
"Federated Fine-tuning of LLMs with Private Data” course on Deeplearning.ai.

The federated learning model is distributed, and working with LLMs requires a lot of bandwidth. To handle this problem, we will use the PEFT approach. We will combine federated learning with differential privacy so our data is safe and not retrieved by users.
Smarter LLMs with Private Data
Let’s learn the current limits of data being used to train existing LLMs and the potential for federated LLM fine-tuning to help change this.
Data in the world are:
- Private: In phones or emails.
- Regulated: Like financial or legal data.
- Sensitive: Doorbell camera images or medical images.
- Isolated: Manufacturing or automotive photos.
LLMs are usually trained with publicly available data on the internet, such as websites, social media, YouTube, blogs, articles, etc.
Large Language Models are trained with such data, so they answer general questions very well because they have already seen this question and answered it thousands of times in their datasets. Still, when you ask them specialized questions, you get bad answers because they tend to give general answers. For example, when you get a question like “I have blurry vision and diabetes, what should I do?”, they may answer “Eating carrots is good for your eyes”.
Due to these problems, domain-specific large language models have been trained, such as ChefGPT, BloombergGPT, Med-Gemini, GlassAI2.0, LanguageTeacher, BioGPT, and FlowerLLM, with data from specialized fields such as cooking, education, health, finance, and education.
This is done by fine-tuning, but they are leaking training data, known as LLMs, so when fine-tuning, we need to be careful about using private data.
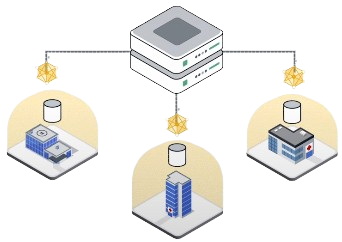
Federated fine-tuning is an alternative to centralized fine-tuning that overcomes key challenges using private data, such as Privacy, regulations, data volume, host limitations, bandwidth, etc.
Centralized LLM Fine-tuning
How much better can an LLM get when it can use private data? Let’s fine-tune an LLM to see how much better it can get.

MedAlpaca is a great resource for a variety of medical domain knowledge, it has 50k training examples including question-answer pairs.
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
import torch
from datasets import load_dataset
from trl import SFTTrainer
from transformers import TrainingArguments
from utils.utils import *
from utils.LLM import LLM_pretrained, LLM_cen_partial
from utils.LLM import get_fireworks_api_key,load_env
# Load config
cfg = get_config("centralized")
# Inspect the config
print_config(cfg)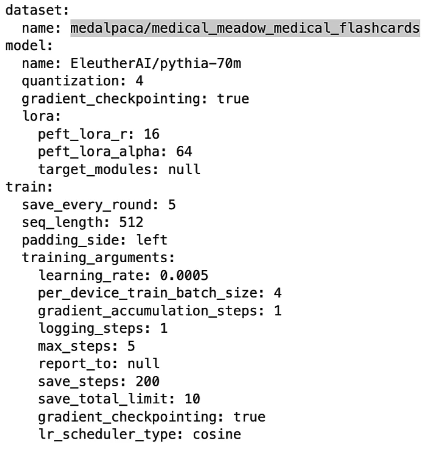
# Load the dataset
trainset_full = load_dataset(cfg.dataset.name, split='train')
train_test = trainset_full.train_test_split(test_size=0.9, seed=1234)
train_dataset = train_test["train"]
train_dataset = format_dataset(train_dataset)
print(train_dataset)
# Print an example from the dataset
example_index = 9
data_point = train_dataset[example_index]
# Asking the LLM
llm_pretrained = LLM_pretrained()
prompt = "How to predict the weather"
llm_pretrained.eval(prompt, verbose = False)
llm_pretrained.print_response(verbose = False)
# Evaluate pretrained model on Medical Q&A
llm_pretrained.eval(data_point['instruction'], verbose=True)
llm_pretrained.print_response()
ex_response = format_string(data_point['response'])
print(f"Expected output:\n\t{ex_response}")
# Set the model
model = get_model(cfg.model)
trainable, all_parameters = model.get_nb_trainable_parameters()
print(f"Trainable parameters: {trainable}")
print(f"All parameters: {all_parameters}")
print(f"Trainable (%): {100*trainable / all_parameters:.3f}")
# Define the tokenizer
(
tokenizer,
data_collator,
format_prompts_fn
) = get_tokenizer_and_data_collator_and_propt_formatting(
cfg.model.name, cfg.model.use_fast_tokenizer, cfg.train.padding_side
)
# Define the finetune_centralised function
save_centralized = "./my_centralized_model"
def finetune_centralised():
# The notebooks you are running in this course does not
# come with a GPU. However, we don't harcode "cpu" as the
# device to use in case you wish to download this notebook
# and run it on your own GPU.
use_cuda = torch.cuda.is_available()
training_arguments = TrainingArguments(
**cfg.train.training_arguments,
use_cpu=not(use_cuda),
output_dir=save_centralized,
)
# Construct trainer
trainer = SFTTrainer(
tokenizer=tokenizer,
data_collator=data_collator,
formatting_func=format_prompts_fn,
max_seq_length=cfg.train.seq_length,
model=model,
args=training_arguments,
train_dataset=train_dataset,
)
# Do local training
trainer.train()
# Save the checkpoint
model.save_pretrained(save_centralized)
finetune_centralised()
llm_cen = LLM_cen_partial()
example_index = 9
data_point = train_dataset[example_index]
llm_cen.eval(data_point['instruction'], verbose=True)
llm_cen.print_response()
ex_response = format_string(data_point['response'])
print(f"Expected output:\n\t{ex_response}")
# Visualize results of prompting with pretrained LLM and finetuned LLM
visualize_results(results=['7b/pretrained', '7b/cen_10'])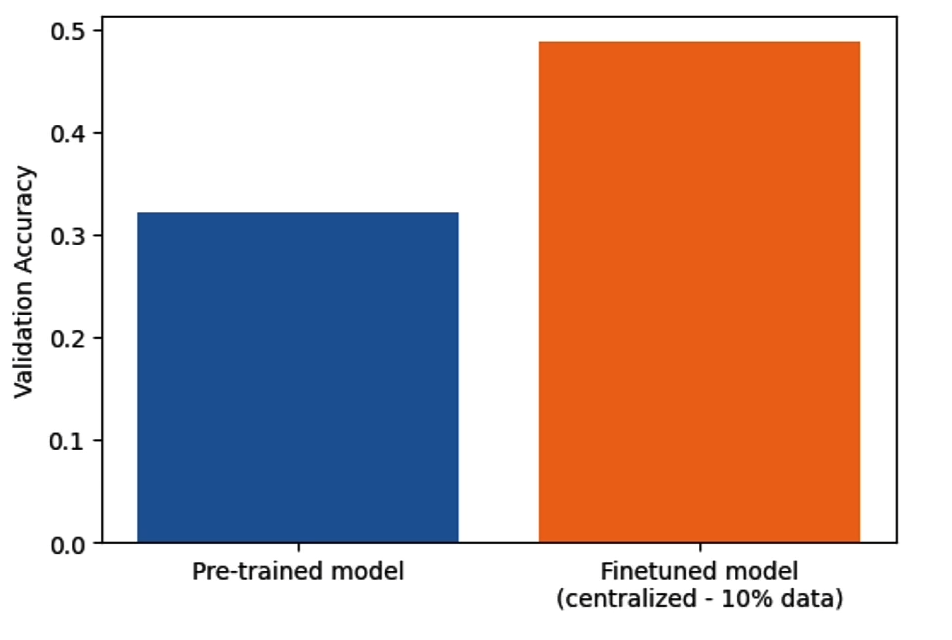
# Generate the datastructure for systematic evaluation
# Lauch evalution code
from utils.utils import inference, evaluate
# Step 1: generate answers
# To run inference on the pre-trained model:
inference(base_model_name_path=cfg.model.name, run_name="pretrained")
# To run inference on the centralised finetuned model:
inference(
base_model_name_path=cfg.model.name,
peft_path=path/to/your/checkpoint/directory,
run_name="centralised_finetuned",
)
# Step 2: evaluation --- accuracy value will be printed
evaluate(run_name="pretrained")
evaluate(run_name="centralised_finetuned")We saw fine-tuning improved the accuracy of the answer.
Federated Fine-tuning for LLMs
To fully comprehend the recipe for federated LLM fine-tuning we need to do federated learning, parameter-efficient fine-tuning and differential privacy. As a variation, you can also look for vertical federated learning, prompt tuning and server-side differential privacy. Additionally, you can look for hierarchical federated learning, activation compression and homomorphic encryption.
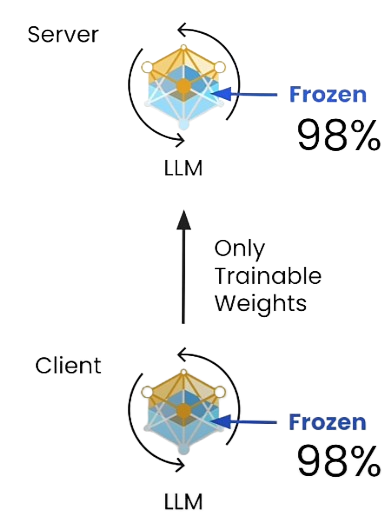
Let’s say we have a single server, a single global model and 5 clients. We choose 2 clients to manage communication overhead. Each client training will take place in the model weights of this LLM are updated again solely based on the data that the client has. In the next step, the individual data model weights from each client are sent to the server where an aggregation phase needs to take place. The updates coming form the clients are aggregated. For example, we can use federated average which is a scheme where all of these model updates are directly averaged together. Then this update is applied to the existing model.
Each averaging step is called a round and multiple of these federated learning rounds and necessary to be completed until the fine-tuning is finished. Peft fine-tuning approach is freezing %98 of the model's weights and only training a fraction of the LLM. This decreases bandwidth.
Differential privacy is adding noise to training data to decrease its retractability in a leaking situation.
How can learning happen if we are adding noise with differential privacy?

import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
import flwr as fl
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import IidPartitioner
from datasets import load_dataset
from flwr.client.mod import fixedclipping_mod
from flwr.server.strategy import (
DifferentialPrivacyClientSideFixedClipping
)
from utils.utils import *
from utils.LLM import LLM_fl
from utils.LLM import get_fireworks_api_key,load_env
cfg = get_config("federated")
print_config(cfg)
# Dataset partition
partitioner = IidPartitioner(num_partitions=cfg.flower.num_clients)
fds = FederatedDataset(
dataset=cfg.dataset.name,
partitioners={"train": partitioner}
)
partition_zero = fds.load_partition(0)
format_dataset(partition_zero)
# visualization partitions
visualize_partitions(fds)
# loading the tokenizer and other components
(
tokenizer,
data_collator,
formatting_prompts_func,
) = get_tokenizer_and_data_collator_and_propt_formatting(
cfg.model.name,
cfg.model.use_fast_tokenizer,
cfg.train.padding_side,
)
save_path = "./my_fl_model"
client = fl.client.ClientApp(
client_fn=gen_client_fn(
fds,
tokenizer,
formatting_prompts_func,
data_collator,
cfg.model,
cfg.train,
save_path,
),
mods=[fixedclipping_mod]
)
# server function and adding differential privacy
def server_fn(context: Context):
# Define the Strategy
strategy = fl.server.strategy.FedAvg(
min_available_clients=cfg.flower.num_clients, # total clients
fraction_fit=cfg.flower.fraction_fit, # ratio of clients to sample
fraction_evaluate=0.0, # No federated evaluation
# A (optional) function used to configure a "fit()" round
on_fit_config_fn=get_on_fit_config(),
# A (optional) function to aggregate metrics sent by clients
fit_metrics_aggregation_fn=fit_weighted_average,
# A (optional) function to execute on the server after each round.
# In this example the function only saves the global model.
evaluate_fn=get_evaluate_fn(
cfg.model,
cfg.train.save_every_round,
cfg.flower.num_rounds,
save_path
),
)
# Add Differential Privacy
sampled_clients = cfg.flower.num_clients*strategy.fraction_fit
strategy = DifferentialPrivacyClientSideFixedClipping(
strategy,
noise_multiplier=cfg.flower.dp.noise_mult,
clipping_norm=cfg.flower.dp.clip_norm,
num_sampled_clients=sampled_clients
)
# Number of rounds to run the simulation
num_rounds = cfg.flower.num_rounds
config = fl.server.ServerConfig(num_rounds=num_rounds)
return fl.server.ServerAppComponents(strategy=strategy, config=config)
server = fl.server.ServerApp(server_fn=server_fn)
# Running the simulation
client_resources = dict(cfg.flower.client_resources)
fl.simulation.run_simulation(
server_app=server,
client_app=client,
num_supernodes=cfg.flower.num_clients,
backend_config={"client_resources": client_resources,
"init_args": backend_setup}
)
# Runing the finetuned model
# Load the checkpoint
llm_eval = LLM_fl()
# Load dataset
train_dataset = load_dataset(cfg.dataset.name, split='train')
train_dataset = format_dataset(train_dataset)
# Select training example
example_index = 6
data_point = train_dataset[example_index]
# Print the prompt
llm_eval.eval(data_point['instruction'], verbose=True)
# Print the fine-tuned LLM response
llm_eval.print_response()
# Print the expected output from the medAlpaca dataset
ex_response = format_string(data_point['response'])
print(f"Expected output:\n\t{ex_response}")
# Visualize results
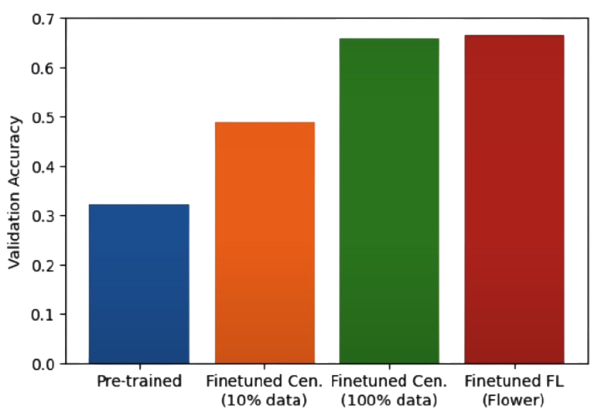
visualize_results(
results=['7b/pretrained', '7b/cen_10', '7b/fl'])
visualize_results(
results=['7b/pretrained', '7b/cen_10',
'7b/cen_full', '7b/fl'],
compact=True)
# Computing communication costs
cfg = get_config("federated")
compute_communication_costs(cfg, comm_bw_mbps=20)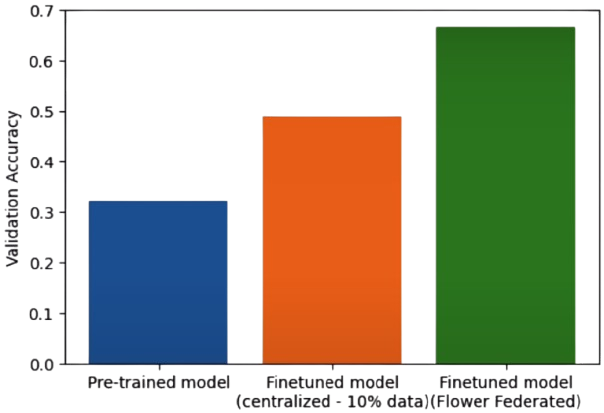

Keeping LLMs Private
LLMs have wide vulnerabilities such as model weight leakage, model IP, prompt jailbreaking, de-anonymization, training algorithm backdoor, and data transfer leakage but the most important one is training data extraction.

Let’s dive into how training data extraction works.
- Step 1 Prompting Possible training data: Generate a series of possible training data examples from LLM. LLM → Prompting method for example: “<start>” → Get possible training data such as joe.smith@beyazev.gov etc. Other clever prompting methods are providing empty field or a string containing keywords that might lead the LLM to produce sensitive pieces of data.
- Step 2 Membership Test: Test each example to determine which were actually in the training data. Possible training data → Membership Test → Confirmed Training Data.
How membership test work?
- Step Perplexity: The first key idea focuses on the use of a metric called perplexity, a popular measure used to evaluate how “surprised” a language model is by a given sequence. Perplexity is calculated as the normalized probability of each token in a sequence being individually produced by the model. Sequences that are not surprising to the model typically align with training examples, as the model often memorizes them. Consequently, a memorized example is less likely to be surprising to the model. By calculating perplexity, we can quantify this level of surprise and determine the likelihood that a sequence originates from training data. This forms the foundation of the first key idea.
- Step Probability of a sequence: LLMs can provide the probability of a token produced given a sequence “Mary lives at 172 Tension St. …”. LLM generates the probability of tokens produced Pr(tokens | seq) = 0.2

The last step to this in this membership test is to take this perplexity example that we’ve now examined how you can calculate and then we examine the value of the perplexity to determine if it’s a low enough to indicate that, the model is surprised or not. Depending on this level of perplexity in the level at which we think a surprise is occurring or not, we can mark the examples being an actual training example or not. And as you would probably imagine there is a wide variety of different approaches for determining this type of threshold as the level of perplexity necessary to say if the model happens to agree that this training candidate is an example from the training dataset.
import csv
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
from utils.utils import get_config, visualize_results, print_config
from utils.mia import calculatePerplexity, plot_mia_results, load_model
from utils.mia import get_evaluation_data, MIA_test, load_extractions
from utils.mia import evaluate_data, analyse
from utils.LLM import LLM_cen, LLM_fl, LLM_pretrained
from utils.LLM import get_fireworks_api_key,load_env
cen_llm = LLM_cen()
# Test with different prompts
prompt = "Peter W"
# Print the prompt and its response
cen_llm.eval(prompt)
output = cen_llm.get_response()
print(f"Prompt: {prompt}")
print(f"Response: {output}")
# Perplexity calculation
print(f"Prompt: {output}")
# Use secondary attribute set to True
cen_llm.eval(output, True)
# Use the calculatePerplexity function
cen_perp = calculatePerplexity(cen_llm.get_response_raw())
print(f"Perplexity: {cen_perp:.3f}")
# Calculating perplexity with other examples
# Training data found on the web
prompt_text = "With the cold weather setting in and the " \
"stress of the Christmas holiday approaching"
# Use secondary attribute set to True
cen_llm.eval(prompt_text, True)
cen_perp = calculatePerplexity(cen_llm.get_response_raw())
print(f"Perplexity (in-dataset): {cen_perp:.3f}")
# Text article from the Guardian
prompt_text = f"No evidence foreign students are abusing " \
"UK graduate visas, review finds"
cen_llm.eval(prompt_text, True)
cen_perp = calculatePerplexity(cen_llm.get_response_raw())
print(f"Perplexity (out-of-dataset): {cen_perp:.3f}")
pre_llm = LLM_pretrained()
prompt_text = "With which class of antimicrobials is Aztreonam "\
"particularly synergistic?",
cen_llm.eval(prompt_text, True)
cen_perp = calculatePerplexity(cen_llm.get_response_raw())
pre_llm.eval(prompt_text, True)
pre_perp = calculatePerplexity(pre_llm.get_response_raw())
print(f"Normalised perplexity: {cen_perp/pre_perp:.3f} ")
fl_llm = LLM_fl()
prompt_list = [
"Among all branchial arches, which arch gives rise "\
"to the stylohyoid muscle and stylohyoid ligament?",
"With which class of antimicrobials is Aztreonam "\
"particularly synergistic?",
"What type of stain can be used when performing "\
"Immunohistochemistry to identify neuroblastomas, "\
"medulloblastomas, and retinoblastomas?",
]
# Print analysis when using Centrally fine-tuned model vs Federated + DP fine-tuned model
print("Analysis Centrally Finetuned model:")
MIA_test(cen_llm, prompt_list)
print("Analysis Federated + DP finetuned model:")
MIA_test(fl_llm, prompt_list)
# Set new configuration
mia_cfg = get_config("mia")
print_config(mia_cfg)
# Load the outputs' models using the large dataset
(fl_fine_tuned_model,
cen_fine_tuned_model,
pre_trained_model, tokenizer) = load_model(mia_cfg)
data = get_evaluation_data(mia_cfg)
plot_mia_results(data,
fl_fine_tuned_model,
cen_fine_tuned_model,
pre_trained_model,
tokenizer,
mia_cfg.key_name)
extraction = load_extractions(mia_cfg.key_name)
extraction.eval()
extraction.show('url')
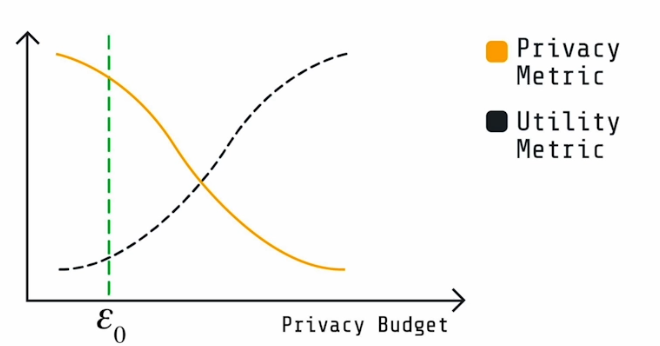
extraction.show('email')We focus on the extraction of training data and discuss a basic perplexity based vulnerability such as membership inference attack. Importantly even the training data of standard LLMs like Mistral 7B where vulnerable. Federated LLMs offer notably improved protection against the extraction of training data relative to centralized LLMs under the fine-tuning process. The key tradeoff exists between privacy and the quality of the model response:
Resource
[1] Deeplearning.ai, (2024), Federated Fine-tuning of LLMs with Private Data:
[https://learn.deeplearning.ai/courses/intro-to-federated-learning-c2/]










0 Comments