
https://medium.com/@cbarkinozer/phi-1-t%C3%BCm-i%CC%87htiyac%C4%B1n%C4%B1z-olan-ders-kitaplar%C4%B1-makalesi-37cdba8c9937

This article has shown in the context of code LLMs that even small models with little but quality data can challenge large models.
Abstract
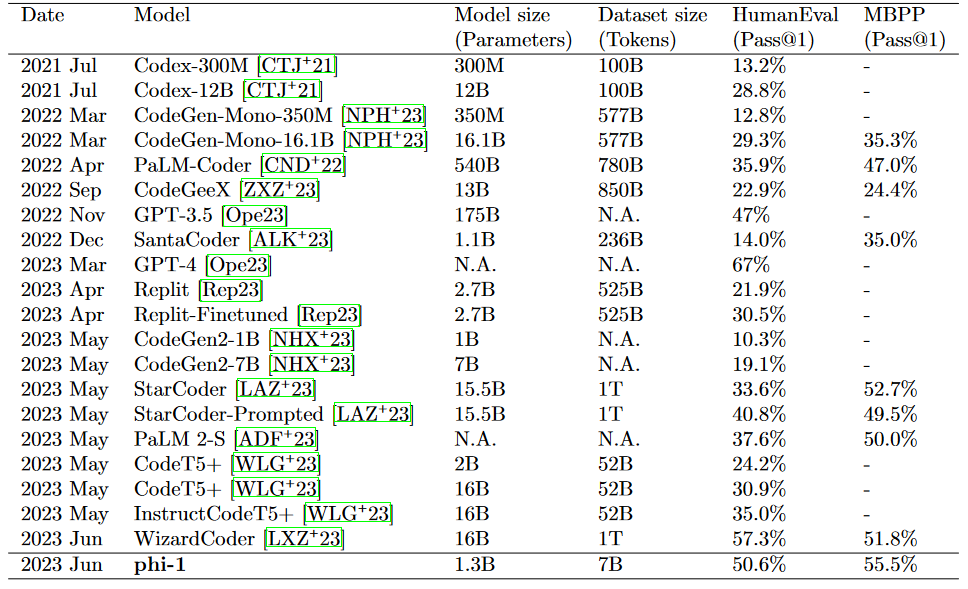
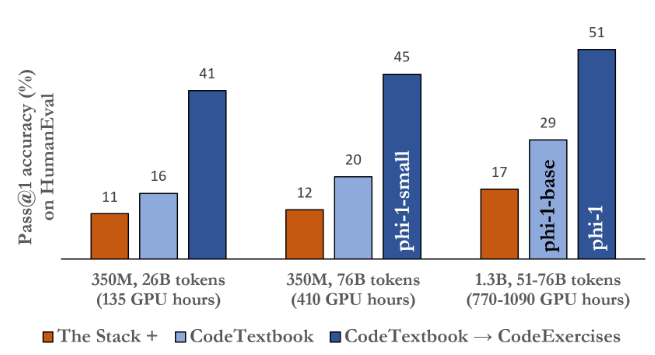
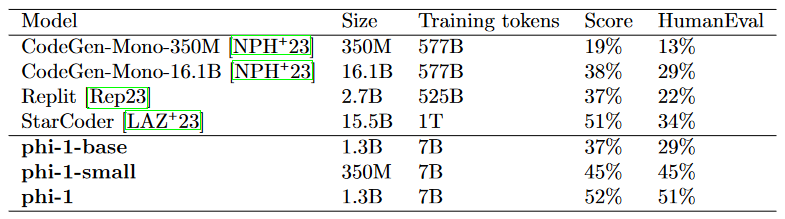
The Phi-1 code LLM is significantly smaller than the competing models. It is a model with 1.3D parameters and was trained using various "textbooks" over 4 days on 8 A100s. It consists of "quality" data from the internet (with 6B tokens), synthetically generated textbooks, and exercises made with GPT-3.5 (with 1B tokens). This small scale was able to achieve 50.6% pass@1 accuracy on HumanEval and 55.5% pass@1 accuracy on MBPP. However, it shows surprising properties compared to the phi-1-base. Our model before fine-tuning on a dataset of coding exercises and phi-1-small was trained along the same pipeline as phi-1 with 350M parameters and achieving 45% accuracy on HumanEval.
Summary
- Phi-1, a 1.3D parameterized transformer-based code llm, is introduced.
- Pass@1 accuracy of 50.6% in HumanEval and 55.5% in MBPP was achieved by Phi-1.
- Research on training large artificial neural networks is very limited.
- Scaling laws show that performance increases as computing or network size increases.
- Eldan and Li's work on TinyStories has shown that high-quality data can change performance and scaling rules.
- The latest technologies of large language models can reduce training computations and dataset sizes by using high-quality data.
- While training LLMs, the focus is on coding and writing Python methods.
- Current scaling laws prohibit the use of high-quality data.
- Although phi-1 is lower than competing models, it shows high accuracy.
- The details of Phi-1's training process, how the data was selected, and the resulting features are discussed.
- The model has been published for public use and evaluation.
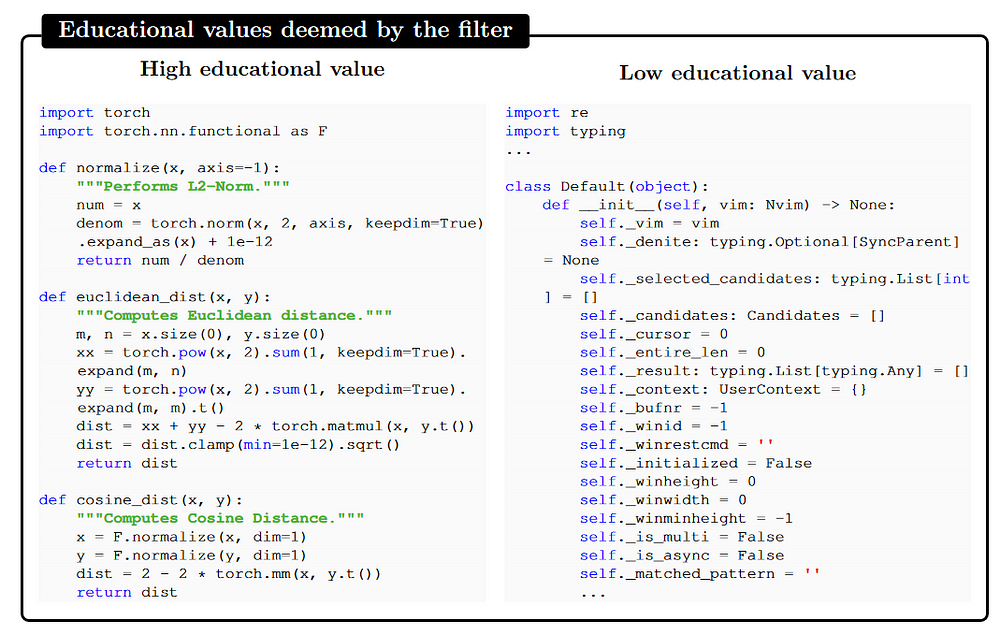
- The importance of coding textbook-quality training data: A large number of standard code datasets are not enough to teach the basics of coding.
- Lack of self-containment, lack of meaningful computation, complexity or inadequate documentation, and uneven distribution of coding concepts are some of the problems in standard code datasets.
- Language models will benefit from a training set that is clear, self-contained, didactic, and balanced.
- There are three main datasets used for training: filtered code language, synthetic textbooks, and synthetic exercises.
- “Code Textbook” is a combination of filtered code language and synthetic textbook datasets.
- Small synthetic training data needs to be collected to fine-tune the model.
- GPT-4 is used to evaluate the quality of a subset of code samples.
- Model performance can be significantly improved using filtering methodology.
- Diversity in examples is important to expose the model to a variety of coding ideas and increase generalization and robustness. Language models tend to create redundant and homogeneous datasets.
- Adding randomness to the prompt can make a difference in the text generated.
- Different topics and target audience constraints helped create synthetic textbooks.
- Python's synthetic exercise dataset contains exercises and solutions.
- Only the decoder transformer model was used for the FlashAttention implementation.
- Architectural details of the models (phi-1 and phi1-small)
- queue length, optimizer, learning rate schedule, etc. educational information such as.
- Pre-training on the CodeExercises dataset and the CodeTextbook dataset.
- Improvement in execution of tasks not in the fine-tuning dataset.
- Qualitative analysis of the model's performance: The text compares the capabilities between the fine-tuned phi-1 model and the pre-trained baseline phi-1-base model.
- He notes that Phi-1 showed better understanding and compliance with instructions after the fine-tuning was applied.
- Phi-1-base interprets and produces logical relationships in prompts, but phi-1 interprets and produces correct answers.
- Even the smaller phi-1-small model shows an understanding of the problems, but their solutions are wrong.
- Minor changes to CodeExercises increase the model's ability to use external libraries, the text says.
- It provides an example of a PyGame program where phi-1 correctly implements PyGame functions and phi-1-base and phi-1-small produce unrelated function calls.
- Another example is in the TKinter app where phi-1 correctly updates a text field based on user input, and phi-1-base and phi-1-smael struggle with task logic. — The code includes buttons and functions from the Tkinter GUI.
- While phi-1-base, phi-1-small and phi-1 implement the GUI correctly, the other two models do not use the Tkinter APIs correctly.
- A discussion is provided between an assistant and a student to increase resolution and rotate the Python pyplot.
- Concerns about memorization and contamination of the dataset are eliminated.
- A new evaluation method was developed with GPT-4 to evaluate coding solutions.
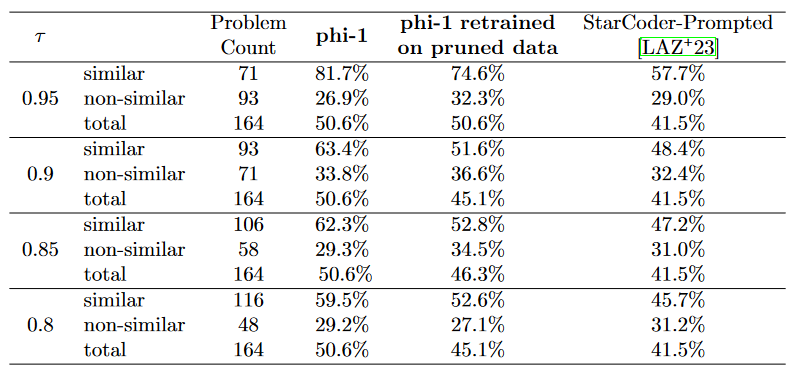
- The results show that phi-1 works better than StarCoder on unfamiliar questions.
- Data pruning experiments are applied to evaluate the performance.
- HumanEval did not cause harm according to a normal contamination test from CodeExercises.
- The data set is subjected to N-gram overlap analysis. — Minimal letter overlap using HumanEval
- HumanEval returns the largest integer whose frequency is greater than zero and greater than or equal to the value of the integer.
- CodeExercises: Calculates the total power frequency analysis of a list of integers.
- Use embedding and syntax-based distances to find similar code snippets from HumanEval and CodeExercises.
- Code pairs with similar code semantics are detected using embedding distance.
- Syntax-based distance is used to find the edit distance between abstract syntax trees (ASTs) of code snippets.
- CodeExercises are pruned based on insertion distance and thresholds for different AST match rates.
- Pruned datasets compare the performance of phi-1 retrained on StarCoder-Prompted and the original phi-1.
- Accuracy of models for subsets of HumanEval problems.
- The importance of high-quality data in improving language model proficiency in coding tasks
- limitations of phi-1 compared to larger models for coding
- Potential for creating synthetic data with GPT-4.
- Creating high-quality datasets involves scope, diversity, and redundancy of content.
- Lack of methods to measure and evaluate redundancy and diversity in data.
- Social and moral implications of training language models and curating data for future models
- Example of challenging expression for the model before fine-tuning and performance increase after fine-tuning. The first code snippet searches for indices in a numeric matrix D that meet certain conditions.
- A PyTorch function that performs a modified gradient update on the parameters of a model is known as the second snippet.
- The Pyplot application that animates a line chart is shown in the third code snippet.
- The different ways a given request is completed by the phi-1-small and phi-1-base models is known as the fourth code snippet.
- The limitations and weaknesses of the model, as well as sensitivity to instantaneous changes, are addressed by the fifth code snippet.
- The sixth code snippet asks you to create a three-layer neural network class in PyTorch and use a new method known as “rr”.
- The seventh code snippet is a similar prompt with four layers instead of three.- Create a neural network class with four layers with Pytorch.
- Nonsense codes can be created for spatial reasoning and numerical tasks.
Görseller

Conclusion
Like the comprehensive and well-crafted preparation of a textbook, our work demonstrates the remarkable impact of high-quality data in improving the adequacy of a language model for code generation tasks. By generating “textbook quality” data, we were able to train a model that outperformed nearly all open-source models on coding benchmarks such as HumanEval and MBPP. This was despite being ten times smaller in model size and a hundred times smaller in dataset size. We believe that such high-quality data significantly increases the effectiveness of learning coding language models because they provide clear, independent, instructive, and balanced examples of coding concepts and skills. Compared to larger models for encoding, our model faces some limitations. First, compared to multilingual models, phi-1 Python coding ability is limited.
Second, phi-1 does not have specific knowledge of larger models, such as programming with specific APIs or using less common packages. Finally, phi-1 is less robust to stylistic changes or errors in prompting due to the structured nature of the datasets and lack of diversity in terms of language and style. Grammatical errors significantly reduce its performance. desire). We will expand on these limitations and provide examples of failure modes of phi-1. We will further expand on these limitations in Appendix B. None of these limitations appear fundamental, and with further work, our approach can be used to overcome them. However, it is unclear what scaling can be achieved. These may need to be overcome because both the model and the dataset can be large.
Additionally, since we noticed that GPT-3.5 data has a high error rate, we believe that using GPT-3.5 instead of GPT-4 can be of great benefit to generating synthetic data. Interestingly, Phi-1 has such good coding ability despite these errors (a similar case was found in [AZL23] where a language model could be trained on data with a 100% error rate and still give correct answers during testing). Overall, our work shows that developing a good technique for generating high-quality datasets is an important component of research aimed at advancing natural language processing and related fields (see [JWJ+23] for more information). However, creating high-quality datasets is a challenging task and comes with numerous issues that need to be addressed.
It is difficult for the dataset to cover all the relevant content and concepts that the model wants to learn and to do so in a balanced and representative way. Ensuring that the dataset is truly diverse and not repetitive is another hurdle that prevents the model from overfitting the data or memorizing certain patterns or solutions. This means finding ways to maintain the quality and consistency of samples, as well as add creativity and randomness to the data generation process. Even after creating such datasets, we do not have a suitable method to measure and evaluate the diversity and redundancy in the data. For example, if we have a dataset containing coding exercises, it is difficult to figure out how many different variations of each exercise there are and how they are distributed across the dataset.
Finally, since language models themselves will be used to curate data for future language models, the ethical and social implications of training such models are even more important, such as transparency, accountability, and bias of data and models. participants in this transaction.
Resource
[1] Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, 2 Oct 2023, Textbooks Are All You Need:










0 Comments