
https://cbarkinozer.medium.com/linkbert-dil-modellerini-belge-linkleriyle-pretrain-etmek-7570723d4395
Review of the article “LinkBERT: Pretraining Language Models with Document Links”.
Abstract
Language model (LM) pretraining can aid downstream tasks by learning various information from text corpora. However, existing methods such as BERT model a single document and do not capture dependencies or information spanning documents. In this work, we propose LinkBERT, an LM pre-training method that takes advantage of links between documents (e.g. url links). Given a corpus of text, we view it as a graph of documents and create LM entries by placing linked documents in the same context. We then pre-train the LM with two common self-supervised goals: masked language modelling (MLM) and our new proposal, document relationship prediction. We show that LinkBERT outperforms BERT on various subtasks in two domains: the general domain (pre-trained on Wikipedia with hyperlink links) and the biomedical domain (pre-trained on PubMed with citation links). LinkBERT is particularly effective for multi-shot reasoning and few-shots QA (+5% absolute improvement in HotpotQA and TriviaQA), and our biomedical LinkBERT identifies new technologies in various BioNLP tasks (+7% in BioASQ and USMLE). We publish code and data as well as our pre-trained models LinkBERT and BioLinkBERT
Summary
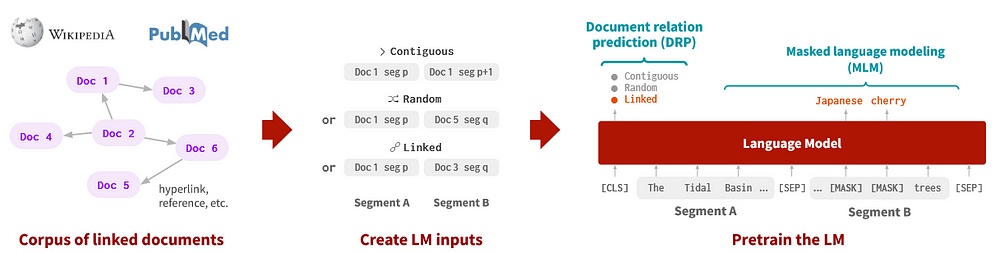
- LinkBert uses self-supervised learning to learn multi-hop knowledge and document relationships.
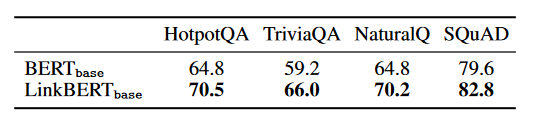
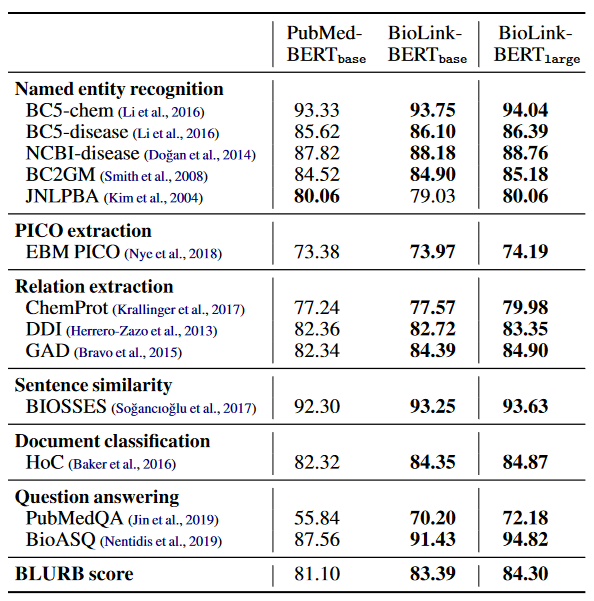
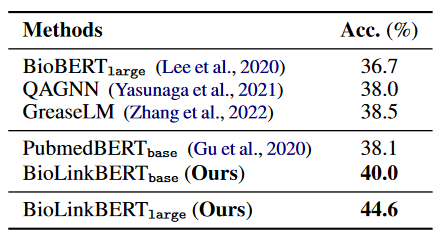
- LinkBERT outperforms BERT on a variety of subtasks in general and biomedical domains, and is particularly effective at multi-hop reasoning and answering a small number of questions.
- Retrieval-enriched language models show promise in improving model inference. Some important studies on this topic include: Guu et al. (2020) pre-trains an LM with a text receiver to respond to masked tokens in the anchor text. Asai et al (2020) focus on incorporating document links such as hyperlinks to provide salient information in LM pretraining. Caciularu et al (2021) and Levine et al (2021) use multiple relevant documents in the same LM context for pretraining LMs. Chang et al (2020), Asai et al (2020), and Seonwoo et al (2021) use hyperlinks to train recipients in open-domain question answering. Ma et al (2021) examine hyperlink-aware pretraining tasks for retrieval. Calixto et al (2021) use Wikipedia hyperlinks to learn multilingual LMs. Zhang et al (2019), He et al (2020), Wang et al (2021b), Sun et al (2020), Yasunaga et al (2021), and Zhang et al (2022) enrich LMs with knowledge graphs or neural graph cries.
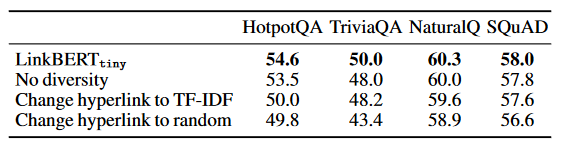
- Hyperlinks are advantageous in providing background information and related documents that may not be obvious through lexical similarity alone.
- Use the TF-IDF cosine similarity metric to obtain the best documents and generate edges.
- AdamW optimizer used for training — (β1, β2) = (0.9, 0.98).
- LinkBERT is pre-trained in three dimensions: -tiny, -base and -large.
- -tiny model In the first 5,000 steps the learning rate is warmed up and reduced linearly. It was trained with 10,000 steps with a 5e-3 peak learning rate, 0.01 weight decay and a work size of 512 tokens and 2,048 sequences. Training took 1 day on 2 GeForce RTX 2080 Ti GPUs with fp16.
- For -base, LinkBERT was started with the BERTbase checkpoint published by Devlin et al. (2019) and pre-training continued. Use the highest learning rate of 3e-4 and finetune for 40,000 steps. Training took 4 days on four A100 GPUs with fp16.
- For -large, the same procedure as for -base was followed, but the highest learning rate of 2e-4 was used. Training took 7 days on 8 A100 GPUs with fp16.
- LinkBERT significantly outperforms BERT on all datasets in GLUE.
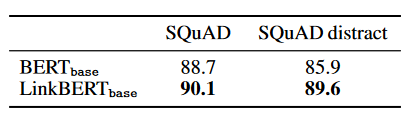
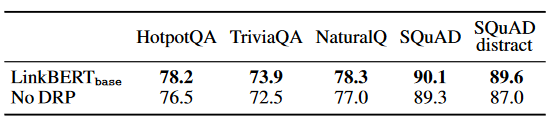
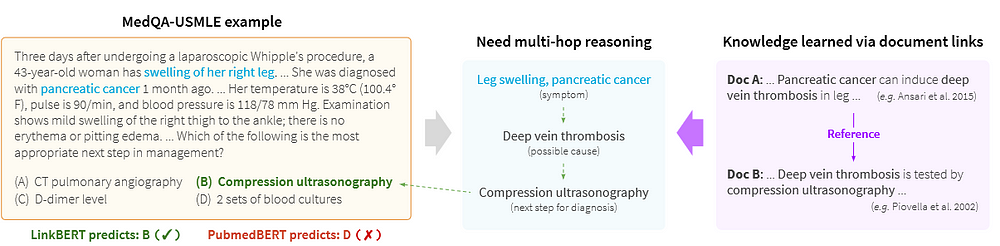
- LinkBERT is particularly effective at learning information useful for QA tasks while preserving sentence-level language understanding performance. It shows a better understanding of document relationships with LinkBERT compared to BERT.
Images


The second table on the right: Performance in the GLUE benchmark. LinkBERT achieves comparable or moderately improved performance.


Conclusion
We presented LinkBERT, a new language model (LM) pre-training method that includes link information such as hyperlinks between documents. In both the general domain (pre-trained on Wikipedia with hyperlink links) and the biomedical domain (pre-trained on PubMed with citation links), LinkBERT outperforms previous BERT models on a wide range of subtasks. The gains are huge in terms of multi-hop reasoning, multi-document understanding, and answering a small number of questions; This shows that LinkBERT effectively internalizes salient information through document links. Our results show that LinkBERT can be a powerful, pre-trained LM to be applied to a variety of knowledge-intensive tasks.
Resources
[1] Michihiro Yasunaga Jure Leskovec∗ Percy Liang∗
Stanford University, 29 Mar 2022, LinkBERT: Pretraining Language Models with Document Links:










0 Comments