

Introduction
An LLM trained on online data mirrors the internet's tone, which might result in dangerous misleading or unhelpful results. RLHF is a fundamental tuning approach that has helped to align an LLM's output with human tastes and values.
RLHF collects answers to train the model to produce more of the replies that humans desire. In RLHF, the LLMs are already instruction-tuned. You then collect a dataset indicating a human label's preferences between many completions of the same prompt and utilize it as a reward signal or to generate a reward signal to fine-tune an instruction, resulting in an instruction-tuned LLM. The end result is an LLM that produces output that is more consistent with the preferences of the human labellers.
In this course, we will learn about the RLHF procedure and gain hands-on experience by investigating simple datasets for RLHF, modifying the LLAMA model using RLHF, and assessing the newly tuned model.
RLHF is mostly used to improve LLM's capacity to solve issues whose desired outcome is difficult to articulate or understand. RLHF does not solve all veracity or toxicity issues, but it is an important step in improving the quality of such models. For example, the Nemotron RLHF Llama3-70b model and the Llama3-70b model both have ten models on the LLM Arena Leaderboard, which is based completely on human desire.
How Does RLHF Work?
RLHF is a strategy for better aligning an LLM's output with user purpose and choice. Suppose we want to RLHF a model for summarizing jobs. We may begin by collecting some text samples to summarize, and then have humans create a summary for each input.
We can generate pairs of input text and summaries using human-created summaries and train a model directly on a large number of these pairs. The problem is that there is no single correct way to summarize a piece of text because natural languages are flexible and there are frequently multiple ways to state the same idea. Some issues, such as entity extraction or classification, have proper answers, but the task we wish to teach the model requires a more objective optimal response. Instead of attempting to discover the greatest summary for a specific piece of input text, we will approach this problem slightly differently. Generate a summary for each input.
RLHF consists of three stages: first, we construct a preference dataset, which we then utilize to train a reward model using supervised learning. Finally, we employ the reward model in a reinforcement learning loop to fine-tune our fundamental large language model.

A preference dataset is constructed by requiring humans to select one of two outputs for a single input. This is the most difficult phase since you must establish your criteria by asking yourself what you hope to achieve by tuning. Do you want to make the model more useful, less harmful, or more positive?
Next, you use this preference information to train a reward model, typically an LLM. Inference: We want this reward model to accept prompt and completion and return a scalar indicating how good the completion is.
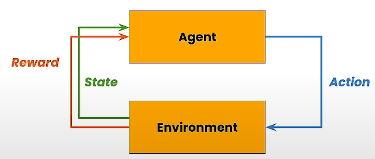
Let us remember reinforcement learning. In reinforcement learning, an agent performs an action to modify the environment and receives a reward based on the defined scoring function; this cycle continues. The function that maps the current state to a set of actions is known as a Policy, and the purpose of reinforcement learning is to learn a policy that maximizes reward.
A prompt is selected from the prompt dataset, passed to the big language model to provide a completion, and then passed to the reward model to generate a score or reward. The weights of the base large language model, also known as policy, are updated via PPO with the reward. Each update improves the policy's ability to output a line of text. In practice, you typically include a penalty term to guarantee that the tuned model does not deviate too much from the base model.
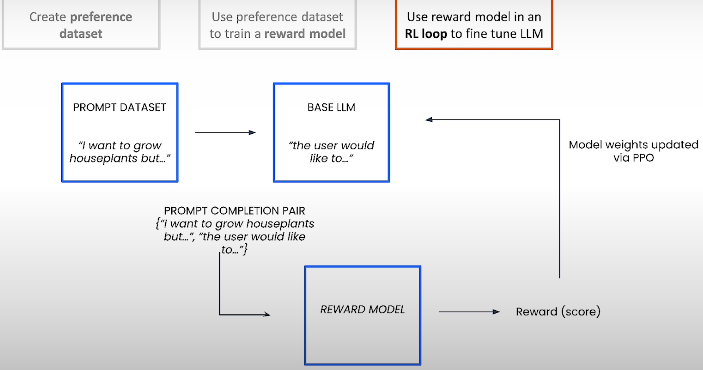
For further information, see OpenAI and Deepmind's "Deep Reinforcement Learning from Human Preferences" and Ouyang, Wu, and Jiang's "Training language models to follow instructions with human feedback" articles.
Parameter-efficient fine-tuning retrains the base model but only updates a limited subset of the model parameters, leaving the other parameters unchanged, whereas full fine-tuning retrains the base model by updating all parameters (model weights).
Datasets For RL Training
The preference dataset is used to calibrate the reward model. It is frequently one of the most difficult aspects of RLHF since it is annotated by humans, and everyone has different preferences.
preference_dataset_path = 'sample_preference.jsonl'
import json
preference_data = []
with open(preference_dataset_path) as f:
for line in f:
preference_data.append(json.loads(line))
sample_1 = preference_data[0]
print(type(sample_1))
# This dictionary has four keys
print(sample_1.keys())
sample_1['input_text']
# Try with another examples from the list, and discover that all data end the same way
preference_data[2]['input_text'][-50:]
print(f"candidate_0:\n{sample_1.get('candidate_0')}\n")
print(f"candidate_1:\n{sample_1.get('candidate_1')}\n")
print(f"choice: {sample_1.get('choice')}")
prompt_dataset_path = 'sample_prompt.jsonl'
prompt_data = []
with open(prompt_dataset_path) as f:
for line in f:
prompt_data.append(json.loads(line))
# Check how many prompts there are in this dataset
len(prompt_data)
# Function to print the information in the prompt dataset with a better visualization
def print_d(d):
for key, val in d.items():
print(f"key:{key}\nval:{val}\n")
print_d(prompt_data[0])
# Try with another prompt from the list
print_d(prompt_data[1])Tune an LLM with RLHF
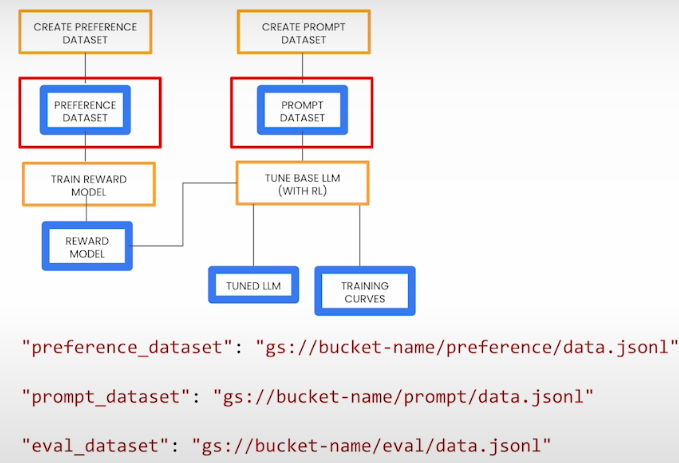
Let's start the RLHF procedure by tuning a huge language model. Machine learning pipelines are containerized machine learning operations that are portable and scalable. Each phase of your workflow, such as data preparation, model training, and model evaluation, is a component of your pipeline. A pipeline is a straightforward approach to combine all of these processes into a single object, allowing you to automate and replicate your machine-learning workflow. A reinforcement learning pipeline based on human feedback is slightly more difficult. It might look like this:
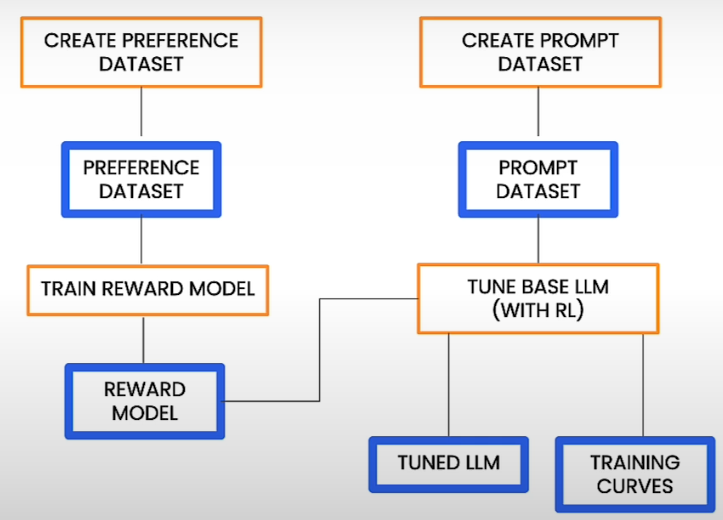
The preference dataset is utilized to build a reward model. The reward model is combined with the prompt dataset to adapt the base big language model using reinforcement learning. Finally, we use reinforcement learning to create a tuned large language model. Then we have a tweaked big language model and some outputted training curves. In truth, the pipeline that we are intending to implement has many more steps, but more on that later. The RLHF pipeline is in the OSS Google Cloud Pipelines Components Library. To run the pipeline, first import, compile, then execute it. So we'll need to make sure we have a variety of libraries installed.
!pip3 install google-cloud-pipeline-components
!pip3 install kfp# COMPILE THE PIPELINE
# Import (RLFH is currently in preview)
from google_cloud_pipeline_components.preview.llm \
import rlhf_pipeline
# Import from KubeFlow pipelines
from kfp import compiler
# Define a path to the yaml file
RLHF_PIPELINE_PKG_PATH = "rlhf_pipeline.yaml"
# Execute the compile function
compiler.Compiler().compile(
pipeline_func=rlhf_pipeline,
package_path=RLHF_PIPELINE_PKG_PATH
)
# Print the first lines of the YAML file
!head rlhf_pipeline.yaml
Even for your projects, you will not be altering this RLHF pipeline component or the related YAML file. The Vertex team has previously designed and optimized the pipeline for the platform and RLHF, and the YAML file is generated automatically. We may create a pipeline task that accepts both the YAML file and all of the parameters appropriate to our use case.
Define the Vertex AI pipeline job
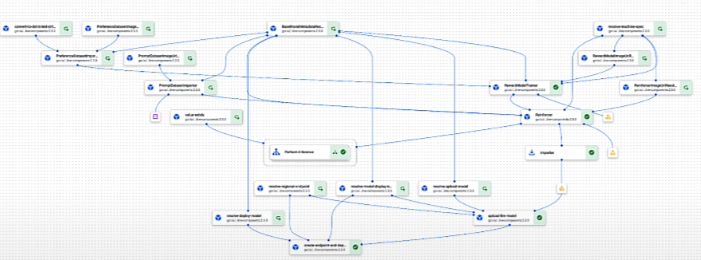
If we zoom in on the specific part of the pipeline on the right upper side:
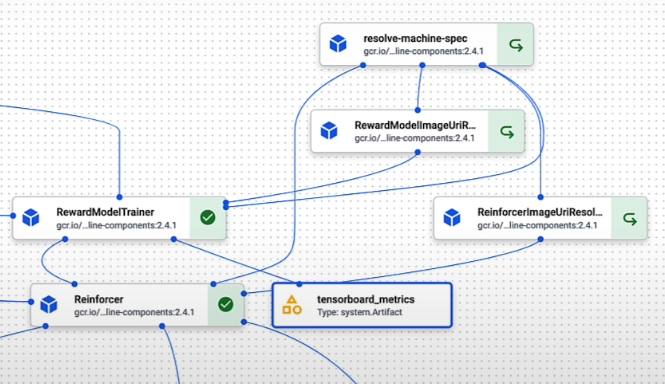
The reward model pipeline is made up of learned reward models. Reinforcer is the reinforcement learning loop that adjusts the base big model. You can also notice that the reward model trainer component generates measurements listed in the TensorBoard measurements Artifact.
Vertex AI provides a visualization tool for viewing all of your pipeline's components.
Define the location of the training and evaluation data
Previously, datasets were loaded from short JSONL files, but for most training projects, datasets are much larger and stored in cloud storage (in this example, Google Cloud Storage).
Note: Ensure the three datasets are stored in the same Google Cloud Storage bucket.
The first three options specify the path to our preferred dataset, prompt dataset, and evaluation dataset. The evaluation dataset is optional, which implies that once tuning is complete, it will be utilized to run a batch inference operation that will generate a number of completions for a number of prompts.
parameter_values={
"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/summarize_from_feedback_tfds/comparisons/train/*.jsonl",
"prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/train/*.jsonl",
"eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/val/*.jsonl",
...We load small JSONL files as datasets into memory but in a actual pipeline, datasets are much larger and they need to exist somewhere called Google Cloud Storage (Google’s Cloud Storage) where you can store images, CSV files, text files, save model artifacts, JSONL files. Google Cloud Storage paths start with gs:// prefix. Everything in Google Cloud Storage is stored in buckets.
Choose the foundation model to be tuned
In this scenario, we are modifying the Llama-2 foundational model, referred to as large_model_reference.
In this course, we're tuning the llama-2-7b, but you can also use Vertex AI's RLHF pipeline to tune models like the T5x or text-bison@001.
parameter_values={
"large_model_reference": "llama-2-7b",
...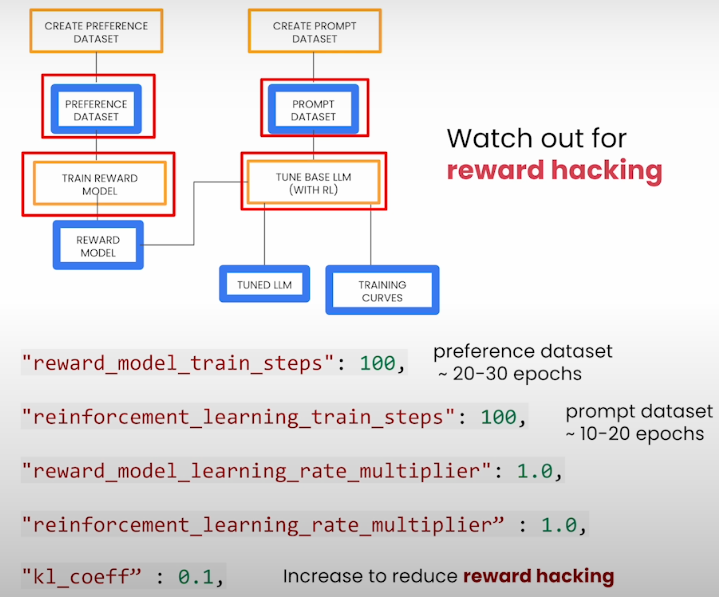
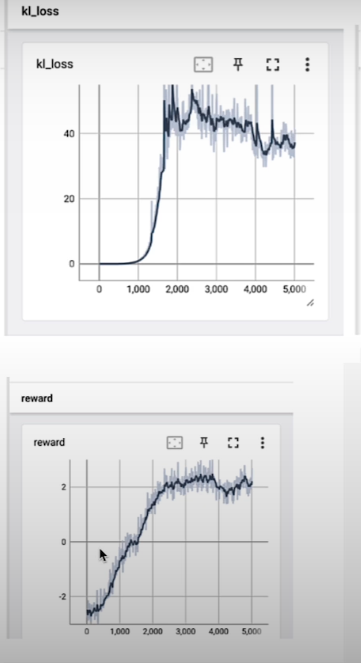
Train steps are experimental since the data size varies; the default settings are 20-30 epochs for reward model training and 10-20 epochs for reinforcement learning training. You cannot modify the earning rate since they must match, but you can change the learning rate multiplier to influence them. The KL coefficient is a regularization term that helps to prevent behavior known as reward hacking. For example, if positive sentiments have high rewards, the model begins to say awesome, terrific, and perfect, which results in a high score but is meaningless to humans.
Calculate the number of reward model training steps
The reward_model_train_steps parameter specifies the number of steps to take when training the reward model. This is dependent on the size of your preferred dataset. To achieve the best results, we propose training the model on the preference dataset for 20-30 epochs.
steps_per_epoch = ⌈dataset_size / batch_size⌉
train_steps = steps_per_epoch x num_epochs
The RLHF pipeline settings call for the number of training steps rather than the number of epochs. Here's an example of how to transition from epochs to training steps, assuming that the batch size for this pipeline is 64 examples per batch.
# Preference dataset size
PREF_DATASET_SIZE = 3000
# Batch size is fixed at 64
BATCH_SIZE = 64
import math
REWARD_STEPS_PER_EPOCH = math.ceil(PREF_DATASET_SIZE / BATCH_SIZE)
print(REWARD_STEPS_PER_EPOCH)
REWARD_NUM_EPOCHS = 30
# Calculate number of steps in the reward model training
reward_model_train_steps = REWARD_STEPS_PER_EPOCH * REWARD_NUM_EPOCHS
print(reward_model_train_steps)Calculate the number of reinforcement learning training steps
The reinforcement_learning_train_steps parameter specifies the number of reinforcement learning steps to be performed while tuning the basic model.
* The number of training steps is determined by the size of your prompt dataset. Typically, this model should train on the prompt dataset over 10-20 epochs.
* incentive hacking: if the policy model is given too many training steps, it may find a way to abuse the incentive and engage in undesirable behavior.
# Prompt dataset size
PROMPT_DATASET_SIZE = 2000
# Batch size is fixed at 64
BATCH_SIZE = 64
import math
RL_STEPS_PER_EPOCH = math.ceil(PROMPT_DATASET_SIZE / BATCH_SIZE)
print(RL_STEPS_PER_EPOCH)
RL_NUM_EPOCHS = 10
# Calculate the number of steps in the RL training
reinforcement_learning_train_steps = RL_STEPS_PER_EPOCH * RL_NUM_EPOCHS
print(reinforcement_learning_train_steps)Define the instruction
- Select the task-specific instruction you want to apply to customize the basic model. For this example, the instruction is to "summarize in less than 50 words."
- You can specify other directions, such as "Write a response to the following question or comment.". It is important to note that you must also gather your preference dataset with the same instruction appended to the prompt, so that both the responses and the human preferences are based on that instruction.
# Completed values for the dictionary
parameter_values={
"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/summarize_from_feedback_tfds/comparisons/train/*.jsonl",
"prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/train/*.jsonl",
"eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/val/*.jsonl",
"large_model_reference": "llama-2-7b",
"reward_model_train_steps": 1410,
"reinforcement_learning_train_steps": 320, # results from the calculations above
"reward_model_learning_rate_multiplier": 1.0,
"reinforcement_learning_rate_multiplier": 1.0,
"kl_coeff": 0.1, # increased to reduce reward hacking
"instruction":\
"Summarize in less than 50 words"}Train with full dataset: dictionary ‘parameter_values’
- To achieve the best results in the evaluation (next lesson), adjust the training settings for the entire dataset. Take a look at the new values; they represent the outcomes of numerous training experiments in the pipeline, with the best parameter values shown here.
parameter_values={
"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/summarize_from_feedback_tfds/comparisons/train/*.jsonl",
"prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/reddit_tfds/train/*.jsonl",
"eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/reddit_tfds/val/*.jsonl",
"large_model_reference": "llama-2-7b",
"reward_model_train_steps": 10000,
"reinforcement_learning_train_steps": 10000,
"reward_model_learning_rate_multiplier": 1.0,
"reinforcement_learning_rate_multiplier": 0.2,
"kl_coeff": 0.1,
"instruction":\
"Summarize in less than 50 words"}Set up Google Cloud to run the Vertex AI pipeline
Vertex AI has already been installed in this classroom environment. If you were using this in your project, you would install Vertex AI SDK as follows:
!pip3 install google-cloud-aiplatform# Authenticate in utils
from utils import authenticate
credentials, PROJECT_ID, STAGING_BUCKET = authenticate()
# RLFH pipeline is available in this region
REGION = "europe-west4"Run the pipeline job on Vertex AI
After we've generated our dictionary of values, we can create a PipelineJob. This just implies that the RLHF pipeline will run on Vertex AI. So it's operating on a Google Cloud server rather than locally in the laptop.
import google.cloud.aiplatform as aiplatform
aiplatform.init(project = PROJECT_ID,
location = REGION,
credentials = credentials)
# Look at the path for the YAML file
RLHF_PIPELINE_PKG_PATHCreate and run the pipeline job
- Here's how you'd build and run the pipeline job if you were working on your own project.
This work takes nearly a full day to complete with several accelerators (TPUs/GPUs), so we won't be running it in this classroom.
# To create the pipeline job
job = aiplatform.PipelineJob(
display_name="tutorial-rlhf-tuning",
pipeline_root=STAGING_BUCKET,
template_path=RLHF_PIPELINE_PKG_PATH,
parameter_values=parameter_values)
# To run the pipeline job
job.run()The content team used this RLHF training pipeline to tune the Llama-2 model, and in the following session, you'll be able to assess the log data and compare the performance of the tuned model to the original basic model.
Evaluate the Tuned Model

Our ultimate goal using RLHF is to develop a new big language model that outperforms the original LLM at the task we care about. LLM assessment is a very difficult subject that still requires research.
First, we examine the loss to determine if the model is learning. Second, we consider automation metrics, which are algorithmic evaluation approaches.
Side-by-side comparisons can be performed manually or automatically. Auto SxS compares the performance of two models using an arbiter model rather than a human-labeled one.
ROUGE is not helpful for human alignment; it only indicates how similar texts are. Some studies have also found that the more aggressively we optimize the model to ROUGE, the worse the model performance in the RLHF situation.
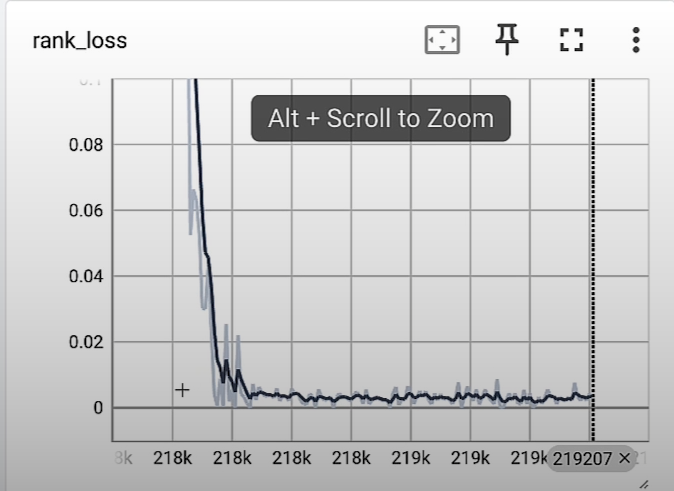
We look at the rank_loss and expect to see a graph that is decreasing and converging, staying stable at a point close to zero.
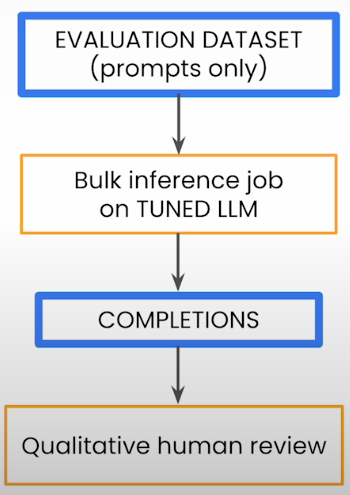
The assessment dataset contains only summarization questions, with no completions. This dataset is simply provided to the tuned model during a bulk inference job. After we've calibrated our model, we'll generate completions for all of the prompts in the assessment dataset. We do not calculate any metrics. We're basically calling the model and creating some text output.
!pip install tensorboard
%load_ext tensorboard
port = %env PORT1
%tensorboard --logdir reward-logs --port $port --bind_all
# Look at what this directory has
%ls reward-logs
port = %env PORT2
%tensorboard --logdir reinforcer-logs --port $port --bind_all
port = %env PORT3
%tensorboard --logdir reinforcer-fulldata-logs --port $port --bind_all
# The dictionary of 'parameter_values' defined in the previous lesson
parameter_values={
"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/summarize_from_feedback_tfds/comparisons/train/*.jsonl",
"prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/train/*.jsonl",
"eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/val/*.jsonl",
"large_model_reference": "llama-2-7b",
"reward_model_train_steps": 1410,
"reinforcement_learning_train_steps": 320,
"reward_model_learning_rate_multiplier": 1.0,
"reinforcement_learning_rate_multiplier": 1.0,
"kl_coeff": 0.1,
"instruction":\
"Summarize in less than 50 words"}
"""
Note: Here, we are using 'text_small' for our datasets for learning purposes. However for the results that we're evaluating in this lesson, the team used the full dataset with the following hyperparameters:
"""
parameter_values={
"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/summarize_from_feedback_tfds/comparisons/train/*.jsonl",
"prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/reddit_tfds/train/*.jsonl",
"eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/reddit_tfds/val/*.jsonl",
"large_model_reference": "llama-2-7b",
"reward_model_train_steps": 10000,
"reinforcement_learning_train_steps": 10000,
"reward_model_learning_rate_multiplier": 1.0,
"reinforcement_learning_rate_multiplier": 0.2,
"kl_coeff": 0.1,
"instruction":\
"Summarize in less than 50 words"}
# Evaluate using the tuned and untuned model
import json
eval_tuned_path = 'eval_results_tuned.jsonl'
eval_data_tuned = []
with open(eval_tuned_path) as f:
for line in f:
eval_data_tuned.append(json.loads(line))
# Import for printing purposes
from utils import print_d
# Look at the result produced by the tuned model
print_d(eval_data_tuned[0])
eval_untuned_path = 'eval_results_untuned.jsonl'
eval_data_untuned = []
with open(eval_untuned_path) as f:
for line in f:
eval_data_untuned.append(json.loads(line))
# Look at the result produced by the untuned model
print_d(eval_data_untuned[0])
# Explore the results side by side in a dataframe
# Extract all the prompts
prompts = [sample['inputs']['inputs_pretokenized']
for sample in eval_data_tuned]
# Completions from the untuned model
untuned_completions = [sample['prediction']
for sample in eval_data_untuned]
# Completions from the tuned model
tuned_completions = [sample['prediction']
for sample in eval_data_tuned]
import pandas as pd
results = pd.DataFrame(
data={'prompt': prompts,
'base_model':untuned_completions,
'tuned_model': tuned_completions})
pd.set_option('display.max_colwidth', None)
# Print the results
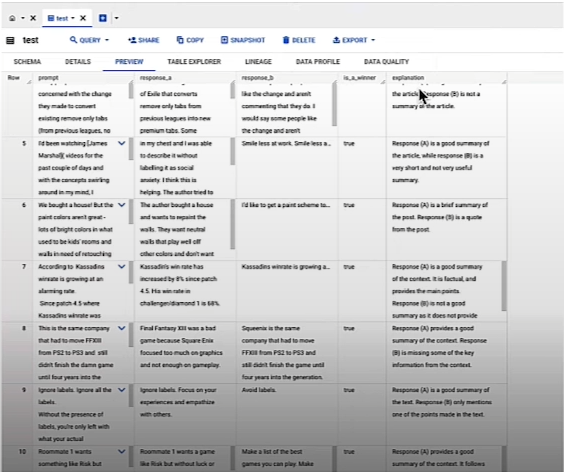
results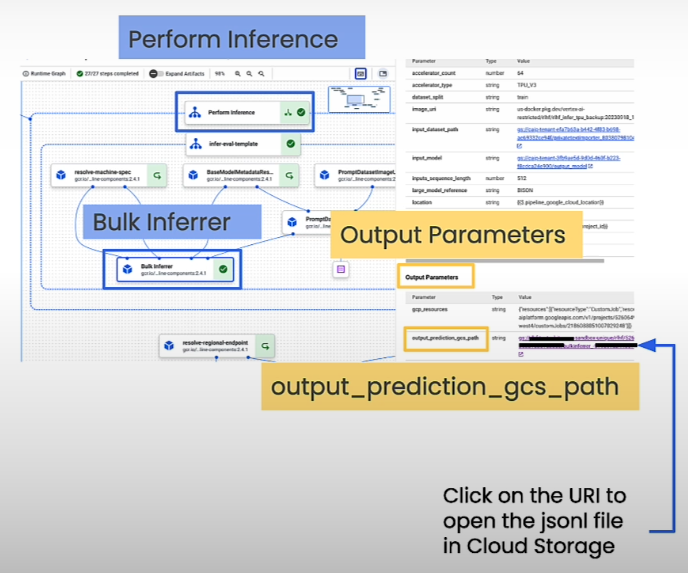
Similarly, auto side by side (AutoSxS) assesses the performance of two models via an arbiter model rather than a human labeller. An LLM determines which is better and explains why.
Extra: Google Cloud Setup
Google Cloud setup
This optional lab describes the processes required to leverage Google Cloud and Vertex AI for your projects.
Please download this notebook and run it on your own computer to see how it works.
Create a Google Cloud Project
Google Cloud projects serve as the foundation for developing, enabling, and utilizing all Google Cloud services, including API management, billing enablement, collaborator addition and removal, and Google Cloud resource authorization management.
Your use of Google Cloud tools is always tied to a project.
When you first visit the Cloud Console, you will be requested to start a new project.
You can create a free project that includes a 90-day $300 free trial.
Learn more about the projects here.
Set up Billing
A Cloud Billing account is used to determine who pays for a specific set of resources and can be associated with one or more projects. Project utilization is invoiced to the associated Cloud Billing account.
You can configure billing in your project by selecting "Billing" from the menu on the left.
Make sure billing is enabled for your Google Cloud project; click here to discover how to confirm billing.
Enable APIs
Once you've established a project with a billing account, you'll need to enable any services you intend to use.
Click here to enable the following APIs in your Google Cloud project:
- Vertex AI
- BigQuery
- IAM
Create service account
A service account is a type of account that is often utilized by an application or compute task, such as a Compute Engine instance, rather than a user. A service account is recognized by its email address, which is unique to each account. For more information, see this introduction video.
You will need to create a service account and grant it access to the Google Cloud services you intend to use.
1. Go to the Create Service Account page and select your project
2. Give the account a name (you can pick anything)

Grant the account the following permissions
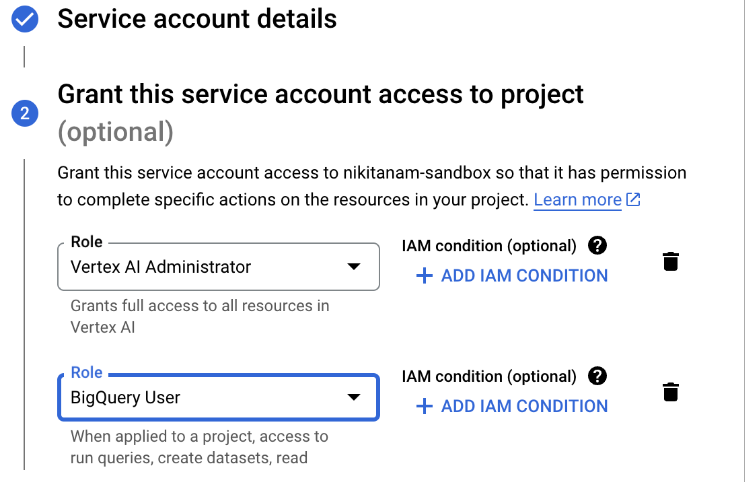
Create Service Account key
Once you have created your service account, you need to create a key.
1. Select your newly created service account then click. ADD KEY -> create new key.
2. Select JSON key type and click create

Clicking Create downloads a service account key file. After you download the key file, you cannot download it again.
Create credentials
To use Vertex AI services, you will need to authenticate with your credentials.
Using the JSON file you just downloaded, you will create a credentials object.
from google.auth.transport.requests import Request
from google.oauth2.service_account import Credentials
# Path to your service account key file
key_path = 'your_key.json' #Path to the JSON key associated with your service account from Google Cloud
# Create credentials object
credentials = Credentials.from_service_account_file(
key_path,
scopes=['https://www.googleapis.com/auth/cloud-platform'])
if credentials.expired:
credentials.refresh(Request())Set up a Google Cloud Storage Bucket
Cloud Storage is Google Cloud's object storage. Object storage allows you to save photos, CSV files, TXT files, and saved model artifacts—just about everything!
Cloud storage uses the concept of a "bucket" to hold your data.
Everything stored in Cloud Storage must be contained within a bucket. Within a bucket, you can organize your data by creating folders.
Every file in Cloud Storage has a path, just like any file on your local file system. Except that Cloud Storage paths always begin with gs://.
Create a new bucket
Click here to go to the Cloud Storage section of the Cloud Console or navigate there manually by selecting Cloud Storage > Buckets from the hamburger menu in the Cloud Console.
Select CREATE
Give your bucket a name, set the region, and click CREATE.
In general, the optimal region to choose will be determined by your location and the requirements of the service with which you intend to use this data.
The US or EU multiregion are suitable defaults.
Once you have created your bucket, you can upload files or create directories.
The path to your bucket is gs://{name_of_your_bucket}
Connect to Vertex AI
You can use Vertex AI tools once you've completed your project and verified your credentials.
Copy your project ID and paste it in the PROJECT_ID field below.
PROJECT_ID = 'your_project_ID'
REGION = 'us-central1'
import google.cloud.aiplatform as aiplatform
# Initialize vertex
aiplatform.init(project = PROJECT_ID, location = REGION, credentials = credentials)Resource
Deeplearning.ai, (2024), Reinforcement Learning from Human Feedback
[https://www.deeplearning.ai/short-courses/reinforcement-learning-from-human-feedback/]










0 Comments