improved Debuggability: Provides more in-depth understanding of every stage of the execution process, enhancing the ability to troubleshoot.
Steerability: Provides users with the ability to adjust intermediate steps directly and integrates human feedback for more precise control.
Lower-Level: Debuggability and Control
agent_worker = FunctionCallingAgentWorker.from_tools(
[vector_tool, summary_tool],
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
task = agent.create_task(
"Tell me about the agent roles in MetaGPT, "
"and then how they communicate with each other."
)
step_output = agent.run_step(task.task_id)
completed_steps = agent.get_completed_steps(task.task_id)
print(f"Num completed for task {task.task_id}: {len(completed_steps)}")
print(completed_steps[0].output.sources[0].raw_output)
upcoming_steps = agent.get_upcoming_steps(task.task_id)
print(f"Num upcoming steps for task {task.task_id}: {len(upcoming_steps)}")
upcoming_steps[0]
step_output = agent.run_step(
task.task_id, input="What about how agents share information?"
)
step_output = agent.run_step(task.task_id)
print(step_output.is_last) # True or False by if it is the last step or not
response = agent.finalize_response(task.task_id)
print(str(response))
Building a Multi-Document Agent
We developed an agent that can retain memory while reasoning over a single document and providing sophisticated answers. This section will cover how to expand the agent's capabilities to manage more documents and progressively higher levels of complexity. Three documents will be the first, and eventually there will be eleven.
from helper import get_openai_api_key
OPENAI_API_KEY = get_openai_api_key()
import nest_asyncio
nest_asyncio.apply()Setup an agent over 3 papers
In this part, you can ask any question or summarization of the combination of the 3 documents.
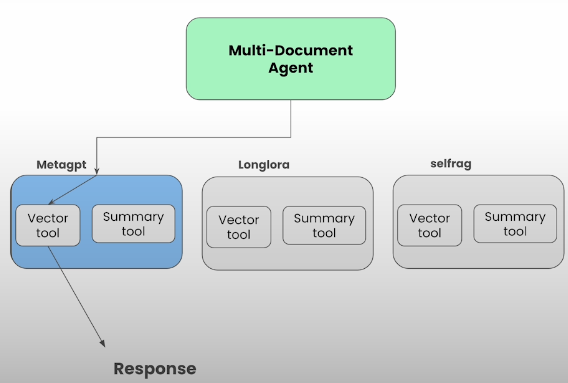
urls = [
"https://openreview.net/pdf?id=VtmBAGCN7o",
"https://openreview.net/pdf?id=6PmJoRfdaK",
"https://openreview.net/pdf?id=hSyW5go0v8",
]
papers = [
"metagpt.pdf",
"longlora.pdf",
"selfrag.pdf",
]
from utils import get_doc_tools # helper function that automatically builds both vector and summary index tools
from pathlib import Path
paper_to_tools_dict = {}
for paper in papers:
print(f"Getting tools for paper: {paper}")
vector_tool, summary_tool = get_doc_tools(paper, Path(paper).stem)
paper_to_tools_dict[paper] = [vector_tool, summary_tool]
initial_tools = [t for paper in papers for t in paper_to_tools_dict[paper]]
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
len(initial_tools) # 6
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
initial_tools,
llm=llm,
verbose=True
)
agent = AgentRunner(agent_worker)
response = agent.query(
"Tell me about the evaluation dataset used in LongLoRA, "
"and then tell me about the evaluation results"
)
response = agent.query("Give me a summary of both Self-RAG and LongLoRA")
print(str(response))Setup an agent over 11 papers
# Downloading 11 ICLR papers
urls = [
"https://openreview.net/pdf?id=VtmBAGCN7o",
"https://openreview.net/pdf?id=6PmJoRfdaK",
"https://openreview.net/pdf?id=LzPWWPAdY4",
"https://openreview.net/pdf?id=VTF8yNQM66",
"https://openreview.net/pdf?id=hSyW5go0v8",
"https://openreview.net/pdf?id=9WD9KwssyT",
"https://openreview.net/pdf?id=yV6fD7LYkF",
"https://openreview.net/pdf?id=hnrB5YHoYu",
"https://openreview.net/pdf?id=WbWtOYIzIK",
"https://openreview.net/pdf?id=c5pwL0Soay",
"https://openreview.net/pdf?id=TpD2aG1h0D"
]
papers = [
"metagpt.pdf",
"longlora.pdf",
"loftq.pdf",
"swebench.pdf",
"selfrag.pdf",
"zipformer.pdf",
"values.pdf",
"finetune_fair_diffusion.pdf",
"knowledge_card.pdf",
"metra.pdf",
"vr_mcl.pdf"
]# To download these papers, below is the needed code:
for url, paper in zip(urls, papers):
!wget "{url}" -O "{paper}"from utils import get_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
for paper in papers:
print(f"Getting tools for paper: {paper}")
vector_tool, summary_tool = get_doc_tools(paper, Path(paper).stem)
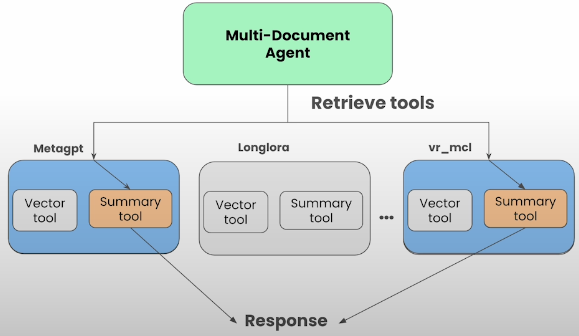
paper_to_tools_dict[paper] = [vector_tool, summary_tool]Extend the Agent with Tool Retrieval
all_tools = [t for paper in papers for t in paper_to_tools_dict[paper]]
# define an "object" index and retriever over these tools
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
obj_index = ObjectIndex.from_objects(
all_tools,
index_cls=VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)
tools = obj_retriever.retrieve(
"Tell me about the eval dataset used in MetaGPT and SWE-Bench"
)
tools[1].metadata
The most similar 3 tools are retrieved according to the request. Optionally you can define system prompt too.
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tool_retriever=obj_retriever,
llm=llm,
system_prompt=""" \
You are an agent designed to answer queries over a set of given papers.
Please always use the tools provided to answer a question. Do not rely on prior knowledge.\
""",
verbose=True
)
agent = AgentRunner(agent_worker)
response = agent.query(
"Tell me about the evaluation dataset used "
"in MetaGPT and compare it against SWE-Bench"
)
print(str(response))
response = agent.query(
"Compare and contrast the LoRA papers (LongLoRA, LoftQ). "
"Analyze the approach in each paper first. "
)
For More check the below resources:
- Custom agent: https://docs.llamaindex.ai/en/stable/examples/agent/custom_agent/
- Community build agents: https://llamahub.ai/?tab=agent
- Advanced document parsing: cloud.llamaindex.ai
Kaynak
[1] Deeplearning.ai, (2024), Building Agentic Rag with Llamaindex:
[https://learn.deeplearning.ai/courses/building-agentic-rag-with-llamaindex]










0 Comments