
https://cbarkinozer.medium.com/git-ile-versiyon-kontrol%C3%BC-nas%C4%B1l-yap%C4%B1l%C4%B1r-846cf18a2c53
We will learn what the basic version control operations of Git are.

Creating code is a dynamic process that entails experimenting with numerous ways to achieve the desired result. Thus, having a system or tool that helps track multiple code variants and allows the developer to revert to past versions is incredibly useful. This is especially visible when an entire developer team collaborates on a piece of software, with each team member making modifications to the code base independently of the others.
The problem frequently arises when multiple developers make modifications to the same portion of a program without knowing each other. Typically, these adjustments are compatible with the rest of the developer’s work while conflicting with the other’s changes. Version control software is a technology that helps with these issues in large-scale software development. It operates by keeping track of all code modifications in a dedicated database. This tracking technique facilitates the program’s return to a functional state following the discovery of a mistake.
Furthermore, it helps to identify code conflicts and allows for a resolution that is compatible with all other pending changes. This article defines version control systems and discusses the three primary types (local, centralized, and decentralized). Concurrent Version System (CVS), Apache Subversion (SVN), and Git will also be discussed.
Version Control
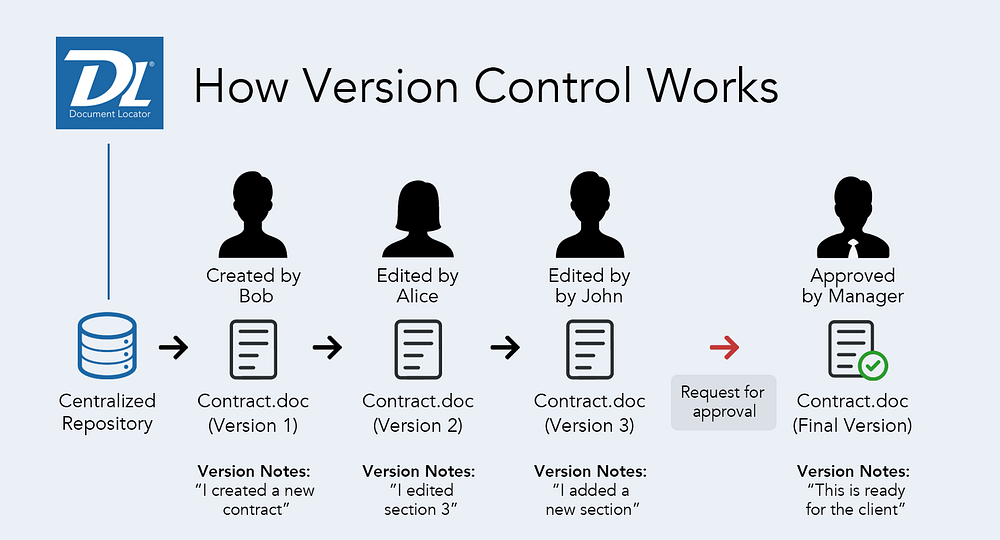
Version control is the process of tracking changes to papers, computer programs, huge websites, and other collections of data. Version control (VC) is a key component of software configuration management. Sometimes VC is known as revision control or source control.
In general, source control is used to track changes in source code. Changes are typically marked by a number or letter code known as the “revision number”, “revision level,” or simply “revision”. For example, the initial set of files is referred to as “revision 1”. When the initial change is made, the ensuing set is labelled “revision 2”, and so on. Each revision is assigned a timestamp and identifies the person who modified it. Revisions can be compared, restored, and, with certain file formats, merged. VC serves a broader range of functions, such as source code and digital assets.
Because the code base is the same, a specific (read/write/execute) permission must be granted to a group of developer team members. A lead developer is then in charge of maintaining permissions to ensure that the code base remains secure.
It is not straightforward to manually configure a VC environment. Numerous software technologies have been created to automate the VC process. There are three kinds of VC-developed systems.
- Local version control systems involve copying files to a time-stamped folder on your PC. With this method, it is easy to forget which folder you are in, and you may accidentally write to the wrong file or copy over data you do not intend to. This technology does not allow for collaboration at all. The biggest drawback is that if your local hard drive becomes corrupted or crashes, the entire project source code history will be lost.
- Centralized version control systems use a single server to store all versioned files, with several clients checking out files from it. For many years, this was the standard for VC. In these systems, every team member understands, to some extent, what everyone else on the project is doing. System administrators have significant influence over who can do what. A central VC server is easier to operate than individual client databases. As with local VS systems, if the central hard drive failed for any reason, everything from the project would be lost.
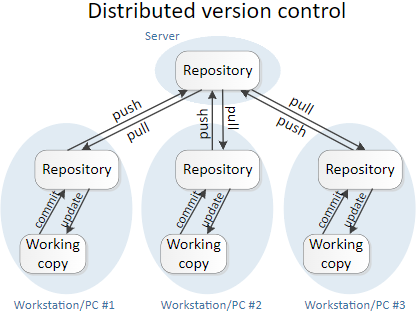
- Distributed version control solutions are built on several clone servers. In this situation, the team members replicate the entire source code data structure (repository), including all history. If a server fails and these systems are cooperating through it, any of the team member repositories can be copied back onto the server to recover it. Every clone creates a complete backup of all source code data structures. This is the most common way to construct VC systems today.
Git, CVS, SVN, and other open-source version control systems are widely used today.
- CVS (Concurrent Versions System) is an open-source, centralized version control system. CVS automates the storage, retrieval, logging, identification, and merging of changes. It is especially suitable for constantly updated content such as source code, programs, manuals, papers, and form letters. It employs a client-server architecture (a distributed application structure that divides tasks or workloads between resource or service providers known as servers and service requesters known as clients), in which the server stores the current version(s) of a project and its history, and the client can connect to the server to check out a complete copy of the project and check in project changes.
- SVN (Apache Subversion) is an open-source software revision control system published under the Apache license. Subversion is used by software engineers to keep track of both current and historical versions of files including source code, web pages, and documentation. Subversion was designed to work across networks, allowing development team members to utilize it from separate machines. It promotes cooperation by allowing several users to alter and control the same set of data from their locations. As a result, source code updates can be completed more quickly, as there is no single conduit through which all revisions must pass.
Git Version Control System
Git is the most widely used distributed version control system for recording changes to source code during software development.
Git does not need source control updates to be committed to the same central repository, which would have every team member working on the project accessing that central repository and downloading the most recent code to save changes. Instead, each team member can have a localized repository that has the complete history.
Git is created for the following purposes:
- A simplistic design allows for easy maintenance.
- Strong support for non-linear development, with numerous parallel independent lines of source code.
- A fully distributed system.
Fundamental Version Control Concepts
Git Repository
A repository is a centralized directory that stores numerous versions of files. It is a basic hidden folder called “.git” in the root directory of your project. Repositories can be both local and remote.
Git Local Repository
A local repository is a “.git” directory located within your project’s root directory on your PC. Only a team member may commit changes to this repository. It could be any specific directory on your PC.
Git Remote Repository
A remote repository is a “.git” folder that is often hosted on a distant server on the internet or within your local network. A remote repository has no working directory and thus no actual working files; instead, it just contains the “.git” repository folder. Team members use remote repositories to share and exchange data. They act as a central hub where everyone may publish their updates and receive changes from their teammates.
Git Blob
Blobs (binary big objects) are variants of files. A blob stores file data but contains no metadata about the file. It’s a basic binary file in the Git repository.
Git Tree
Trees are objects that symbolize a directory. They store blobs as well as other subdirectories. A tree is a binary file containing references to blobs and trees.
Git Commit
Commits represent one state of the repository. A commit object is a node in the linked list. Every commit object contains a pointer to its parent commit object. You can inspect the commit’s history by traversing back using the parent pointer. If a commit contains more than one parent commit, it was made by merging two branches.
Git Branch
A branch is a separate path of development derived from the same source code. Different branches can be merged into a single branch as long as they share the same repository. Git, by default, has a master branch. Typically, a branch is established to work on a new program feature. Once the feature is completed, it is merged back into the main branch and discarded.
Git Tag
Tags are meaningful names associated with distinct versions of the repository. Tags are similar to branches, however they are immutable. Even if you create a new commit, the tag associated with that commit will not be updated. Typically, tags are developed for product launches.
Git Clone
Cloning is an operation that creates a repository instance. Clone checks out the working copy and mirrors the entire repository. This local repository enables team members to perform a wide range of actions. The only time networking is engaged is when the repository instances are synced.
Git Pull
Pulling is an operation that copies changes from a remote repository instance to a local one. The pull procedure is used to synchronize two repository instances. This operation is used frequently. • Push is an operation that copies changes from a local repository instance to a remote one. This is used to save changes permanently in the Git repository. This operation is used frequently.
Git HEAD
HEAD is a reference to the most recent commit in the branch. When you make a commit, HEAD is updated with the most recent commit. This code is unique.
Git Merging
Merge is an operation that moves one location to another. Whether a branch is formed for testing, bug repairs, or other purposes, merge can commit modifications to other branches. Merging combines the contents of a source branch with a target branch. During this operation, only the target branch is modified. The source branch’s history remains the same.
Git Rebasing
Rebase is another method for integrating changes from one branch to another. Rebase consolidates all changes into a single “patch” and then integrates it with the target branch. Unlike merging, rebasing flattens the past by moving completed work from one branch to another. During the process, undesirable history is removed.
Git Diff
Diff is a procedure that compares different versions of your files. It displays the modifications made to any files of different versions. The most typical use case for diff is to see the changes you made since your last commit.
— — quillbot burada kaldı — -
Git Revision
Revision is a tiny integer. It indicates the version of the source code created by the commit command. It is only a local convenience identifier for a revision. It can be handy because it is easier to type than the 40-digit hexadecimal string that uniquely identifies each revision.
Git URL
The URL represents the Git repository’s weblink location. The Git URL is stored in a configuration file. It must be unique to each Git repository.
Git Commands
To download Git:
# Linux
sudo apt-get install git-core
# Windows
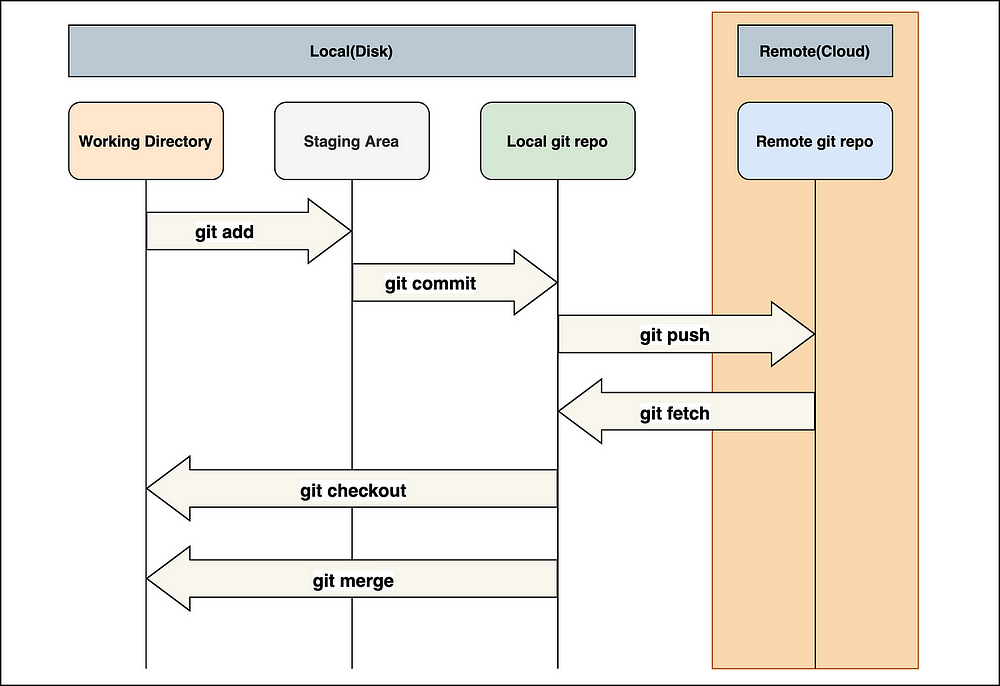
Git-2.24.0.2-64-bit.exeThe default behaviour in Git is that the working directory modifies the files. Add the files to the staging area. Execute a commit operation to move the files from the staging area. After the push procedure, the changes are permanently stored in the Git repository.
Git’s default team behaviour is to clone the appropriate remote Git repository as a local working copy on your machine. Modify the local working copy by adding or modifying any required files. If necessary, the local working copy can be updated by incorporating other developers’ contributions. Prior to committing, review the modifications. Commit your changes. If everything is fine, you can push the modifications to the remote repository. If something goes wrong after you commit, you must rectify the previous commit before pushing the changes back to the remote repository.
Creating a new repository
Open Git Bash (terminal) and execute the following command.
git initCheckout a repository
To create a functioning copy of a local repository, run the following command:
git clone /path/to/repositoryIf you’re utilizing a remote server, your command would be:
git clone username@host:/path/to/repositoryAdd
Changes can be made by adding them to the index with the following code:
git add <filename>
git add *Commit
To commit these changes to Git, use the following code:
git commit -m "Commit message"The file has now been committed to the HEAD, but it has yet to appear in your remote repository.
Push
The modifications have been saved in the HEAD of your local working copy. To push the changes to your remote repository, execute:
git push origin masterChange master to the branch you want to push your modifications to. If you have not cloned an existing repository and want to link it to a remote server, you must do so with:
git remote add origin <server>You can now push your modifications to the remote server of your choice. 5. Create a new branch name and switch to it with:
git checkout -b branch_nameSwitching to a Branch
git checkout masterDeleting a Branch
git branch -d branch_nameA branch is not exposed to others unless it is pushed to your remote repository.
git push origin <branch>Update and merge
Update your local repository to the most recent commit, execute:
git pullTo fetch and combine remote changes in your working directory, merge another branch into your active branch (for example, master), using:
git merge <branch>In both circumstances, Git attempts to auto-merge modifications. Unfortunately, this is not always achievable, which leads to conflict. You are responsible for manually merging the conflicts by modifying the files displayed by Git. After making the changes, mark them as merged with:
You can see modifications before merging them with the following command:
git diff <source_branch> <target_branch>Tagging
Use for software release. To generate a new tag named 1.2.0, execute:
git tag 1.2.0 1b1e3d655ffThe 1b1e3d655ff represents the first ten characters of the commit id you wish to reference with your tag.
Log
Use to research repository history.
git logYou can customize the log by adding a variety of parameters. To only see commits from a specific author, use:
git log --author=cbarkinozerTo see an extremely compressed log with each commit on one line, use:
git log --pretty=onelineTo view an ASCII art tree of all the branches, adorned with the names of tags and branches, use:
git log --graph --oneline --decorate –allTo determine which files have changed, use the following:
git log --name-statusPopular Git hosting services

There are various Git repository hosting services available, however not all of them include a free option in their packages. We’ll look at three of the most popular today.
- “GitHub is the largest community website for software development.” It includes some of the most effective tools for problem tracking, code review, continuous integration, and overall code management. And its foundation is still built on Git, everyone’s favourite open source distributed version control system.” GitHub offers free public and premium private repositories. Microsoft acquired it in 2018.
- GitLab is a completely open-source hosting service. “You can host your code right on GitLab’s site, much like you would on GitHub, but you can also choose to self-host a GitLab instance on your server and have full control over who has access and how things are managed”. GitLab provides essentially identical functionalities to GitHub.
- Bitbucket is an accurate representation of GitHub and GitLab. According to Wikipedia, it “shares most of the features available on GitHub and GitLab, plus a few novel features of its own, such as native support for mercurial repositories”.
Of the three hosting providers, GitHub currently has the most users. The platform extends Git’s base version control features with various tools for issue tracking, code review, continuous integration, and general code management. Project hosting is available in both free and paid tiers. GitLab has a comparable feature set. What distinguishes GitLab is its support for self-hosted instances of the service.
Thus, code does not need to be installed on external infrastructure. Atlassian (n.d.) offers Bitbucket, a Git hosting service, in addition to its popular Jira and Confluence issue tracking and documentation tools. The feature set on offer is comparable to that of the preceding services, but it distinguishes itself by supporting the Mercurial version control system as an alternative to Git.
When starting, I recommend trying Git Desktop. The GUI will help you comprehend the processes and reduce the likelihood of errors in the beginning.










0 Comments