
Deeplearning.ai “Improving Accuracy of LLM Applications” short course.

Introduction
AI applications may now execute things that were previously difficult for computers, such as presenting a natural language interface to a database. However, these programs frequently perform well in some areas while struggling in others. You will discover a framework for development phases that will allow you to gradually increase the performance of your application. Specifically, you generate an assessment dataset to measure performance, then undertake quick engineering and fine-tune your model.
One important feature of these open-source LLMs is that they allow users to fine-tune the models for specific needs. We've seen various applications, particularly with smaller models that users have fine-tuned for tasks such as text to SQL, categorization, question and answer, recommendation, and summarization. They have also been trained to analyze proprietary datasets such as financial, consumer, and legal data.
In this session, you will first create your LLM application, connect it all together, and perform prompt engineering with some self-reflection. Next, rigorously evaluate the model's performance to see whether it is ready for prime time and where you may direct it to improve to reach the next level of accuracy. If quick engineering is insufficient, the next stage is to employ LLMs and generate a dataset for fine-tuning your model. One fallacy about this phase is that you don't have enough data. There is enough data, and LLMs can dramatically amplify the data you already have. Finetuning used to be sluggish and costly, but by utilizing parameter-efficient approaches like LoRA (Low-Rank) which stands for Low-Rank Adaptation, the time and costs have dropped dramatically.
Lamini memory tuning is a technique that opens up a new field of factual accuracy, decreasing time and developer work while maintaining or improving accuracy. Using advanced fine-tuning approaches, you can teach your LLM a thousand new facts in minutes with a single A100 or MI2 50 GPU.
We will demonstrate fine-tuning an LLM to generate SQL queries for a certain schema. Fine-tuning will enhance accuracy from around 30% to 95% using a small dataset of 128 examples in around 30 minutes for a few bucks. This process can be sped up to 6 or 7 seconds by adjusting the memory performance.
Overview
LLMs are probabilistic so we need to work iterative.

from dotenv import load_dotenv
import lamini
_ = load_dotenv() #load environmental variable LAMINI_API_KEY with key from .env file
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
prompt = """\
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Please write a birthday card for my good friend Andrew\
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
result = llm.generate(prompt, max_new_tokens=200)
print(result)Python Enhancement Proposals (PEP 8) gives you a style guide for Python and suggests that long lines can be broken over multiple lines by wrapping expressions in parentheses.
prompt2 = (
"<|begin_of_text|>" # Start of prompt
"<|start_header_id|>system<|end_header_id|>\n\n" # header - system
"You are a helpful assistant." # system prompt
"<|eot_id|>" # end of turn
"<|start_header_id|>user<|end_header_id|>\n\n" # header - user
"Please write a birthday card for my good friend Andrew"
"<|eot_id|>" # end of turn
"<|start_header_id|>assistant<|end_header_id|>\n\n" # header - assistant
)
print(prompt2)
print(prompt == prompt2) # TrueLet’s create a method that will generate a prompt from user and system messages.
def make_llama_3_prompt(user, system=""):
system_prompt = ""
if system != "":
system_prompt = (
f"<|start_header_id|>system<|end_header_id|>\n\n{system}"
f"<|eot_id|>"
)
prompt = (f"<|begin_of_text|>{system_prompt}"
f"<|start_header_id|>user<|end_header_id|>\n\n"
f"{user}"
f"<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>\n\n"
)
return prompt
system_prompt = user_prompt = "You are a helpful assistant."
user_prompt = "Please write a birthday card for my good friend Andrew"
prompt3 = make_llama_3_prompt(user_prompt, system_prompt)
print(prompt3)
print(prompt == prompt3) # True
You can use our new method like below:
user_prompt = "Tell me a joke about birthday cake"
prompt = make_llama_3_prompt(user_prompt)
print(prompt)
result = llm.generate(prompt, max_new_tokens=200)
print(result)Llama3 SQL Generation
question = (
"Given an arbitrary table named `sql_table`, "
"write a query to return how many rows are in the table."
)
prompt = make_llama_3_prompt(question)
print(llm.generate(prompt, max_new_tokens=200))
question = """Given an arbitrary table named `sql_table`,
help me calculate the average `height` where `age` is above 20."""
prompt = make_llama_3_prompt(question)
print(llm.generate(prompt, max_new_tokens=200))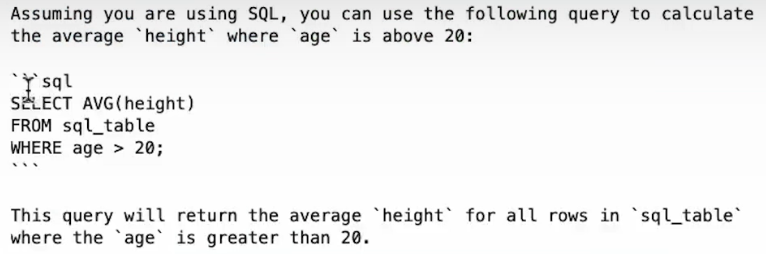
question = """Given an arbitrary table named `sql_table`,
Can you calculate the p95 `height` where the `age` is above 20?"""
prompt = make_llama_3_prompt(question)
print(llm.generate(prompt, max_new_tokens=200))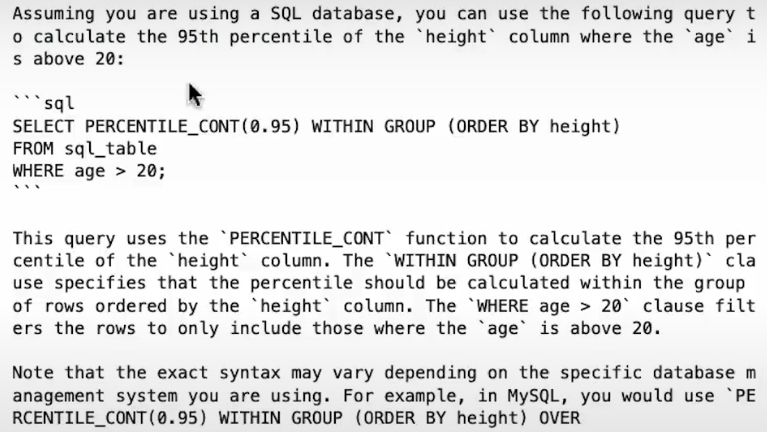
question = ("Given an arbitrary table named `sql_table`, "
"Can you calculate the p95 `height` "
"where the `age` is above 20? Use sqlite.")
prompt = make_llama_3_prompt(question)
print(llm.generate(prompt, max_new_tokens=200))
For LLMs, a slightly accurate answer is equivalent to a correct answer. These partially right replies may be OK for creative activities such as saying hi instead of hello, but for facts requiring precision such as APIs, IDs, phone numbers, and so on, they can be damaging.

For the SQL generation case, PERCENTILE_CONT is not available in SQLite.

To solve this:
- Prompt Engineering →26%
- Self-reflection → 26–40%
- Retrieval Augmented Generation (RAG) → 50%
- Instruction Finetuning → 40–60%
How can fine-tuning help?
There is a method of fine-tuning that involves embedding facts into the model, however instruction fine-tuning, the most prevalent type of fine-tuning, is not the instrument for removing hallucinations and can be costly. Lamini created a technique known as memory tuning, which allows the model to recall a large number of facts precisely by embedding the information directly into the model's weights and introducing a small amount of determinism into this highly probabilistic process. Memory tuning seeks to reduce the likelihood of answering simply facts in factual type inquiries.
Below are the hallucinations in SQL agents:
- Invalid SQL: Missed column names, IDs, formats or functions.
- Malformed SQL: Valid but semantically wrong SQL queries.
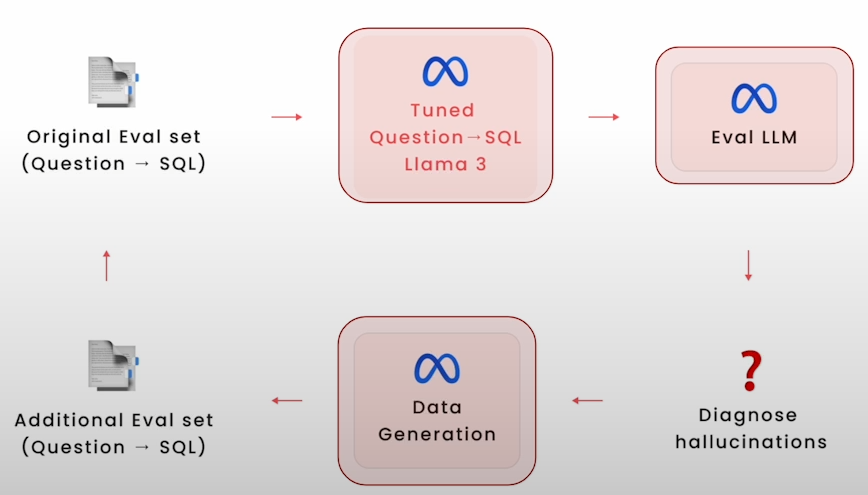
Do not forget that you need to iterate 3 times on eval, data generation and fine-tuning using Memory Tuning.
Create an SQL Agent
Let’s build an SQL Agent and observe where the model hallucinates.
First, do prompt engineering like this:
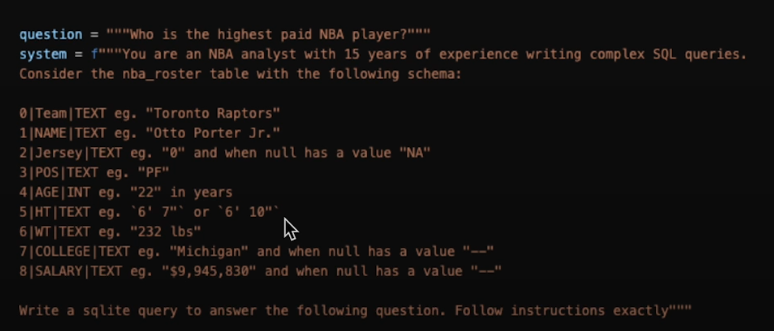
Next, use structured output to ensure it only outputs SQL.

Later diagnosed hallucinations such as wrong salary format, and wrong query.
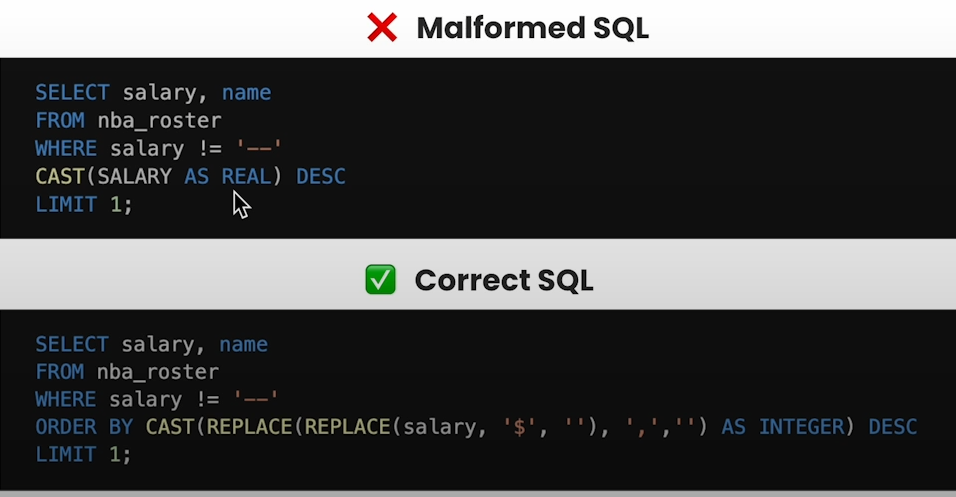
Creating a SQL Agent:
from dotenv import load_dotenv
_ = load_dotenv() #load environmental variable LAMINI_API_KEY with key from .env file
import lamini
import logging
import sqlite3
import pandas as pd
from util.get_schema import get_schema
from util.make_llama_3_prompt import make_llama_3_prompt
from util.setup_logging import setup_logging
logger = logging.getLogger(__name__)
engine = sqlite3.connect("./nba_roster.db")
setup_logging()
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
# Meta Llama 3 Instruct uses a prompt template, with special tags used to indicate the user query and system prompt.
# You can find the documentation on this [model card](https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3/#meta-llama-3-instruct).
def make_llama_3_prompt(user, system=""):
system_prompt = ""
if system != "":
system_prompt = (
f"<|start_header_id|>system<|end_header_id|>\n\n{system}<|eot_id|>"
)
return f"<|begin_of_text|>{system_prompt}<|start_header_id|>user<|end_header_id|>\n\n{user}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
def get_schema():
return """\
0|Team|TEXT
1|NAME|TEXT
2|Jersey|TEXT
3|POS|TEXT
4|AGE|INT
5|HT|TEXT
6|WT|TEXT
7|COLLEGE|TEXT
8|SALARY|TEXT eg.
"""
user = """Who is the highest paid NBA player?"""
system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""
print(system)
prompt = make_llama_3_prompt(user, system)
print(llm.generate(prompt, max_new_tokens=200))
def get_updated_schema():
return """\
0|Team|TEXT eg. "Toronto Raptors"
1|NAME|TEXT eg. "Otto Porter Jr."
2|Jersey|TEXT eg. "0" and when null has a value "NA"
3|POS|TEXT eg. "PF"
4|AGE|INT eg. "22" in years
5|HT|TEXT eg. `6' 7"` or `6' 10"`
6|WT|TEXT eg. "232 lbs"
7|COLLEGE|TEXT eg. "Michigan" and when null has a value "--"
8|SALARY|TEXT eg. "$9,945,830" and when null has a value "--"
"""
system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_updated_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""
prompt = make_llama_3_prompt(user, system)
print(prompt)
print(llm.generate(prompt, max_new_tokens=200))Getting structured output:
result = llm.generate(prompt, output_type={"sqlite_query": "str"}, max_new_tokens=200)
print(result)
df = pd.read_sql(result['sqlite_query'], con=engine)
print(df)Diagnosing Hallucinations:
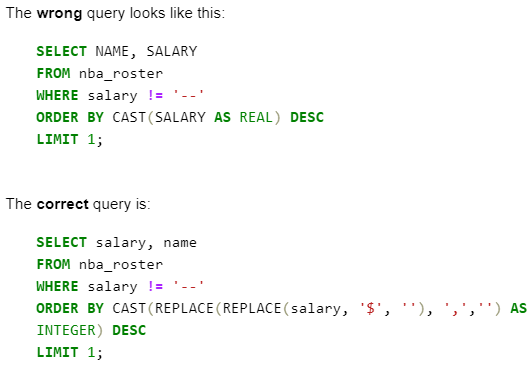
query="""SELECT salary, name
FROM nba_roster
WHERE salary != '--'
ORDER BY CAST(REPLACE(REPLACE(salary, '$', ''), ',','') AS INTEGER) DESC
LIMIT 1;"""
df = pd.read_sql(query, con=engine)
print(df)Create an Evaluation
In this session, you will create an evaluation framework for measuring performance systematically.
We are evaluating LLMs to determine where they are hallucinating, with a quantifiable number to determine whether the accuracy is increasing. A good evaluation is quantifiable, indicates areas for development, and is scalable and automated.
To have an evaluation dataset. Start with 20-100 instances to build a decent dataset.
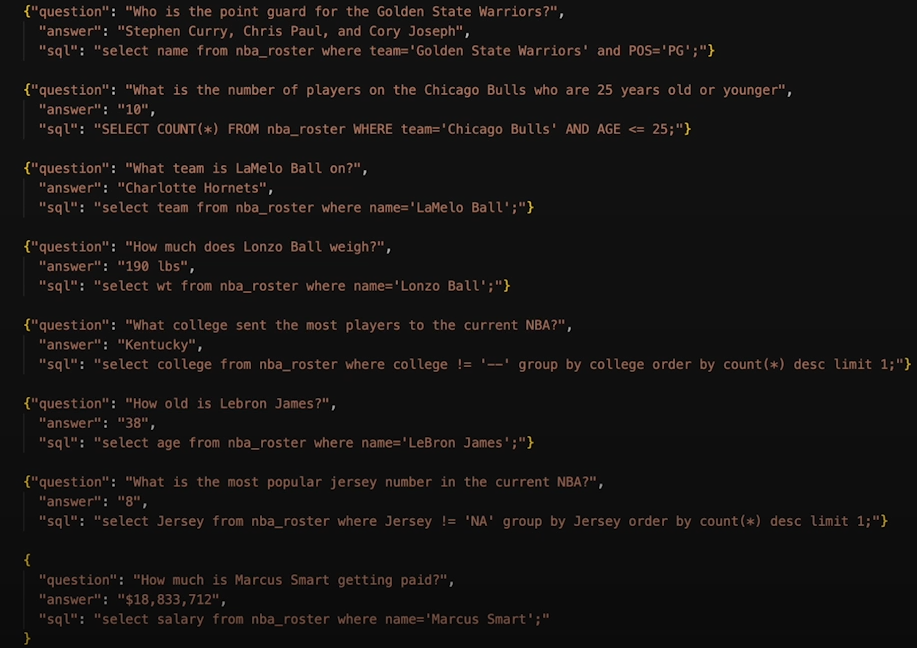
Use an LLM to score your output.
Get the LLM to generate a numerical score.
Provide the question, generated response, and scoring method using the prompt on your eval LLM.
The structured output returns the score in several formats, including int, float, List[int], and so on.
Alternatively, compute traditional exact match, precision, F1, etc.
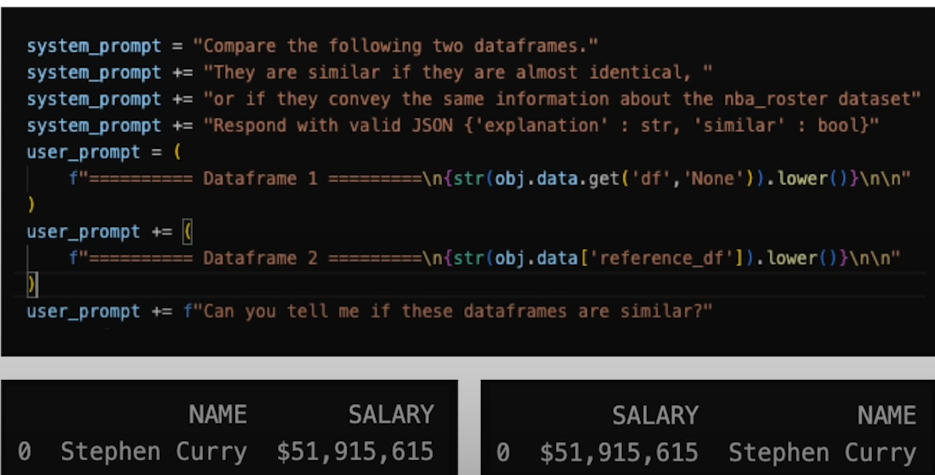
Score similarity of generated to reference SQL, with LLM:
- Generated SQL may be a correct semantic match, but not an exact match.

- When possible, deterministic systems are nevertheless useful for evaluation.
Execute the generated SQL against the database, comparing exact matches.
Bonus points for memory tuning: You can get away with an exact match by programming the LLM to yield precise matches!
Evaluation is iterative; as you improve the model, you'll broaden your evaluation dataset and improve your scoring mechanism to catch errors, add more difficult hallucination examples, and be meticulous about tracking evaluation results across iterations so you know which models produce which results.
from dotenv import load_dotenv
_ = load_dotenv() #load environmental variable LAMINI_API_KEY with key from .env file
!cat data/gold-test-set.jsonl
question = "What is the median weight in the NBA?"
import lamini
from util.get_schema import get_schema
from util.make_llama_3_prompt import make_llama_3_prompt
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""
prompt = make_llama_3_prompt(question, system)
generated_query = llm.generate(prompt, output_type={"sqlite_query": "str"}, max_new_tokens=200)
print(generated_query)
# {'sqlite_query': "SELECT AVG(CAST(SUBSTR(WT, INSTR(WT,'') + 1) AS INTEGER) FROM nba_roster WHERE WT IS NOT NULL"}
import pandas as pd
import sqlite3
engine = sqlite3.connect("./nba_roster.db")
# This creates an error: df = pd.read_sql(generated_query['sqlite_query'], con=engine)
import pandas as pd
import sqlite3
engine = sqlite3.connect("./nba_roster.db")
try:
df = pd.read_sql(generated_query['sqlite_query'], con=engine)
print(df)
except Exception as e:
print(e)
# Execution failed on sql 'SELECT AVG(CAST(SUBSTR(WT, INSTR(WT,'') + 1) AS INTEGER) FROM nba_roster WHERE WT IS NOT NULL': near "FROM": syntax error
# TRYING AGENT REFLECTION
reflection = f"Question: {question}. Query: {generated_query['sqlite_query']}. This query is invalid (gets the error Execution failed on sql 'SELECT AVG(CAST(SUBSTR(WT, INSTR(WT,'') + 1) AS INTEGER) FROM nba_roster WHERE WT IS NOT NULL': near \"FROM\": syntax error), so it cannot answer the question. Write a corrected sqlite query."
reflection_prompt = make_llama_3_prompt(reflection, system)
print(reflection_prompt)
"""
'<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:\n0|Team|TEXT eg. "Toronto Raptors"\n1|NAME|TEXT eg. "Otto Porter Jr."\n2|Jersey|TEXT eg. "0" and when null has a value "NA"\n3|POS|TEXT eg. "PF"\n4|AGE|INT eg. "22" in years\n5|HT|TEXT eg. `6\' 7"` or `6\' 10"`\n6|WT|TEXT eg. "232 lbs" \n7|COLLEGE|TEXT eg. "Michigan" and when null has a value "--"\n8|SALARY|TEXT eg. "$9,945,830" and when null has a value "--"\n\n\nWrite a sqlite query to answer the following question. Follow instructions exactly<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nQuestion: What is the median weight in the NBA?. Query: SELECT AVG(CAST(SUBSTR(WT, INSTR(WT,\'\') + 1) AS INTEGER) FROM nba_roster WHERE WT IS NOT NULL. This query is invalid (gets the error Execution failed on sql \'SELECT AVG(CAST(SUBSTR(WT, INSTR(WT,\'\') + 1) AS INTEGER) FROM nba_roster WHERE WT IS NOT NULL\': near "FROM": syntax error), so it cannot answer the question. Write a corrected sqlite query.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n'
"""
reflection_query = llm.generate(reflection_prompt, output_type={"sqlite_query": "str"}, max_new_tokens=200)
print(reflection_query)
"""
{'sqlite_query': "SELECT AVG(CAST(SUBSTR(WT, INSTR(WT,'') + 1) AS INTEGER) FROM nba_roster WHERE WT IS NOT NULL"}
"""
try:
df = pd.read_sql(reflection_query['sqlite_query'], con=engine)
print(df)
except Exception as e:
print(e)
"""
Execution failed on sql 'SELECT AVG(CAST(SUBSTR(WT, INSTR(WT,'') + 1) AS INTEGER) FROM nba_roster WHERE WT IS NOT NULL': near "FROM": syntax error
"""
correct_sql = "select CAST(SUBSTR(WT, 1, INSTR(WT,' ')) as INTEGER) as percentile from nba_roster order by percentile limit 1 offset (select count(*) from nba_roster)/2;"
df_corrected = pd.read_sql(correct_sql, con=engine)
print(df_corrected)
"""
percentile
0 215
"""
# EVALUATE OVER A LARGE DATASET
import logging
import os
from datetime import datetime
from pprint import pprint
from typing import AsyncIterator, Iterator, Union
import sqlite3
from tqdm import tqdm
import pandas as pd
import jsonlines
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_node import GenerationNode
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_pipeline import GenerationPipeline
from util.get_schema import get_schema
from util.make_llama_3_prompt import make_llama_3_prompt
from util.setup_logging import setup_logging
logger = logging.getLogger(__name__)
engine = sqlite3.connect("./nba_roster.db")
setup_logging()
class Args:
def __init__(self,
max_examples=100,
sql_model_name="meta-llama/Meta-Llama-3-8B-Instruct",
gold_file_name="gold-test-set.jsonl",
training_file_name="archive/generated_queries.jsonl",
num_to_generate=10):
self.sql_model_name = sql_model_name
self.max_examples = max_examples
self.gold_file_name = gold_file_name
self.training_file_name = training_file_name
self.num_to_generate = num_to_generate
def load_gold_dataset(args):
path = f"data/{args.gold_file_name}"
with jsonlines.open(path) as reader:
for index, obj in enumerate(reversed(list(reader))):
if index >= args.max_examples:
break
yield PromptObject(prompt="", data=obj)
path = "data/gold-test-set.jsonl"
with jsonlines.open(path) as reader:
data = [obj for obj in reader]
datapoint = data[4]
print(datapoint)
"""
{'question': 'What is the average weight in the NBA?',
'answer': '214.98',
'sql': "SELECT AVG(CAST(SUBSTR(WT, 1, INSTR(WT,' ')) as INTEGER)) FROM nba_roster;"}
"""
datapoint = data[7]
print(datapoint)
"""
{'question': 'Can you tell me how many players are in the NBA?',
'answer': '600',
'sql': 'select count(*) from nba_roster;'}
"""
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question:\n"
)
user = datapoint["question"]
prompt = make_llama_3_prompt(user, system)
generated_sql = llm.generate(prompt, output_type={"sqlite_query": "str"}, max_new_tokens=200)
print(generated_sql)
df = pd.read_sql(generated_sql['sqlite_query'], con=engine)
print(df)
"""
COUNT(*)
0 476
"""
query_succeeded = False
try:
df = pd.read_sql(generated_sql['sqlite_query'], con=engine)
query_succeeded = True
print("Query is valid")
except Exception as e:
print(
f"Failed to run SQL query: {generated_sql}"
)
reference_sql = datapoint["sql"]
ref_df = pd.read_sql(reference_sql, con=engine)
print(ref_df)
""""
count(*)
0 600
"""
# Let's transform it to our codes to a class
class QueryStage(GenerationNode):
def __init__(self, model_name):
super().__init__(
model_name=model_name,
max_new_tokens=200,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"sqlite_query": "str"},
*args,
**kwargs,
)
return results
def postprocess(self, obj: PromptObject):
# Run both the generated and reference (Gold Dataset) SQL queries
# Assessing whether the SQL queries succeeded in hitting the database (not correctness yet!)
query_succeeded = False
try:
logger.error(f"Running SQL query '{obj.response['sqlite_query']}'")
obj.data["generated_query"] = obj.response["sqlite_query"]
df = pd.read_sql(obj.response["sqlite_query"], con=engine)
obj.data['df'] = df
logger.error(f"Got data: {df}")
query_succeeded = True
except Exception as e:
logger.error(
f"Failed to run SQL query: {obj.response['sqlite_query']}"
)
logger.info(f"Running reference SQL query '{obj.data['sql']}'")
df = pd.read_sql(obj.data["sql"], con=engine)
logger.info(f"Got data: {df}")
obj.data['reference_df'] = df
logger.info(f"For question: {obj.data['question']}")
logger.info(f"For query: {obj.response['sqlite_query']}")
obj.data["query_succeeded"] = query_succeeded
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_prompt(obj.data))
obj.prompt = new_prompt
def make_prompt(self, data: dict):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question:\n"
)
user = data["question"]
return {
"user": user,
"system": system,
}
# Compare strings
str(df).lower() == str(ref_df).lower() # False
# Using a LLM to compare
system_prompt = "Compare the following two dataframes. They are similar if they are almost identical, or if they convey the same information about the nba_roster dataset"
system_prompt += "Respond with valid JSON {'explanation' : str, 'similar' : bool}"
print(system_prompt)
"""
"Compare the following two dataframes.
They are similar if they are almost identical, or if they convey the same information about the nba_roster datasetRespond with valid JSON {'explanation' : str, 'similar' : bool}"
"""
user_prompt = (
f"========== Dataframe 1 =========\n{str(df).lower()}\n\n"
)
user_prompt += (
f"========== Dataframe 2 =========\n{str(ref_df).lower()}\n\n"
)
user_prompt += f"Can you tell me if these dataframes are similar?"
llm_similarity_prompt = make_llama_3_prompt(user_prompt, system_prompt)
llm_similarity = llm.generate(llm_similarity_prompt, output_type={"explanation": "str", "similar": "bool"}, max_new_tokens=200)
print(llm_similarity)
"""
{'explanation': 'The dataframes are not similar because they have different counts. The first dataframe has a count of 476, while the second dataframe has a count of 600',
'similar': False}
"""
str(df).lower() == str(ref_df).lower() or llm_similarity["similar"] # False
# How to wrap it up in a class
class ScoreStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=150,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
logger.debug("ScoreStage Generate")
results = super().generate(
prompt,
output_type={"explanation": "str", "similar": ["true", "false"]},
*args,
**kwargs,
)
logger.debug(f"ScoreStage Results {results}")
return results
def preprocess(self, obj: PromptObject):
obj.prompt = make_llama_3_prompt(**self.make_prompt(obj))
logger.info(f"Scoring Stage Prompt:\n{obj.prompt}")
def postprocess(self, obj: PromptObject):
logger.info(f"Postprocess")
obj.data['is_matching'] = self.is_matching(obj.data, obj.response)
obj.data['explanation'] = obj.response["explanation"]
obj.data['similar'] = obj.response["similar"] == "true"
def is_matching(self, data, response):
return (str(data.get('df',"None")).lower() == str(data['reference_df']).lower()
or response['similar'] == "true")
def make_prompt(self, obj: PromptObject):
# Your evaluation model compares SQL output from the generated and reference SQL queries, using another LLM in the pipeline
system_prompt = "Compare the following two dataframes. They are similar if they are almost identical, or if they convey the same information about the nba_roster dataset"
system_prompt += "Respond with valid JSON {'explanation' : str, 'similar' : bool}"
user_prompt = (
f"========== Dataframe 1 =========\n{str(obj.data.get('df','None')).lower()}\n\n"
)
user_prompt += (
f"========== Dataframe 2 =========\n{str(obj.data['reference_df']).lower()}\n\n"
)
user_prompt += f"Can you tell me if these dataframes are similar?"
return {
"system": system_prompt,
"user": user_prompt
}
class EvaluationPipeline(GenerationPipeline):
def __init__(self, args):
super().__init__()
self.query_stage = QueryStage(args.sql_model_name)
self.score_stage = ScoreStage()
def forward(self, x):
x = self.query_stage(x)
x = self.score_stage(x)
return x
async def run_eval(dataset, args):
results = await run_evaluation_pipeline(dataset, args)
print("Total results:", len(results))
return results
async def run_evaluation_pipeline(dataset, args):
results = EvaluationPipeline(args).call(dataset)
result_list = []
pbar = tqdm(desc="Saving results", unit=" results")
async for result in results:
result_list.append(result)
pbar.update()
return result_list
def save_eval_results(results, args):
base_path = "./data/results"
now = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
experiment_name = f"nba_sql_pipeline_{now}"
experiment_dir = os.path.join(base_path, experiment_name)
os.makedirs(os.path.join(base_path, experiment_name))
# Write args to file
args_file_name = f"{experiment_dir}/args.txt"
with open(args_file_name, "w") as writer:
pprint(args.__dict__, writer)
def is_correct(r):
if (
(r.data["query_succeeded"] and r.data['is_matching']) or
r.data["generated_query"] == r.data['sql']
):
return True
return False
# Write sql results and errors to file
results_file_name = f"{experiment_dir}/sql_results.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if not is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"reference_sql": result.data['sql'],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
results_file_name = f"{experiment_dir}/sql_errors.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
# Write statistics to file
average_sql_succeeded = sum(
[result.data["query_succeeded"] for result in results]
) / len(results)
average_correct = sum(
[result.data["query_succeeded"] and result.data['is_matching'] for result in results]
) / len(results)
file_name = f"{experiment_dir}/summary.txt"
with open(file_name, "w") as writer:
print(f"Total size of eval dataset: {len(results)}", file=writer)
print(f"Total size of eval dataset: {len(results)}")
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}", file=writer)
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}")
print(f"Percent Correct SQL Query: {average_correct*100}", file=writer)
print(f"Percent Correct SQL Query: {average_correct*100}")
args = Args()
dataset = load_gold_dataset(args)
results = await run_eval(dataset, args)
save_eval_results(results, args)Finetuning, PEFT & Memory Tuning
Let's learn how to fine-tune PEFT and remove hallucinations using memory tuning. We fine-tune to match more data, learn from data, have greater control over LLM, and there is no accuracy ceiling. We will look at two sorts of finetuning: instruction finetuning and memory tuning.
* Instruction finetuning is when a pre-trained LLM follows instructions.
* Memory tuning is the process of getting an LLM to stop hallucinating.
Instruction fine-tuning can be utilized to obtain the chatting feature, the calling feature, and the output format.
Pre-training is the process of teaching an LLM huge data one token at a time, similar to autocomplete. It minimizes average error over examples (generalization error), and it produces powerful foundation models that learn quickly. However, LLM is unable to follow directions and experiences hallucinations based on facts.
Because of their probabilistic character, LLMs believe that being somewhat right and right are synonymous. Memory Tuning, on the other hand, decreases inaccuracy to zero on facts while improving performance in all other areas.
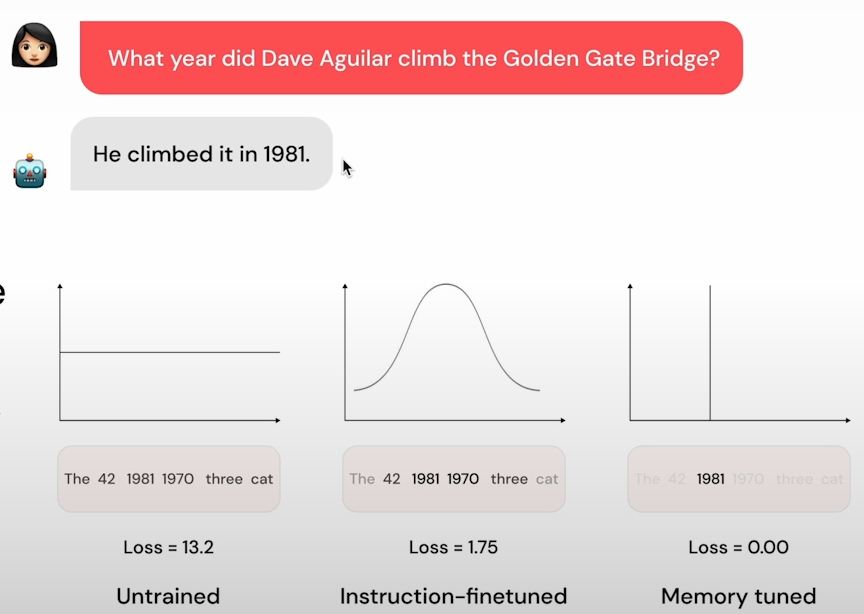
Don't forget that prompting and rag can remedy any problem, and fine-tuning is no longer prohibitively expensive. Finetuning is less expensive than running large prompts in RAG, PEFT lowered costs by 10,000 times, and MoME (Mixture of Memory Experts) converts any LLM into a million-way mixture of expert adapters, decreasing time by 240 times. However, in order to achieve efficiency benefits, fine-tuning must be properly implemented.
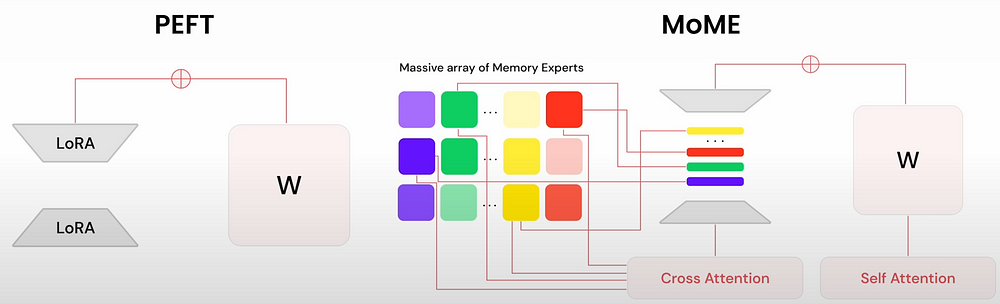
One of the most widely used PEFT approaches is LoRA (Low-Rank Adaptation). In LoRA, we train an adaptor that operates with weights. By doing so, we avoid touching the main weights and may fuze it back to the main model, resulting in the same amount of latency in the inference.
In MoME, you also have adapters, but you also have an array of memory expert weights that you are tuning and sampling in a reasonable stage where you do have those adapters and you are sampling a subset of them that contain this understanding of facts that you have learned from your data and fuzing those into the adapters themselves. So you can develop your model using memory experts in such a way that you obtain the intelligence of a large model at the cost and latency of a smaller (sparsely activated) model.
While completely managed fine-tuning is available, it is difficult to implement on your own.
* Efficiency: It is inefficient. It takes more computing to achieve the same accuracy, which is 10k-1M times tougher. Cannot efficiently parallelize across many GPUs. Crash on a real-world use case; cannot continually fine-tune and infer jointly in production. LLM does not improve, and it is difficult to tune for each use case, model, and dataset.
* Inference: The GPU and memory issues make it difficult to use and scale.
* Bugs: There are numerous flaws in combining finetuning with inference techniques. Model weights cannot be transferred between formats without encountering bugs.
* Using the incorrect tools: Instruction fine-tuning does not eliminate hallucinations.
On free platforms like as Lamini, you can run PEFT instruction and memory tweaking with a one-line call.
When fine-tuning focus on the specifics of your use case like more and better data, and evaluation.
Generate Data & Finetune
You frequently have more info than you realize. The issue with the data is that it is often not in the proper format. It used to be difficult to label data manually, but with the help of LLMs, it is no longer an issue as long as you supply the correct format. Choosing the appropriate format is highly application-specific. For example, prompt to a SQL query, id, or answer.
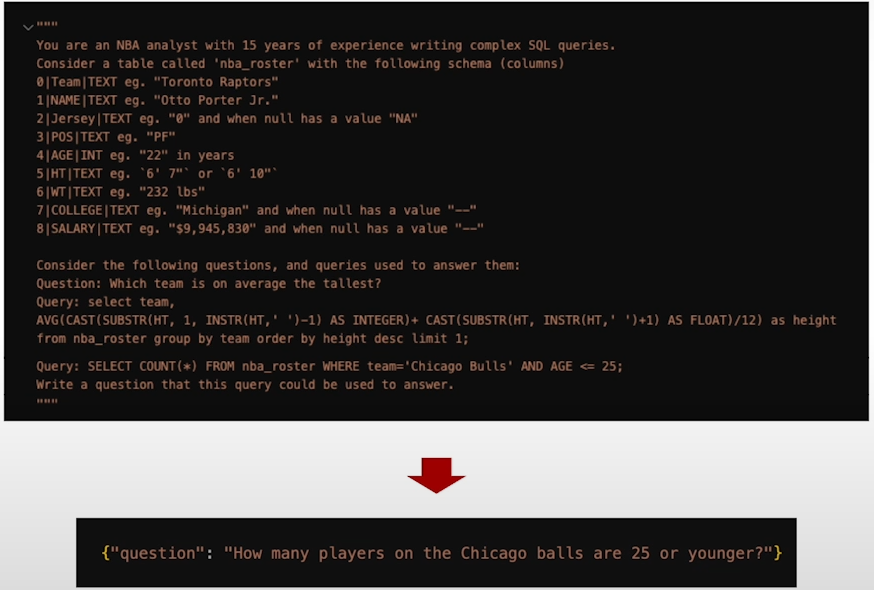
Practical Tips
- Add examples of few-shot or in-context learning. Especially rectified hallucinating examples that are related to what the LLM needs to know.
Create variations: This helps you get breadth. Instead of limiting it to NBA players, you can experiment with different identities to add generations.
Filter Generations: It is critical to be able to filter and rely on your filters, automatic filters, and simply downsample your created instances to provide a higher quality dataset. This delivers high-quality data in a scalable manner.
It's important to look at what did and didn't work: Usually, more sophisticated queries are more difficult. This allows you to adjust prompts, including all of the aforementioned advice.
Minimum requirements to submit the data for fine-tuning:
- Memory Tuning: 1 data point. 1000 data points are used to fine-tune the instructions. Fine-tuning requires pairs of prompt-response pairs. Memory tweaking requires the facts you want the LLM to learn in the responses. Ease of fine-tuning: Using a library like Lamini requires only a single API/Python call. Alternatively, create your own and hyperparameter tweak the model forwards/backwards, etc.
Before starting to finetune we need to calculate the time and compute requirements.
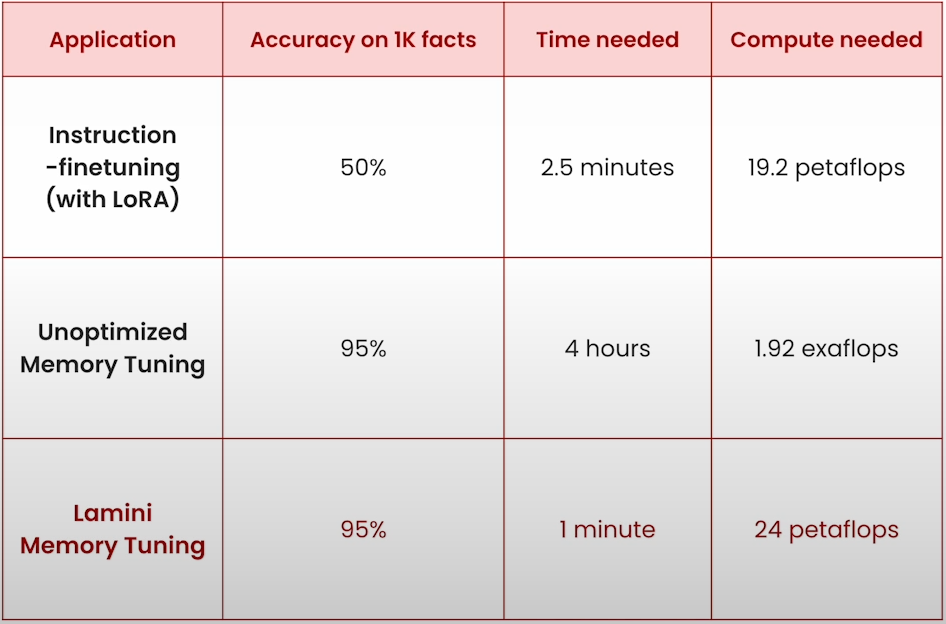
Instruction finetuning, specifically with LoRA, achieves an accuracy of approximately 50%, but it is extremely quick, taking only a few minutes and requiring only 19.2 petaflops. This benchmark is based on a single NVIDIA A100 GPU with 40% MFU performance, or an equivalent AMD GPU in the mid to high 50s. Memory tuning is much more intensive when using the unoptimized version; this is still utilizing LoRA, but it is unoptimized, and the accuracy on a thousand facts can increase significantly because the entire objective is to eliminate hallucinations. But the reason why it takes so much longer and so much more compute is that there are 1.9 to exa flops in the second row and 4 hours is because you are bringing the loss to zero on the specific facts. Lamini Memory Tuning has applied optimizations you saw previously and the time needed is only a minute and 24 petaflops.
What To Expect:
* Finetuning is an iterative experimental process. It requires 10-30 iterations across many data pipelines to achieve 95% accuracy.
* Fine-tuning numerous versions in tandem accelerates exploration.
* You can start talking about 90+ accuracy.
* Things that can improve your accuracy:
- If you have all of the facts, you have enough information. Use LLMs to handle the remainder. To obtain the desired data, you can pipe it through an LLM. Your LLM data pipelines can become rather complex and specific to your aims, data, and difficulties (if you are an AI startup, this can yield something unique).
- * Excel at detecting LLM errors and hallucinations to teach your LLM what correct looks like.
- Fastest-build applications are where data evaluators are sitting next to the application builders.
from dotenv import load_dotenv
_ = load_dotenv() #load environmental variable LAMINI_API_KEY with key from .env file
import lamini
import logging
import random
from typing import AsyncIterator, Iterator, Union
import sqlite3
import copy
from tqdm import tqdm
import pandas as pd
import jsonlines
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_node import GenerationNode
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_pipeline import GenerationPipeline
from util.get_schema import get_schema, get_schema_s
from util.make_llama_3_prompt import make_llama_3_prompt
from util.setup_logging import setup_logging
logger = logging.getLogger(__name__)
engine = sqlite3.connect("./nba_roster.db")
setup_logging()
class Args:
def __init__(self,
max_examples=100,
sql_model_name="meta-llama/Meta-Llama-3-8B-Instruct",
gold_file_name="gold-test-set.jsonl",
training_file_name="generated_queries.jsonl",
num_to_generate=10):
self.sql_model_name = sql_model_name
self.max_examples = max_examples
self.gold_file_name = gold_file_name
self.training_file_name = training_file_name
self.num_to_generate = num_to_generateWorking Backwards From What You Have
- From Scheme and example generate new SQL queries:
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema_s()
system += "Consider the following questions, and queries used to answer them:\n"
print(system)
question = """What is the median weight in the NBA?"""
sql = "select CAST(SUBSTR(WT, 1, INSTR(WT,' ')) as INTEGER) as percentile from nba_roster order by percentile limit 1 offset (select count(*) from nba_roster)/2;"
system += "Question: " + question + "\n"
system += "Query: " + sql + "\n"
print(system)
user = "Write two queries that are similar but different to those above.\n"
user += "Format the queries as a JSON object, i.e.\n"
user += '{ "explanation": str, "sql_query_1" : str, "sql_query_2": str }.\n'
print(user)
user += "First write an explanation of why you decided to write these new queries in about 3-5 sentences, then write valid sqlite SQL queries for each of the 2 new queries. Make sure each query is complete and ends with a ;\n"
print(user)
prompt = make_llama_3_prompt(user, system)
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
result = llm.generate(prompt, output_type={ "explanation": "str", "sql_query_1" : "str", "sql_query_2": "str" }, max_new_tokens=200)
print(result)
def check_sql_query(query):
try:
pd.read_sql(query, con=engine)
except Exception as e:
logger.debug(f"Error in SQL query: {e}")
return False
logger.info(f"SQL query {query} is valid")
return True
check_sql_query(result["sql_query_1"])
check_sql_query(result["sql_query_2"])
# Hepsini tek bir sınıf içerisine koyalım
class ModelStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=300,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
prompt = self.add_template(prompt)
results = super().generate(
prompt,
output_type={
"explanation": "str",
"sql_query_1": "str",
"sql_query_2": "str",
},
*args,
**kwargs,
)
return results
async def add_template(self, prompts):
async for prompt in prompts:
new_prompt = make_llama_3_prompt(**self.make_prompt(prompt.data))
yield PromptObject(prompt=new_prompt, data=prompt.data)
async def process_results(self, results):
async for result in results:
if result is None:
continue
if result.response is None:
continue
logger.info("=====================================")
logger.info(f"Generated query 1: {result.response['sql_query_1']}")
logger.info(f"Generated query 2: {result.response['sql_query_2']}")
logger.info("=====================================")
if self.check_sql_query(result.response["sql_query_1"]):
new_result = PromptObject(prompt="", data=copy.deepcopy(result.data))
new_result.data.generated_sql_query = result.response["sql_query_1"]
yield new_result
if self.check_sql_query(result.response["sql_query_2"]):
new_result = PromptObject(prompt="", data=copy.deepcopy(result.data))
new_result.data.generated_sql_query = result.response["sql_query_2"]
yield new_result
def make_prompt(self, data):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema()
system += "Consider the following questions, and queries used to answer them:\n"
for example in data.sample:
system += "Question: " + example["question"] + "\n"
system += "Query: " + example["sql"] + "\n"
# Important: generate relevant queries to your reference data
# Ideally, close to those that are failing so you can show the model examples of how to do it right!
user = "Write two queries that are similar but different to those above.\n"
user += "Format the queries as a JSON object, i.e.\n"
user += '{ "explanation": str, "sql_query_1" : str, "sql_query_2": str }.\n'
# Next, use Chain of Thought (CoT) and prompt-engineering to help with generating SQL queries
user += "First write an explanation of why you decided to write these new queries in about 3-5 sentences, then write valid sqlite SQL queries for each of the 2 new queries. Make sure each query is complete and ends with a ;\n"
return {"system": system, "user": user}
def check_sql_query(self, query):
try:
pd.read_sql(query, con=engine)
except Exception as e:
logger.debug(f"Error in SQL query: {e}")
return False
logger.info(f"SQL query {query} is valid")
return True2. Now that you have queries, generate questions for those queries:
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema() + "\n"
system += "Queries, and questions that they are used to answer:\n"
example_question = """What is the median weight in the NBA?"""
example_sql = "select CAST(SUBSTR(WT, 1, INSTR(WT,' ')) as INTEGER) as percentile from nba_roster order by percentile limit 1 offset (select count(*) from nba_roster)/2;"
system += "Question: " + example_question + "\n"
system += "Query: " + example_sql + "\n"
generated_sql = result["sql_query_2"]
user = "Now consider the following query.\n"
user += "Query: " + generated_sql + "\n"
user += "Write a question that this query could be used to answer.\n"
user += "Format your response as a JSON object, i.e.\n"
user += '{ "explanation": str, "question": str }.\n'
user += "First write an explanation in about 3-5 sentences, then write a one sentence question.\n"
prompt = make_llama_3_prompt(user, system)
result = llm.generate(prompt, output_type={ "explanation": "str", "question" : "str" }, max_new_tokens=200)
print(result)
# Wrap it all up together in a class which generates a question
# given a query
class QuestionStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=150,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={
"explanation": "str",
"question": "str",
},
*args,
**kwargs,
)
return results
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_question_prompt(obj.data))
obj.prompt = new_prompt
def make_question_prompt(self, data):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema() + "\n"
system += "Queries, and questions that they are used to answer:\n"
for example in data.sample:
system += "Query: " + example["sql"] + "\n"
system += "Question: " + example["question"] + "\n"
user = "Now consider the following query.\n"
user += "Query: " + data.generated_sql_query + "\n"
user += "Write a question that this query could be used to answer.\n"
# Using Chain of Thought (CoT) again
# This time you can do it programmatically with function calling, so you can easily extract a question out of the JSON object
user += "Format your response as a JSON object, i.e.\n"
user += '{ "explanation": str, "question": str }.\n'
user += "First write an explanation in about 3-5 sentences, then write a one sentence question.\n"
return {"system": system, "user": user}
class QueryGenPipeline(GenerationPipeline):
def __init__(self):
super().__init__()
self.model_stage = ModelStage()
self.question_stage = QuestionStage()
def forward(self, x):
x = self.model_stage(x)
x = self.question_stage(x)
return x
async def run_query_gen_pipeline(gold_queries):
return QueryGenPipeline().call(gold_queries)
# Generate N samples, for every example in the gold dataset
all_examples = []
async def load_gold_queries(args):
path = f"data/{args.gold_file_name}"
with jsonlines.open(path) as reader:
global all_examples
all_examples = [obj for obj in reader]
sample_count = args.num_to_generate
sample_size = 3
random.seed(42)
for i in range(sample_count):
example_sample = ExampleSample(random.sample(all_examples, sample_size), i)
yield PromptObject(prompt="", data=example_sample)
class ExampleSample:
def __init__(self, sample, index):
self.sample = sample
self.index = index
async def save_generation_results(results, args):
path = f"data/training_data/{args.training_file_name}"
pbar = tqdm(desc="Saving results", unit=" results")
with jsonlines.open(path, "w") as writer:
async for result in results:
writer.write(
{
"question": result.response["question"],
"sql": result.data.generated_sql_query,
}
)
pbar.update()
for example in all_examples:
writer.write(example)
pbar.update()
args = Args()
gold_queries = load_gold_queries(args)
results = await run_query_gen_pipeline(gold_queries)
await save_generation_results(results, args)
# Display the queries generated above
#!cat "data/training_data/generated_queries.jsonl"
# Display the archived queries which match the course video
!cat "data/training_data/archive/generated_queries.jsonl"
# ROUND OF FINETUNING
# Now that you have data, even if it is not perfect, go through a round of finetuning!
import logging
import os
from datetime import datetime
from pprint import pprint
from typing import AsyncIterator, Iterator, Union
import sqlite3
from tqdm import tqdm
import pandas as pd
import jsonlines
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_node import GenerationNode
from lamini.generation.base_prompt_object import PromptObject
from lamini.generation.generation_pipeline import GenerationPipeline
from util.get_schema import get_schema
from util.make_llama_3_prompt import make_llama_3_prompt
from util.setup_logging import setup_logging
from util.load_dataset import get_dataset
from util.get_default_finetune_args import get_default_finetune_args
logger = logging.getLogger(__name__)
engine = sqlite3.connect("./nba_roster.db")
setup_logging()
class Args:
def __init__(self,
max_examples=100,
sql_model_name="meta-llama/Meta-Llama-3-8B-Instruct",
gold_file_name="gold-test-set.jsonl",
training_file_name="archive/generated_queries.jsonl",
num_to_generate=10):
self.sql_model_name = sql_model_name
self.max_examples = max_examples
self.gold_file_name = gold_file_name
self.training_file_name = training_file_name
self.num_to_generate = num_to_generate
# make_question will take the questions and queries from the training_file and embed them in the prompt below to form the training data.
def make_question(obj):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question:\n"
)
user = obj["question"]
return {"system": system, "user": user}
args = Args()
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
dataset = get_dataset(args, make_question)
finetune_args = get_default_finetune_args()
"""
This fine tuning step takes about 30 mintues to complete. The dispatch to run on the lamini services is commented out and the pre-computed final results of the run are provided below. You can uncomment and run if you have modified data on your own.
"""
llm.train(
data_or_dataset_id=dataset,
finetune_args=finetune_args,
is_public=True, # For sharing
)
# Let's examine this pre-computed finetuning result
llm = lamini.Lamini(model_name="a5ebf1c4879569101f32444afae5adcafbfce9c5a6ed13035fd892147f7d59bc")
question = """Who is the highest paid NBA player?"""
system = f"""You are an NBA analyst with 15 years of experience writing complex SQL queries. Consider the nba_roster table with the following schema:
{get_schema()}
Write a sqlite query to answer the following question. Follow instructions exactly"""
prompt = make_llama_3_prompt(question, system)
print("Question:\n", question)
print("Answer:")
print(llm.generate(prompt, max_new_tokens=200))
query="SELECT salary, name FROM nba_roster WHERE salary != '--' ORDER BY CAST(REPLACE(REPLACE(salary, '$', ''), ',','') AS INTEGER) DESC LIMIT 1;"
df = pd.read_sql(query, con=engine)
print(df)
# Let's run an evaluation over the eval dataset.
# Collapsible or utils from Lesson 3 Lab for evaluation
class QueryStage(GenerationNode):
def __init__(self, model_name):
super().__init__(
model_name=model_name,
max_new_tokens=300,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"sqlite_query": "str"},
*args,
**kwargs,
)
return results
def postprocess(self, obj: PromptObject):
# Run both the generated and reference (Gold Dataset) SQL queries
# Assessing whether the SQL queries succeeded in hitting the database (not correctness yet!)
query_succeeded = False
try:
logger.info(f"Running SQL query '{obj.response['sqlite_query']}'")
obj.data["generated_query"] = obj.response["sqlite_query"]
df = pd.read_sql(obj.response["sqlite_query"], con=engine)
obj.data['df'] = df
logger.info(f"Got data: {df}")
query_succeeded = True
except Exception as e:
logger.error(
f"Failed to run SQL query: {obj.response['sqlite_query']}"
)
logger.info(f"Running reference SQL query '{obj.data['sql']}'")
df = pd.read_sql(obj.data["sql"], con=engine)
logger.info(f"Got data: {df}")
obj.data['reference_df'] = df
logger.info(f"For question: {obj.data['question']}")
logger.info(f"For query: {obj.response['sqlite_query']}")
obj.data["query_succeeded"] = query_succeeded
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_prompt(obj.data))
obj.prompt = new_prompt
def make_prompt(self, data: dict):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question. Make sure each query ends with a semicolon:\n"
)
user = data["question"]
return {
"user": user,
"system": system,
}
class ScoreStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_new_tokens=150,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"explanation": "str", "similar": ["true", "false"]},
*args,
**kwargs,
)
return results
def preprocess(self, obj: PromptObject):
obj.prompt = make_llama_3_prompt(**self.make_prompt(obj))
logger.info(f"Scoring Stage Prompt:\n{obj.prompt}")
def postprocess(self, obj: PromptObject):
obj.data['is_matching'] = self.is_matching(obj.data, obj.response)
obj.data['explanation'] = obj.response["explanation"]
obj.data['similar'] = obj.response["similar"] == "true"
def is_matching(self, data, response):
return (str(data.get('df',"None")).lower() == str(data['reference_df']).lower()
or response['similar'] == "true")
def make_prompt(self, obj: PromptObject):
# Your evaluation model compares SQL output from the generated and reference SQL queries, using another LLM in the pipeline
'''
Note:
Prompt tuning is important!
A previous iteration of this scoring pipeline said `Compare the following two dataframes to see if they are identical`.
That prompt turned out to be too stringent of criteria.
'''
system_prompt = "Compare the following two dataframes. They are similar if they are almost identical, or if they convey the same information about the nba_roster dataset"
system_prompt += "Respond with valid JSON {'explanation' : str, 'similar' : bool}"
user_prompt = (
f"========== Dataframe 1 =========\n{str(obj.data.get('df','None')).lower()}\n\n"
)
user_prompt += (
f"========== Dataframe 2 =========\n{str(obj.data['reference_df']).lower()}\n\n"
)
user_prompt += f"Can you tell me if these dataframes are similar?"
return {
"system": system_prompt,
"user": user_prompt
}
async def run_eval(dataset, args):
results = await run_evaluation_pipeline(dataset, args)
print("Total results:", len(results))
return results
async def run_evaluation_pipeline(dataset, args):
results = EvaluationPipeline(args).call(dataset)
result_list = []
pbar = tqdm(desc="Saving results", unit=" results")
async for result in results:
result_list.append(result)
pbar.update()
return result_list
class EvaluationPipeline(GenerationPipeline):
def __init__(self, args):
super().__init__()
self.query_stage = QueryStage(args.sql_model_name)
self.score_stage = ScoreStage()
def forward(self, x):
x = self.query_stage(x)
x = self.score_stage(x)
return x
def load_gold_dataset(args):
path = f"data/{args.gold_file_name}"
with jsonlines.open(path) as reader:
for index, obj in enumerate(reversed(list(reader))):
if index >= args.max_examples:
break
yield PromptObject(prompt="", data=obj)
def save_eval_results(results, args):
base_path = "./data/results"
now = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
experiment_name = f"nba_sql_pipeline_{now}"
experiment_dir = os.path.join(base_path, experiment_name)
os.makedirs(os.path.join(base_path, experiment_name))
# Write args to file
args_file_name = f"{experiment_dir}/args.txt"
with open(args_file_name, "w") as writer:
pprint(args.__dict__, writer)
def is_correct(r):
if (
(result.data["query_succeeded"] and result.data['is_matching']) or
result.data["generated_query"] == result.data['sql']
):
return True
return False
# Write sql results and errors to file
results_file_name = f"{experiment_dir}/sql_results.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if not is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"reference_sql": result.data['sql'],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
results_file_name = f"{experiment_dir}/sql_errors.jsonl"
with jsonlines.open(results_file_name, "w") as writer:
for result in results:
if is_correct(result):
continue
writer.write(
{
"question": result.data['question'],
"query": result.data["generated_query"],
"query_succeeded": result.data["query_succeeded"],
"df": str(result.data.get('df', 'None')),
"reference_df": str(result.data['reference_df']),
'is_matching': result.data['is_matching'],
'similar': result.data['similar'],
}
)
# Write statistics to file
average_sql_succeeded = sum(
[result.data["query_succeeded"] for result in results]
) / len(results)
average_correct = sum(
[result.data["query_succeeded"] and result.data['is_matching'] for result in results]
) / len(results)
file_name = f"{experiment_dir}/summary.txt"
with open(file_name, "w") as writer:
print(f"Total size of eval dataset: {len(results)}", file=writer)
print(f"Total size of eval dataset: {len(results)}")
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}", file=writer)
print(f"Percent Valid SQL Syntax: {average_sql_succeeded*100}")
print(f"Percent Correct SQL Query: {average_correct*100}", file=writer)
print(f"Percent Correct SQL Query: {average_correct*100}")
# Run the evaluation and you can see there is more valid SQL and correct queries.
args = Args(sql_model_name="a5ebf1c4879569101f32444afae5adcafbfce9c5a6ed13035fd892147f7d59bc")
dataset = load_gold_dataset(args)
results = await run_eval(dataset, args)
save_eval_results(results, args)
# Filtering the dataset
# Next step is filtering, manually create functions to filter the test set.
question_set = set()
sql_set = set()
def is_not_valid_sql(question, sql):
try:
df = pd.read_sql(sql, con=engine)
return False
except Exception as e:
return True
def has_null_in_sql_or_question(question, sql):
return "null" in sql.lower() or "null" in question
def returns_empty_dataframe(question, sql):
try:
df = pd.read_sql(sql, con=engine)
return "Empty" in str(df) or "None" in str(df)
except Exception as e:
return False
def uses_avg_on_ht_column(question, sql):
return "avg(ht)" in sql.lower() or "avg(salary" in sql.lower()
filter_conditions = [is_not_valid_sql, has_null_in_sql_or_question, returns_empty_dataframe, uses_avg_on_ht_column]
def training_semicolon(sql):
if sql.strip()[-1] != ";":
return sql.strip() + ";"
return sql
with jsonlines.open("data/training_data/archive/generated_queries_large.jsonl", "r") as reader:
with jsonlines.open("data/training_data/generated_queries_large_filtered.jsonl", "w") as writer:
for r in reader:
if r["question"] in question_set or r["sql"] in sql_set:
continue
question_set.add(r["question"])
sql_set.add(r["sql"])
if any(c(r['question'], r['sql']) for c in filter_conditions):
continue
sql = training_semicolon(r['sql'])
writer.write(
{
"question": r["question"],
"sql": sql,
}
)
Resources
Deeplearning.ai, (2024), Improving Accuracy of LLM Applications:
[https://learn.deeplearning.ai/courses/improving-accuracy-of-llm-applications/]










0 Comments