
https://cbarkinozer.medium.com/llmler-makaleler-hakk%C4%B1nda-yararl%C4%B1-geri-bildirim-sa%C4%9Flayabilir-mi-303351e58078
“Can large language models provide useful feedback on research papers? “A large-scale empirical analysis.” Summary of the article.
Abstract
Feedback from experts forms the basis of rigorous research. However, the rapid growth of scientific production and the mastering of complex knowledge challenges traditional scientific feedback mechanisms. High-quality peer reviews are becoming increasingly difficult to obtain. Researchers who are more junior or come from under-resourced settings have a particularly difficult time receiving timely feedback.
With the emergence of large language models (LLMs) such as GPT-4, there is growing interest in using LLMs to generate scholarly feedback on research papers. However, the utility of LLM-generated feedback has not been systematically investigated. To address this gap, we created an automated pipeline using GPT-4 to comment on full PDFs of scientific articles.
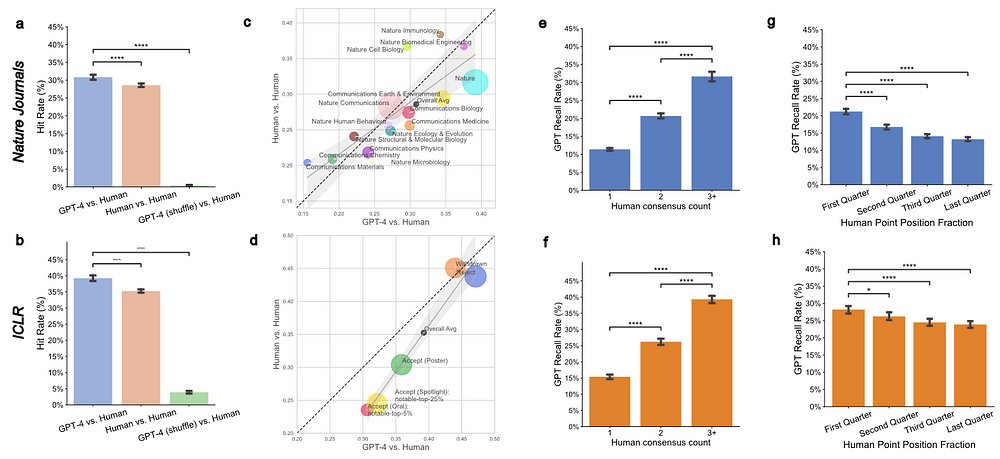
We evaluated the quality of GPT-4's feedback through two large-scale studies. We first quantitatively compared GPT-4-generated feedback to feedback from human peer reviewers at 15 Nature family journals (3,096 papers in total) and the ICLR machine learning conference (1,709 papers). The overlap in points raised by GPT-4 and human reviewers (average overlap of 30.85% for Nature journals, 39.23% for ICLR) is comparable to the overlap between two human reviewers (average overlap of 28.58% for Nature journals, 35% for ICLR ,25) ). The overlap between GPT-4 and human reviewers is greater for weaker articles (i.e., rejected ICLR articles; average overlap is 43.80%).
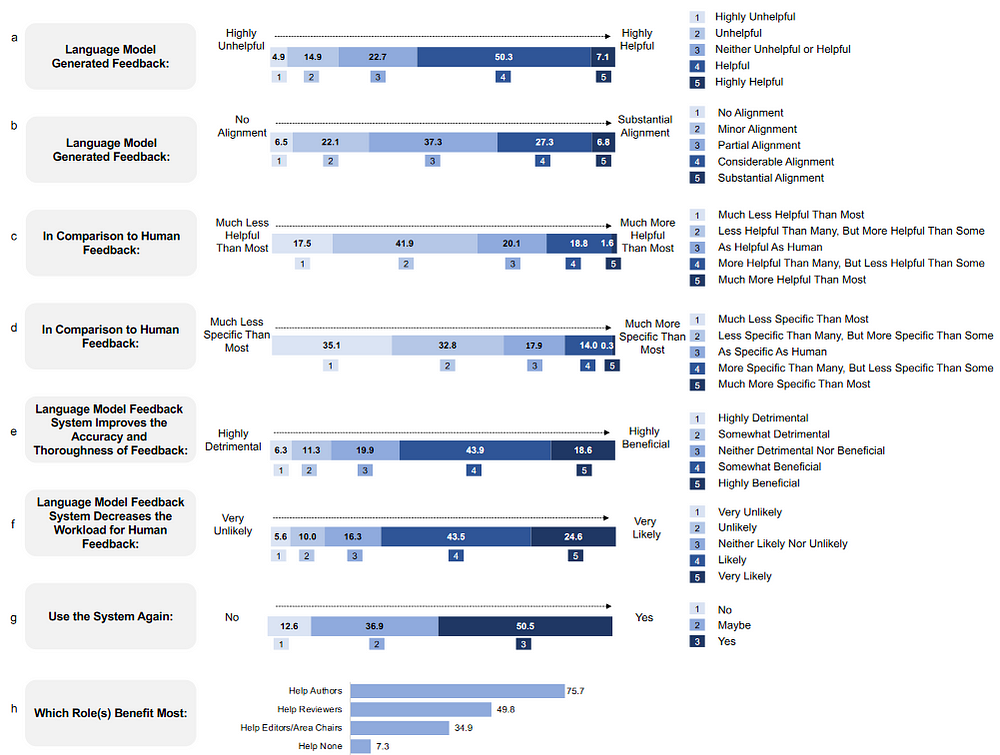
We then conducted a prospective user study with 308 researchers from 110 US institutions in artificial intelligence and computational biology to understand how researchers perceived the feedback generated by our GPT-4 system on their papers. Overall, more than half (57.4%) of users found the feedback generated by GPT-4 helpful/very helpful, and 82.4% found it more helpful than feedback from at least some real-person reviewers.
Although our findings suggest that LLM-generated feedback can be helpful to researchers, we also identify some limitations. For example, GPT-4 tends to focus on certain aspects of scientific feedback (e.g. ‘adding experiments on more datasets’) and often struggles to provide an in-depth critique of method design.
Our results show that LLM and human feedback can complement each other. While human expert review is and should continue to be the foundation of the rigorous scientific process, LLM feedback can benefit researchers, especially when timely expert feedback is not available and in the early stages of manuscript preparation before peer review.
Images



Summary
- Large language models (LLMs) can potentially provide feedback on research papers.
- Due to the increase in scientific production and specialization, traditional scientific feedback mechanisms are becoming more challenging.
- LLM-generated feedback was evaluated through two large-scale studies comparing it to human peer reviewer feedback.
- The overlap between GPT-4 and the scores reported by real personal reviewers is comparable to the overlap between two real reviewers.
- In a user study, more than half of researchers found GPT-4 feedback to be helpful.
- Limitations of LLM-generated feedback include focusing on specific aspects and struggling with in-depth criticism.
- LLMs and human feedback can complement each other.
- There is an urgent need for scalable and efficient feedback mechanisms in scientific research.
- LLMs have great potential but their use for scientific feedback remains largely unknown.
- This study provides the first large-scale analysis of the use of LLMs to generate scholarly feedback.
- A GPT-4-based pipeline was developed to generate structured feedback on various aspects of research articles.
- Developed an automated pipeline using GPT-4 to generate feedback on scientific articles.
- Two datasets (Nature Family Journals and ICLR) were used to assess the quality of LLMs' feedback.
- We conducted a retrospective evaluation comparing LLM feedback to human feedback.
- Subtractive text summarization and semantic text matching were applied to identify shared interpretations between LLM and human feedback.
- It found that there was a significant overlap between LLM feedback and human-generated feedback.
- The overlap between LLM feedback and human feedback was comparable to the overlap between two human reviewers.
- The results were consistent across decision results of different academic journals and articles — the overlap between LLM feedback and human feedback comments was analyzed in the ICLR dataset.
- There was an average of 30.63% overlap between LLM feedback and human feedback comments on papers accepted through oral presentations.
- The average overlap increased to 32.12% for papers accepted through spotlight presentation and to 47.09% for rejected papers.
- Similar trends were observed in the overlap between two human reviewers.
- Rejected papers may have more specific problems or flaws that both human reviewers and LLM Experts can consistently identify.
- LLM feedback can be constructive for papers that require significant revisions.
- LLM feedback is article-specific, not general.
- LLMs are more likely to identify common problems recognized by multiple human reviewers.
- LLMs are aligned with human perspectives on big or important issues.
- Earlier comments in human feedback are more likely to coincide with LLM comments.
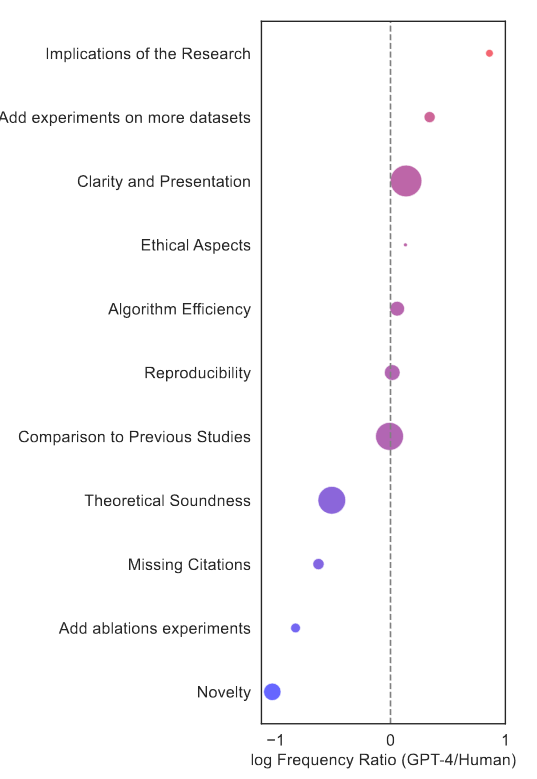
- LLM feedback emphasizes certain aspects more than humans, such as the implications of the research and requesting experiments on more data sets.
- Human-AI collaboration can provide benefits by combining the focus of the LLM with the highlights of human reviewers.
- A survey study was conducted on researchers to evaluate the utility and performance of LLM-generated scientific feedback. The approach is subject to self-selection biases.
- The data provides researchers with valuable information and subjective perspectives.
- User research results show a significant overlap between LLM feedback and human feedback.
- The feedback generated by the LLM is considered useful by the majority of participants.
- LLM feedback is less specific from some reviewers but more specific from others.
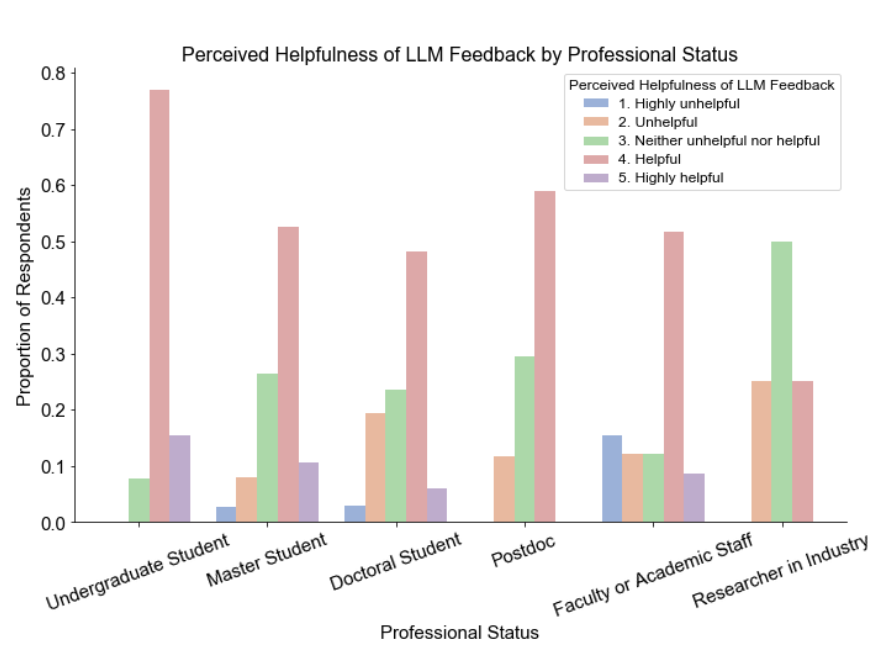
- Perceptions of agreeableness and helpfulness are consistent across various demographic groups.
- Participants express their desire to reuse the system and believe in its potential for improvement.
- LLMs can generate new feedback that people aren't talking about.
- Limitations of LLM feedback include the ability to generate specific and actionable feedback.
- LLM feedback can be a valuable resource for writers looking for constructive feedback and suggestions.
- Feedback from LLMs can be particularly useful for researchers who do not have access to timely quality feedback mechanisms.
- The developed framework can be used to self-check and improve the work promptly.
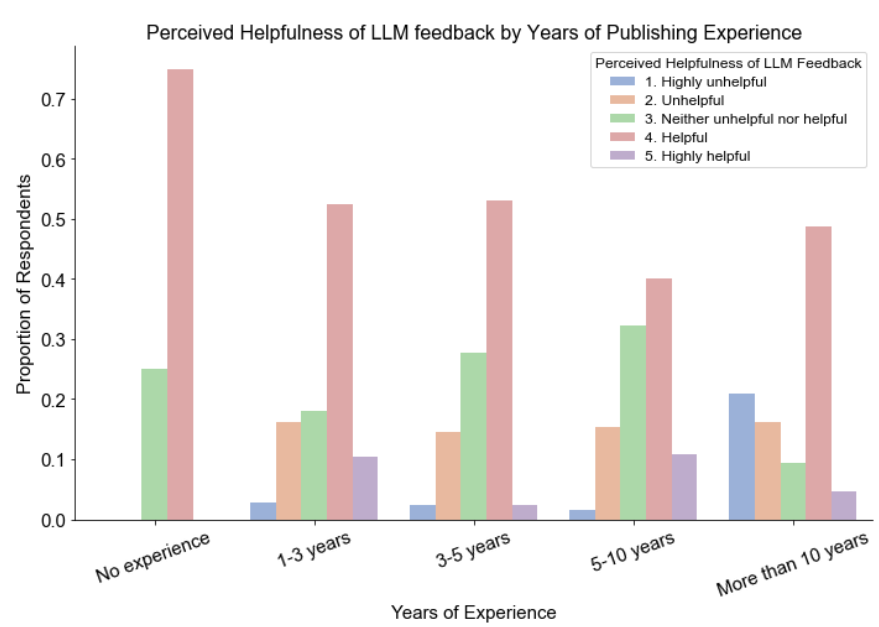
- LLM feedback is useful for people with different educational backgrounds and publishing experiences.
- Expert human feedback scientific evaluation
- e will continue to maintain its importance.
- Feedback from LLMs has its limitations and can feel generic to authors — LLM feedback should primarily be used by researchers to identify areas for improvement in their papers before formal submission.
- Expert human reviewers should engage with papers in-depth and provide independent evaluation without relying on LLM's feedback.
- Automatically generating reviews without thoroughly reading the manuscript undermines the rigorous evaluation process.
- LLMs and generative AI have the potential to increase productivity, and creativity, and facilitate scientific discovery when implemented responsibly.
- The results of the research are based on a specific example of scientific feedback using the GPT-4 model.
- The system only leverages GPT-4's zero-shot learning without fine-tuning additional datasets.
- Future work could explore other LLMs, conduct more complex prompt engineering, and combine labelled datasets for fine-tuning.
- The study used Nature family data and ICLR data, but future studies need to evaluate the framework more broadly.
- User research is limited in scope and suffers from a self-selection problem.
- The current version of the GPT-4 model does not understand and interpret visual data such as tables, graphs, and figures.
- Future studies could investigate integrating visual LLMs or dedicated modules for comprehensive scientific feedback.
- Future studies could investigate to what extent the proposed approach can help identify and correct errors in scientific articles.
- It is crucial to understand the limitations and challenges associated with error detection and correction by LLM.
- The scope of scientific articles evaluated may be expanded to include articles in languages other than English or for non-native English speakers.
- The dataset includes papers from 15 Nature family journals and papers from the International Conference on Learning Representations (ICLR).
- The Nature dataset contains 3,096 accepted articles and 8,745 reviews, while the ICLR dataset contains 1,709 articles and 6,506 reviews.
- PDFs and related reviews were retrieved using the OpenReview API.
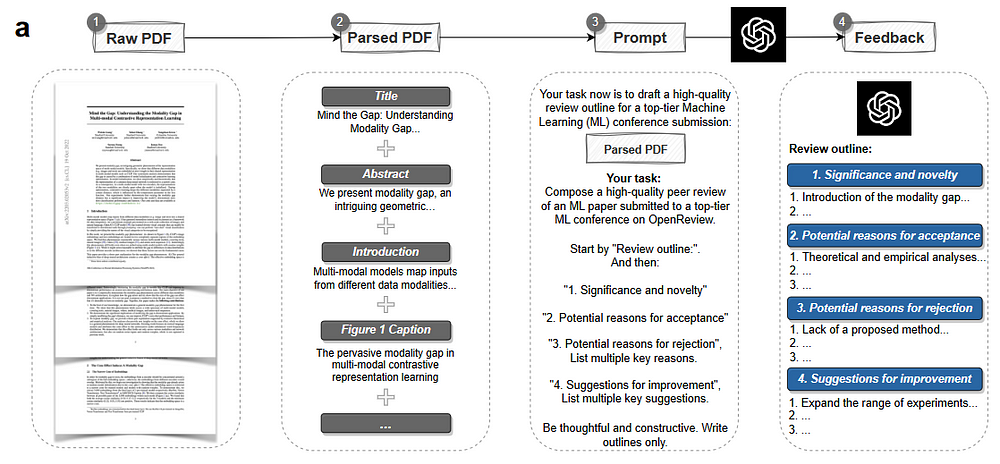
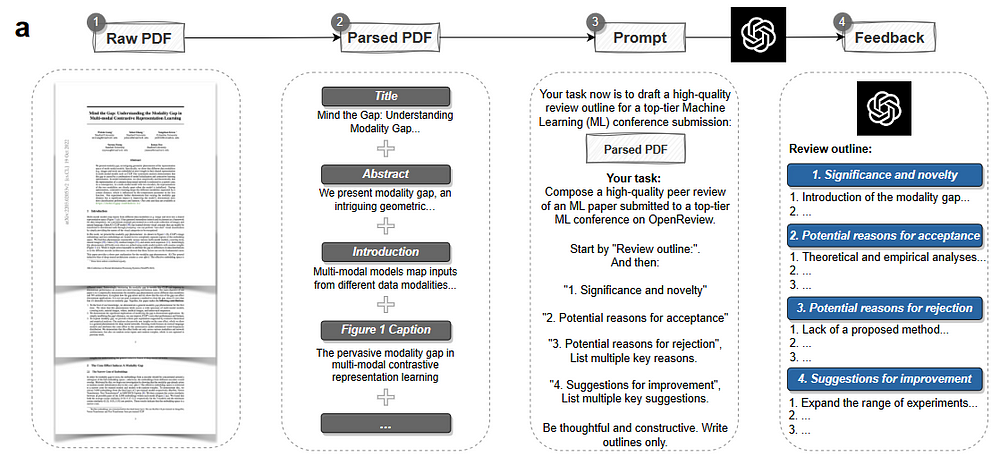
- Prototyped a pipeline to generate scientific feedback using OpenAI’s GPT-4.
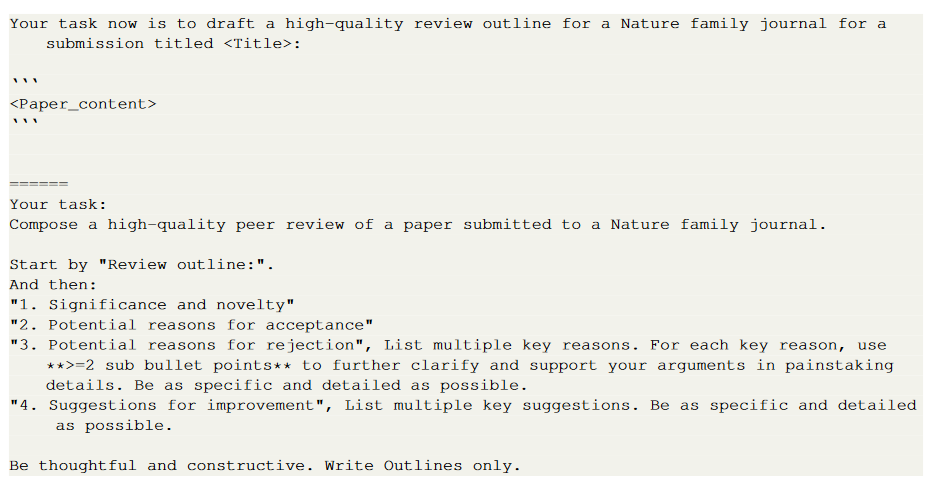
- The input to the system was an academic article in PDF format, parsed using the ScienceBeam PDF parser.
- The first 6,500 tokens of the article were used to create the GPT-4 claim.
- Specific instructions were provided for creating the following four feedback sections: importance and novelty, potential reasons for acceptance, potential reasons for rejection, suggestions for improvement.
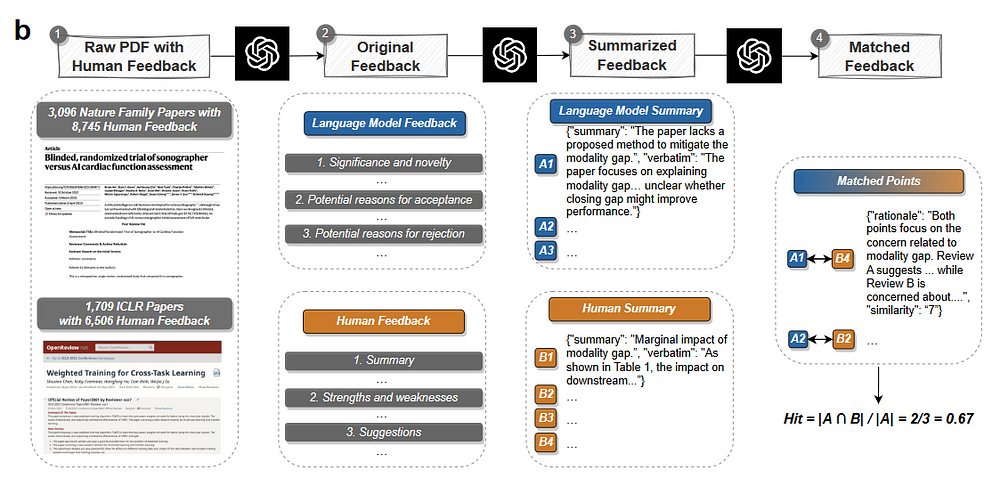
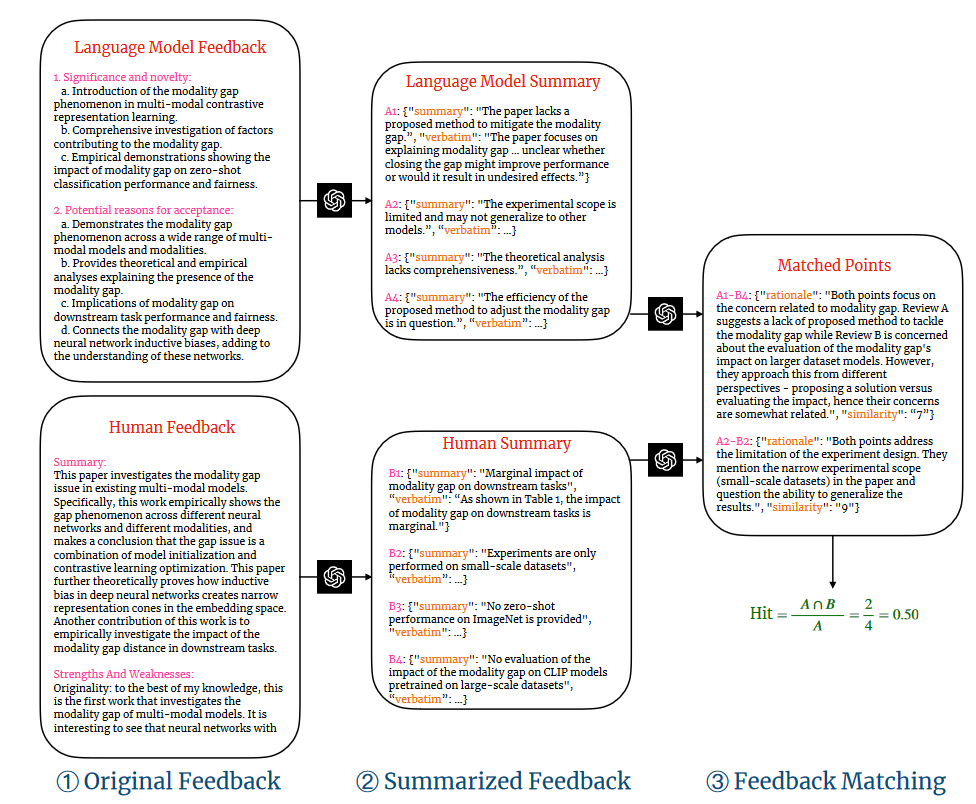
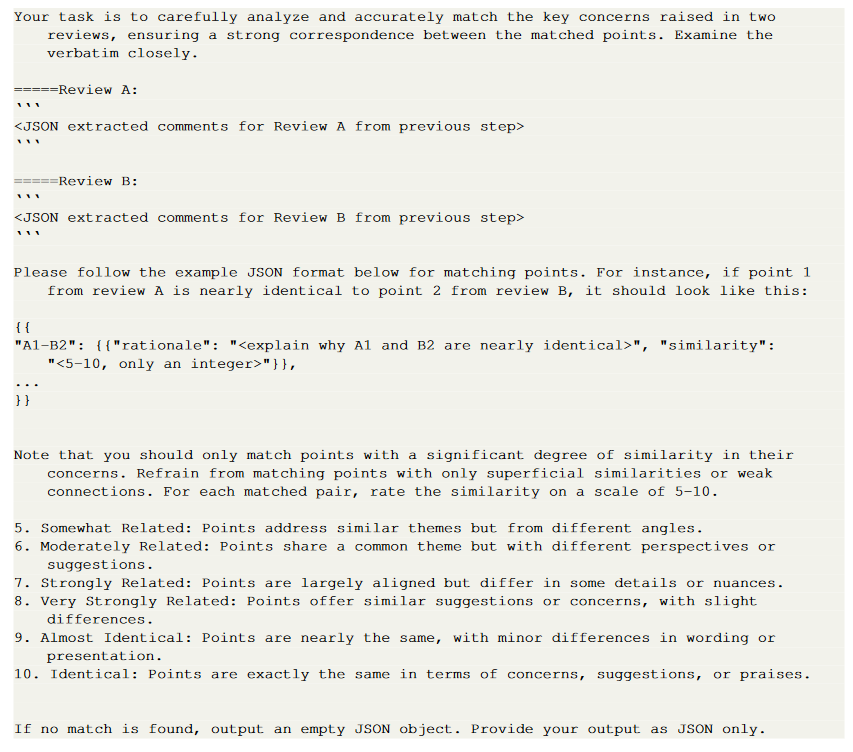
- A two-stage comment matching pipeline was developed to evaluate the overlap between LLM feedback and human feedback.
- Inferential text summarization was used to extract comment points from the feedback.
- Semantic text matching was performed to match human feedback with comments from LLM.
- Relevant” or above was retained for subsequent analysis.
- The accuracy of the inferential summarization phase was verified using human verification.
- The semantic text-matching phase showed good inter-annotator agreement and reliability.
- The specificity of LLMs' feedback was evaluated by comparison with scrambled human feedback.
- Pairwise overlap of LLMs and Human and Human and Human feedback was evaluated using the hit rate.
- The results showed similar hit rates for both comparisons; This suggests that LLM feedback is often not general. — The study examines the robustness of the results using different cluster overlap metrics.
- A compiled annotation scheme of 11 key aspects is used to analyze comment aspects in human and LLM feedback.
- A random sample of 500 articles from the ICLR dataset is selected for annotation.
- To ensure reliability, two researchers carry out the annotations.
- A prospective user study and survey are conducted to verify the effectiveness of leveraging LLM for scientific feedback.
- Users upload research articles and receive generated reviews, fill out a survey.
- Participants are recruited through relevant institute mailing lists and authors of preprints in computer science and computational biology.
- The study was approved by Stanford University's Institutional Review Board.
- The article presents a modality gap and discusses multimodal models.
- The review draft includes sections on significance and novelty, possible reasons for acceptance and rejection, and suggestions for improvement.
- Artificial intelligence tools have been developed for various tasks in the scientific publication process.
- Previous studies have investigated the effectiveness of ChatGPT and GPT-4 in peer review and analysis of published articles.
- The article presents a new approach to multimodal comparative representation learning.
- It introduces the concept of modality space, which is a geometric phenomenon.
- The authors propose a multimodal model that maps inputs from different data modalities into a common representation space, providing a new approach to address the method gap.
- The paper provides empirical evidence of the modality gap phenomenon, supported by histograms of cosine similarity between embeddings.
- The proposed multimodal model shows promising results in reducing the method gap and improving representation learning across different methods.
- The study contributes to a better understanding of the underlying mechanisms by providing insights into the effects of nonlinear activation functions on the cone effect.
- The paper lacks a comprehensive comparison with existing methods in multimodal comparative representation learning, limiting the assessment of its superiority.
- Failure to adequately provide experimental setup and reproducibility details makes it difficult for other researchers to replicate and confirm the findings.
- The ethical implications of the research, such as privacy and data security concerns, are not adequately discussed, raising potential concerns about the societal impact of the proposed approach.
Resources
[1] arXiv:2310.01783










0 Comments