
https://cbarkinozer.medium.com/deepseek-kod-llmlerinde-g%C3%BC%C3%A7l%C3%BC-verimlili%C4%9Fi-ortaya-%C3%A7%C4%B1karma-f2cf11f9ed11
DeepSeek Code LLMs have appeared on the leaderboard, here are the details.

DeepSeek (深度求索) is a Chinese company founded in 2023, dedicated to making AGI a reality.
No article on DeepSeek's models has been published yet. DeepSeek's code models are open-source models (model weights are published). DeepSeek has started to take the top spot in the Code LLM rankings.
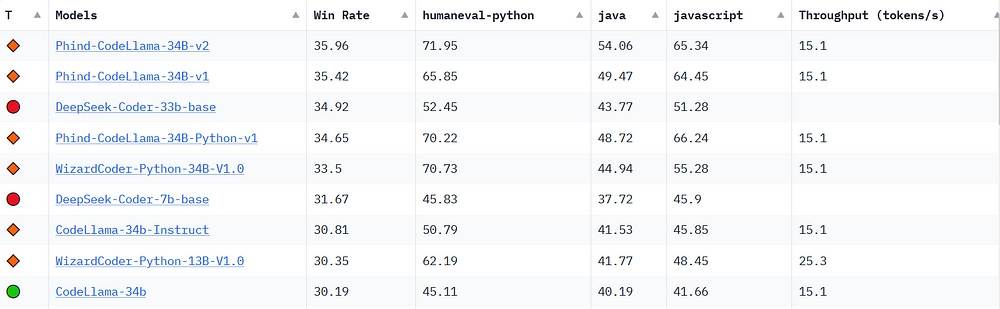
It is a matter of curiosity how the model, which has only 7 billion parameters, has such performance.
- Massive Training Data: Trained from scratch on 2 trillion tokens, including 87% code and 13% Chinese and English data.
- Highly Flexible and Scalable: Available in 1D, 5.7B, 6.7B and 33D model sizes, users can choose the setup that best suits their needs.
- Superior Model Performance: HumanEval demonstrates state-of-the-art performance among public code models on MultiPL-E, MBPP, DS-1000 and APPS benchmarks.
- Advanced Code Completion Capabilities: With a 16K context size, the fill-in-the-blank task supports project-level code completion and backfilling tasks.
Languages supported by DeepSeek
['julia', 'matlab', 'tcsh', 'mathematica', 'cpp', 'fortran', 'yacc', 'powershell', 'go', 'clojure', 'sas', 'zig', 'verilog', 'isabelle', 'literate-agda', 'c-sharp', 'erlang', 'sparql', 'java-server-pages', 'java', 'stan', 'stata', 'visual-basic', 'augeas', 'applescript', 'emacs-lisp', 'json', 'rmarkdown', 'smalltalk', 'prolog', 'scala', 'ada', 'lean', 'pascal', 'literate-haskell', 'assembly', 'c', 'sql', 'php', 'javascript', 'bluespec', 'dockerfile', 'tex', 'protocol-buffer', 'awk', 'html', 'f-sharp', 'ruby', 'vhdl', 'elm', 'maple', 'idris', 'python', 'thrift', 'common-lisp', 'tcl', 'restructuredtext', 'batchfile', 'rust', 'r', 'typescript', 'markdown', 'antlr', 'agda', 'cmake', 'css', 'scheme', 'literate-coffeescript', 'groovy', 'coffeescript', 'cuda', 'glsl', 'standard-ml', 'yaml', 'lua', 'jupyter-notebook', 'ocaml', 'xslt', 'alloy', 'elixir', 'systemverilog', 'shell', 'perl', 'solidity', 'haskell', 'racket', 'kotlin', 'makefile', 'dart']
Performance
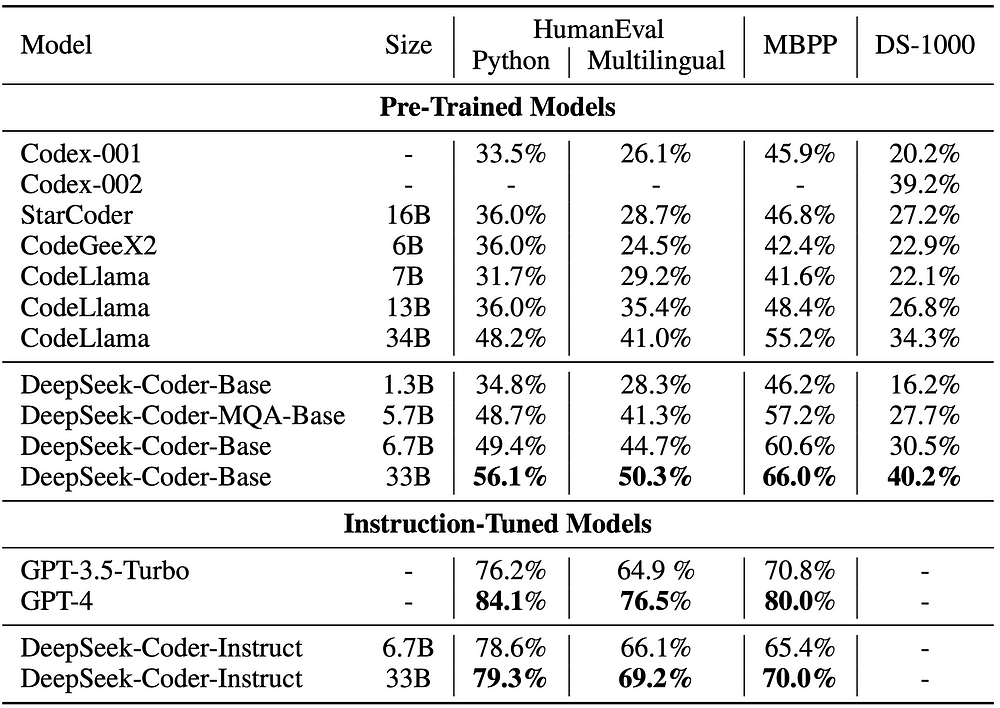
DeepSeek-Coder-Base-33B significantly outperforms existing open-source LLMs. Compared to CodeLlama-34B, HumanEval Python is ahead by 7.9%, 9.3%, 10.8%, and 5.9% on HumanEval Multilingual, MBPP, and DS-1000, respectively. Surprisingly, our DeepSeek-Coder-Base-7B achieves the performance of CodeLlama-34B. After Instruction finetuning, the DeepSeek-Coder-Instruct-33B model outperformed GPT35-turbo on HumanEval and achieved comparable results to GPT35-turbo on MBPP.
Data Creation and Model Training
Creating Data
Data for DeepSeek was generated with the following steps.
- Step 1: Code data was collected from GitHub and the same filtering rules as StarCoder Data were applied to filter the data.
- Step 2: Dependencies of files in the same repo are parsed to rearrange file locations according to their dependencies.
- Step 3: Dependent files were merged to create a single instance and “minhash” was used at the repo level for deduplication.
- Step 4: Low-quality codes such as syntax errors or codes with poor readability are further filtered out.

Model Training
- Step 1: Initially, the model is pre-trained with a dataset consisting of 87% code, 10% code-related language (Github Markdown and StackExchange), and 3% non-code-related Chinese language. In this step, models are pre-trained using 1.8 trillion tokens and 4K context size.
- Step 2: Basic models (DeepSeek-Coder-Base) were obtained by further pretraining using an expanded 16K context size on an additional 200B token.
- Step 3: Instruction finetuning models were created by performing instruction finetuning on the 2D token instruction data (DeepSeek-Coder-Instruct).

DeepSeek unique prompt style to achieve maximum performance:
You are an AI programming assistant, utilizing the DeepSeek Coder model, developed by DeepSeek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
['content']
### Response:
['content']
<|EOT|>
### Instruction:
['content']
### Response:General Prompt Style
Let's remember the general routing style for open-source models.
Natural language text is not ideal for inference because the model will naturally generate unwanted answers until it generates a <EOS> token, and some post-processing or additional processing is usually required to prevent this.
A better approach is to use a structured format like ChatML, which wraps each answer with a set of special tokens that indicate the role of the answer.
We have the following custom tokens in this format:
- <|system|>: Indicates which part of the dialogue contains the system message that will condition the assistant's character.
- <|user|>: Indicates that the message comes from a human user.
- <|assistant|>: Indicates that the messages come from the artificial intelligence assistant.
- <|end|>: Indicates the end of a turn or system message.
To see what it looks like, you can write a method that wraps our running instance with these tokens:
system_token = "<|system|>"
user_token = "<|user|>"
assistant_token = "<|assistant|>"
end_token = "<|end|>"
def prepare_dialogue(example):
system_msg = "Below is a dialogue between a human and an AI assistant called StarChat."
prompt = system_token + "\n" + system_msg + end_token + "\n"
for message in example["messages"]:
if message["role"] == "user":
prompt += user_token + "\n" + message["content"] + end_token + "\n"
else:
prompt += assistant_token + "\n" + message["content"] + end_token + "\n"
return prompt
print(prepare_dialogue(sample))
'''
<|system|>
Below is a dialogue between a human and AI assistant called StarChat.
<|end|>
<|user|>
Is it possible to imagine a society without law?<|end|>
<|assistant|>
It is difficult to imagine ...<|end|>
<|user|>
It seems like you ...<|end|>
<|assistant|>
You are correct ...<|end|>
<|user|>
Yeah, but laws are complicated ...<|end|>
'''The next step is to include these custom tokens in the tokenizer's dictionary, so let's download the StarCoder tokenizer and add it:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bigcode/starcoderbase")
tokenizer.add_special_tokens({"additional_special_tokens": ["<|system|>", "<|assistant|>", "<|user|>", "<|end|>"]})
# Check the tokens have been added
print(tokenizer.special_tokens_map)
'''
{
"bos_token": "<|endoftext|>",
"eos_token": "<|endoftext|>",
"unk_token": "<|endoftext|>",
"additional_special_tokens": ["<|system|>", "<|assistant|>", "<|user|>", "<|end|>"],
}
'''References
[1] BigCode, (December 2023), Big Code Models Leaderboard:
[https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard]
[2] deepseek-ai, (December 2023), DeepSeek-Coder:
[https://github.com/deepseek-ai/DeepSeek-Coder]
[3] DeepSeek,(2023), DeepSeek Coder:Let the Code Write Itself
[https://deepseekcoder.github.io/]
[4]lewtun et al. ,(May 9, 2023), Creating a Coding Assistant with StarCoder:










0 Comments