
Abstract
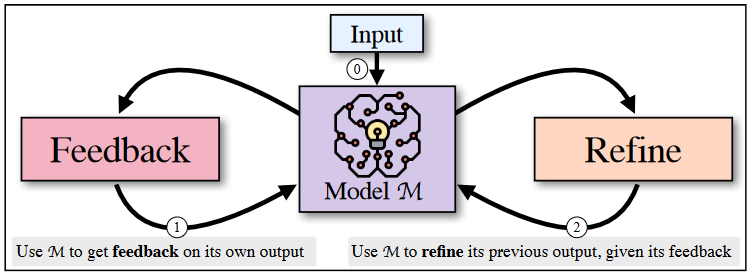
Just like humans don't, large language models don't always produce the best output on the first try. Motivated by the way people improve their written texts, we introduce SELF-REFINE, an approach to improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to first create an initial output using LLM; The same LLM then provides feedback for its own output and uses it to iteratively improve itself. SELF-REFINE does not require any supervised training data, additional training, or reinforcement learning, and instead uses a single LLM as a generator, refiner, and feedback provider. We also evaluate SELF-REFINE on 7 different tasks, from conversational response generation to mathematical reasoning, using state-of-the-art (GPT-3.5 and GPT-4) LLMs. Across all tasks evaluated, outputs generated with SELF-REFINE are preferred by humans and automated measurements over outputs generated with the same LLM using traditional one-shot generation, with an absolute average improvement in task performance of ∼20%. Our work shows that even state-of-the-art LLMs such as GPT-4 can be further improved at test time using our simple, standalone approach.
Images



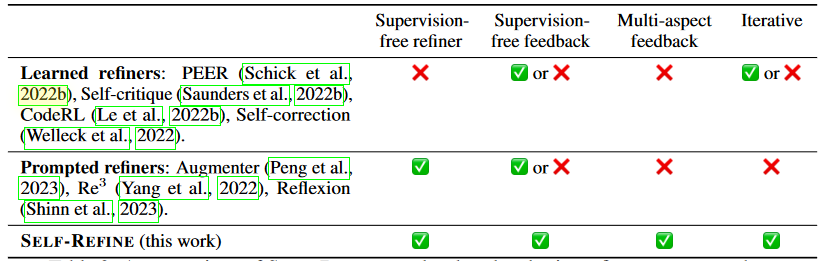
Summary
- We describe a method called SELF-REFINE for improving the output of large language models (LLMs) through iterative feedback and refinement. The approach involves creating an initial output using the same LLM to provide feedback on the output and iteratively improving it.
- This process requires no additional training or supervision and can be applied to a variety of tasks.
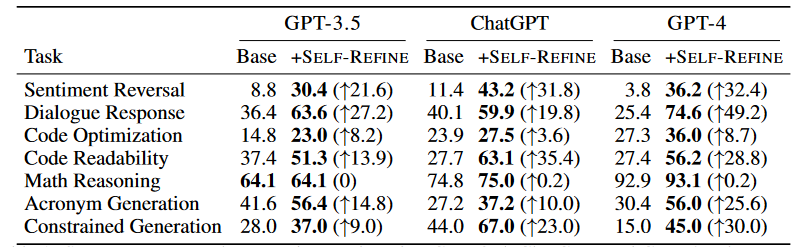
- The authors evaluate SELF-REFINE on 7 different tasks and show that it improves task performance by an average of 20% compared to traditional single-step production. The results show that even state-of-the-art LLMs can be further improved using this simple approach.
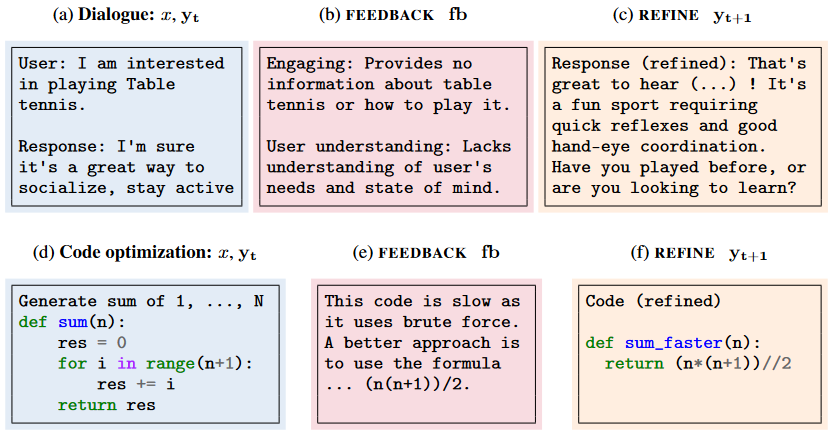
- The text discusses the benefits of using the SELF-REFINE approach when creating sentences containing the given concepts. SELF-REFINE leads to high gains in preference-based tasks such as Conversational Response Generation, Emotion Reversal, and Acronym Generation.
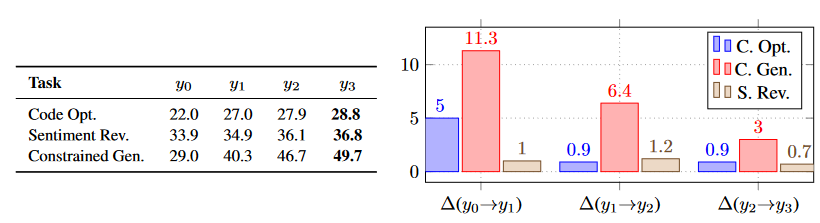
- The quality of feedback plays a crucial role in REFINE YOURSELF, with specific, actionable feedback delivering superior results compared to general feedback. Multiple iterations of feedback and improvement improve the quality of the output, with improvement decreasing with more iterations. SELF-REFINE performs better at generating multiple initial outputs without requiring optimization. When using the SELF-REFINE method, weaker models may struggle with the healing process and fail to follow instructions. Qualitative analysis demonstrates the effectiveness of SELF-REFINE in producing improved outcomes.
- The researchers analyzed a total of 70 examples, focusing on Code Optimization and Mathematical Reasoning tasks.
- They found that the feedback provided was mostly actionable and helped identify problematic aspects of the original generation.
- When SELF-REFINE failed to improve output, this was usually due to faulty feedback rather than faulty improvements. Accurate and helpful feedback played a vital role in successful cases, leading to precise corrections in the refining process. The refiner was capable of correcting problems even when the feedback was partially inaccurate and demonstrated resilience to suboptimal feedback. The study demonstrated the potential of SELF-REFINE in real-world tasks such as website creation.
- SELF-REFINE has been demonstrated on a variety of tasks, including sentiment inversion, dialogue response generation, code optimization, mathematical reasoning, abbreviation generation, and constrained generation.
- The results show that SELF-REFINE is effective in improving performance on these tasks, and statistically significant gains are observed for different datasets. Experiments involve human annotators to evaluate human performance and compare it to SELF-REFINE output.
Conclusion
We present SELF-REFINE, a new approach that allows large language models to iteratively provide self-feedback and improve their own output. SELF-REFINE runs within a single LLM and does not require additional training data or reinforcement learning. We demonstrate the simplicity and ease of use of SELF-REFINE in a wide variety of tasks. By demonstrating the potential of SELF-REFINE on a variety of tasks, our research contributes to the ongoing research and development of large language models to reduce the cost of human creative processes in real-world environments. We hope that our iterative approach will facilitate further research in this area. For this purpose, we make all our codes, data and prompts available anonymously at “https://selfrefine.info/”.
Resources
[1] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, Peter Clark, (25 May 2023), Self-Refine: Iterative Refinement with Self-Feedback. https://doi.org/10.48550/arXiv.2303.17651










0 Comments