
https://medium.com/@cbarkinozer/pytorch-ustal%C4%B1k-serisi-b%C3%B6l%C3%BCm-1-5bbd829af937
The first part of a series I started as a comprehensive guide to building and training neural networks with PyTorch.
What will we learn in the entire series?
- Fundamentals of Pytorch.
- Preprocessing of data.
- Building and using pre-trained deep learning models.
- Fitting data to a model.
- Don't make predictions with data.
- Evaluating model predictions.
- Save models and restore saved models.
In what situations should we not use artificial intelligence?
Situations where deep learning is not good:
- When you need explainability: Patterns learned by a deep learning model are often uninterpretable by humans.
- Where the traditional approach is a better option: Deep learning is not necessary if you can meet your need with a simple rule-based system.
- When errors are unacceptable: If errors are unacceptable, deep learning is not the best choice because the outputs of deep learning models are not always predictable.
- When you don't have a lot of data: Deep learning models generally need a lot of data to produce good results.
If your data is structured, such as an Excel table, then it makes more sense to use XGBoost, but if your data is unstructured, such as text, then deep learning may be preferred.
Unlike machine learning, deep learning has progressed in the form of fully connected neural networks, convolutional neural networks, recurrent neural networks and transformers.
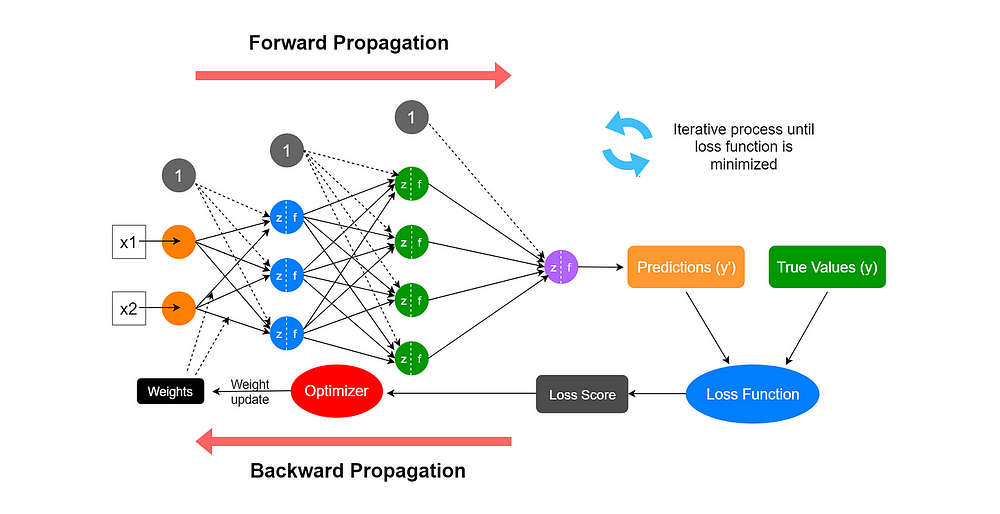
Artificial Neural Network (ANN)
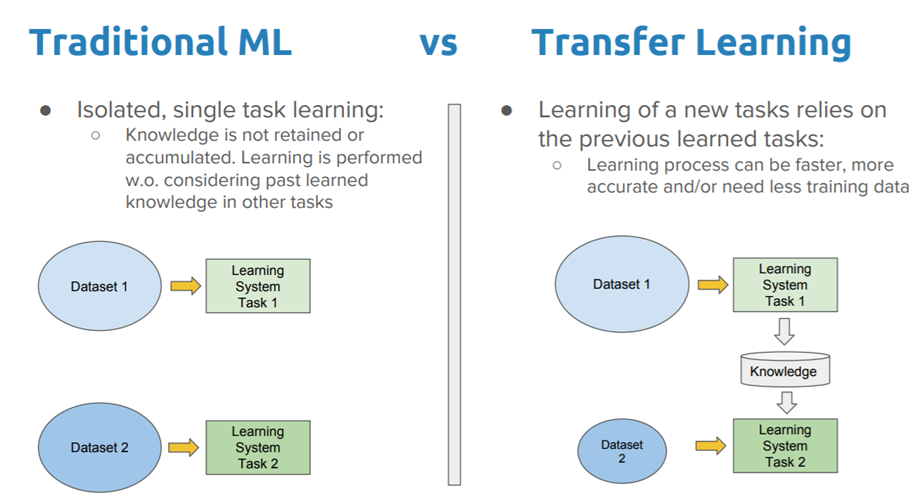
Transfer Learning
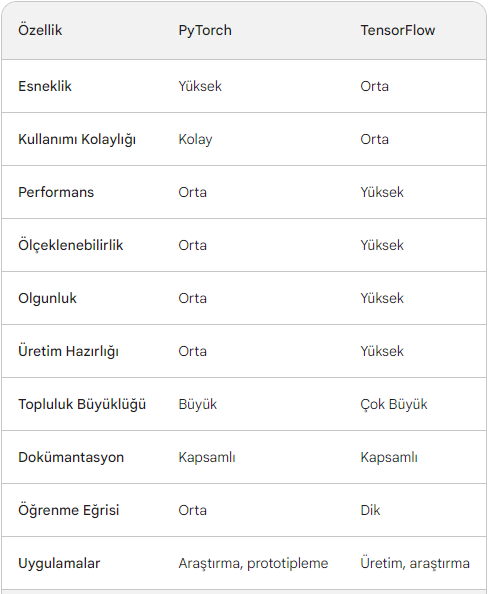
Pytorch
PyTorch is an open-source Python library for building and training deep learning models. It was developed by Meta AI (formerly Facebook AI Research) and is used by a wide range of researchers and practitioners in academia and industry. PyTorch is known for its flexibility, ease of use, and performance. It can be used to build a wide variety of deep learning models, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and generative adversarial networks (GANs).
Key Features of PyTorch:
- Imperative Programming Style: PyTorch uses the imperative programming style, which allows more control over data flow and calculation. This makes the code easier to understand and debug, especially for beginners.
- Dynamic Computation Graph: PyTorch's computation graph is dynamic, that is, it can be changed at run time. This makes it more flexible than TensorFlow's static computational graph.
- Automatic Gradient Calculation: PyTorch automatically calculates the gradients of your model's parameters according to the loss function. This makes it easier to train your model using gradient-based optimization algorithms.
- Rich Ecosystem: PyTorch has a rich ecosystem of tools and libraries, including PyTorch Lightning, TorchServe, and PyTorch Profiler.
Comparison of Pytorch and Tensorflow
PyTorch
Strengths
- Flexibility: PyTorch offers a more flexible and dynamic computational graph compared to TensorFlow, allowing greater control over model creation and execution.
- Ease of use: PyTorch's imperative programming style makes it easy to understand and debug code, especially for beginners.
- Extensive community: PyTorch has a growing and active community that provides abundant resources and support.
Weaknesses
- Performance: PyTorch can be slower than TensorFlow in some cases, especially for large-scale models.
- Scalability: PyTorch's scalability may be limited for large-scale production deployments.
TensorFlow
Strengths
- Performance: TensorFlow is known for its high performance and scalability, making it suitable for large-scale production deployments.
- Maturity: TensorFlow is a mature and well-established framework with a large user base and extensive documentation.
- Production-ready: TensorFlow offers a wide range of production-ready features, such as model distribution and presentation tools.
Weaknesses
- Complexity: TensorFlow's static computational graph can make it more complex and less intuitive to use, especially for beginners.
- Detail: TensorFlow's code may be more verbose and less readable than PyTorch.
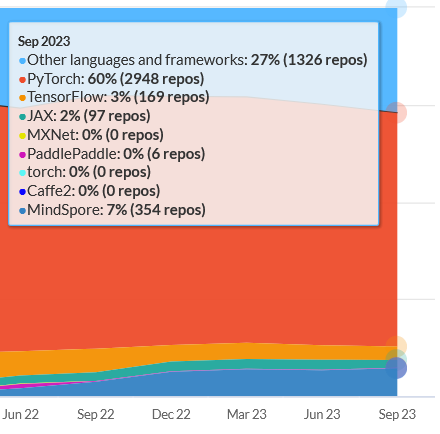
In summary, PyTorch is easier and more popular in terms of research, but it is slower than Tensorflow and not production environment friendly.
Large Companies using PyTorch
- Facebook was one of the first companies to adopt PyTorch, and it is used in a variety of products and services, including Facebook's News Feed, facial recognition software, and chatbots.
- Uber uses PyTorch to develop driverless cars. The company's machine learning team uses PyTorch to train models that can predict traffic patterns and make decisions about how to navigate roads.
- Airbnb uses PyTorch to develop recommendation systems that recommend properties to users. The company's machine learning team uses PyTorch to train models that can predict which properties users will book most.
- Pinterest uses PyTorch to develop image recognition software that can identify objects in images. The company's machine learning team uses PyTorch to train models that can identify objects in pins and recommend similar pins to users.
- Twitter X uses PyTorch to develop natural language processing (NLP) software that can understand the meaning of tweets. The company's machine learning team uses PyTorch to train models that can identify spam, detect abuse, and understand the meaning of tweets.
- Tesla uses PyTorch in its Autopilot autonomous driving system to process sensor data, make driving decisions, and continuously improve the system's performance. PyTorch's flexibility and ease of use make it well-suited for developing and deploying complex deep learning models in real-time applications such as autonomous driving.
- OpenAI uses PyTorch for a wide variety of research projects, including generating human-quality text, translating languages, and developing new reinforcement learning algorithms. PyTorch's dynamic computational graph and automatic gradient calculation capabilities make it a powerful tool for exploring new frontiers in artificial intelligence research.
How does PyTorch work?
PyTorch uses the CUDA platform to utilize GPUs or TPUs.
GPU vs TPU
GPUs were originally designed for graphics rendering, but their parallel processing architecture has made them highly efficient for data-parallel calculations. They have thousands of smaller, lightweight cores that can perform multiple tasks simultaneously; This makes them well-suited for workloads that can be split into many independent calculations.
TPUs, on the other hand, are specially designed for machine learning and deep learning applications. These are custom-built processors developed by Google that excel at performing matrix multiplication and other operations commonly used in neural networks. TPUs are more specialized than GPUs and offer higher performance and energy efficiency for machine learning tasks.
CUDA
CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model developed by NVIDIA for general computing on graphics processing units (GPUs). CUDA gives software developers direct access to the GPU's virtual instruction set and parallel computing elements, allowing the execution of computing kernels, which are programs written in C, C++, Python, and other languages that can be passed to the GPU for parallel execution.
CUDA revolutionized high-performance computing by allowing GPUs to be used for a wide variety of applications previously dominated by CPUs. This is because GPUs are highly parallel processors with thousands of cores, making them well-suited for data-intensive tasks such as scientific computing, machine learning, and graphics processing.
Some key features of CUDA are:
- Parallel Computing: CUDA allows developers to write code that can be executed on multiple GPU cores simultaneously, taking advantage of the parallel processing power of the GPU.
- Unified memory: CUDA provides a unified memory area accessible from both the CPU and GPU, allowing seamless data transfer between the two.
- Shared memory: CUDA provides shared memory, which is a high-speed memory shared by all GPU threads in a warp, reducing memory access latency.
- Dynamic parallelism: CUDA supports dynamic parallelism, which allows threads to start new threads during kernel execution, making more efficient use of GPU resources.
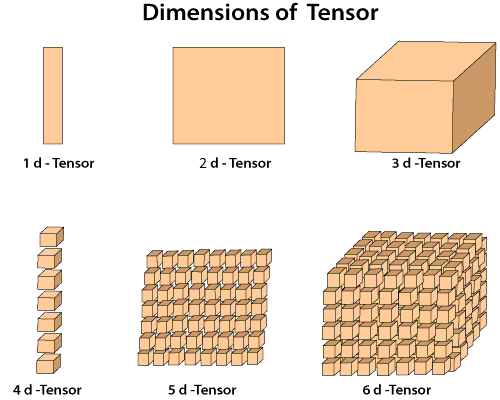
Tensor
Tensors are geometric objects that describe linear relationships between geometric, numerical, and other traction vectors. They are basically n-dimensional arrays.
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltscalar = torch.tensor(7)
print(scalar.ndim) #0
print(scalar.item) #7vector = torch.tensor([7,7])
print(vector.ndim) # Has 1 dimension (the number of square brackets)
print(vector.Size([2])) # 2 elementsmatrix = torch.tensor([[7,8],[9,10]])
print(matrix.ndim) #2
print(matrix[0]) #[7,8]
print(matrix.shape) #torch.Size([2,2])tensor = torch.tensor([[1,2,3],[4,5,6],[7,8,9]])
print(tensor.ndim) # 3
print(tensor.shape) # [1,3,3]
print(tensor[0]) #[1,2,3],[4,5,6],[7,8,9]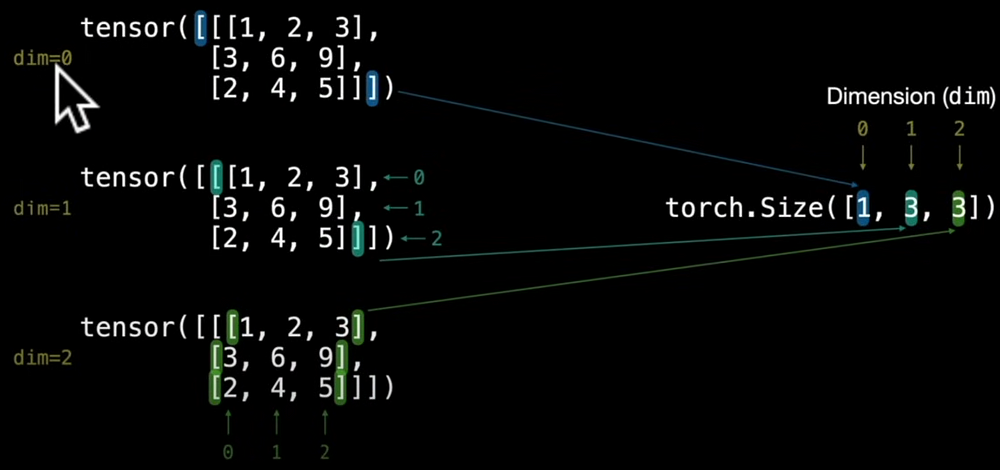
Random Tensors
Random tensors are important because neural networks start with random numbers and adjust them to better represent the data.
random_tensor = torch.rand(3,4)
print(random_tensor.ndim) # 2
random_tensor = torch.rand(1, 10, 10)
print(random_tensor.ndim) # 3Zero and One Tensors
One-dimensional tensors consisting only of zeros or ones are called zero or one tensors. These tensors are useful structures to use because you cannot fill the existing data with ones or zeros.
zeroes = torch.zeroes(size=(3,4))
ones = torch.ones(size=(3,4))
print(ones.dtype) # The default data type is float32Range of Tensors
With this method, you can create tensors that increase in a certain way within a certain range.
one_to_ten = torch.arange(1,11) # [1,11]
torch.arange(start=0,end=1000,step=77) # Increase by 77ten_zeros = torch.zeros_like(input=one_to_ten)Float_16
float_16 = torch.tensor([3.0,6.0,9.0], dtype=float16)
print(float_16.dtype) #float16Tensor data types are one of the 3 common errors you will encounter in Pytorch:
- Tensors are not of the correct type.
- Tensors are not shaped correctly.
- Tensors are not on the correct device.
# device parameter sets the device either cuda or cpu
# requires_grad parameter chooses whether or not to track gradients with this tensors operations
float_16 = torch.tensor([3.0,6.0,9.0], dtype=float16, device="cuda", requires_grad=False)To convert float32 tensor to float16 tensor:
float_16_tensor = float_32_tensor.type(torch.float16)For more information, here is the article on precision in computing: https://en.wikipedia.org/wiki/Precision_(computer_science)
Tensor Manipulation
When artificial neural networks operate, they use the following tensor manipulations.
- Addition
- Substraction
- Element-wise Multiplication
- Divison
- Matrix Multiplication or Dot Product
tensor = torch.tensor([1,2,3])
print(tensor+10) #tensor([11, 12, 13])
print(tensor-10) #tensor([-9, -8, -7])
print(tensor*10) #tensor([10, 20, 30])
print(tensor-10) #tensor([11, 12, 13])You can also choose torch's methods. These methods are generally preferred when they are a more complex operation with different parameters.
tensor = torch.tensor([1,2,3])
result_add = torch.add(tensor, 10)
print(result_add) # tensor([11, 12, 13])
result_sub = torch.sub(tensor, 10)
print(result_sub) # tensor([-9, -8, -7])
result_mul = torch.mul(tensor, 10)
print(result_mul) # tensor([10, 20, 30])
result_div = torch.div(tensor, 10)
print(result_div) # tensor([0.1, 0.2, 0.3])Other parameters of these methods:
- input (
tensor):
- The input tensor to be processed.
2. other:
- Another tensor or scalar value with the same size as input.
- It is the other operand of the element-wise operation between two tensors.
3. out (optional):
- The output tensor to which the result will be assigned.
- If not specified, a new tensor is created.
4. dtype (optional):
- The output determines the data type of the tensor.
- For example, it can be specified as dtype=torch.float.
5. where (optional):
- It is used to specify a condition. It is used to determine the conditions under which the element-wise operation between two tensors will be performed.
6. alpha (optional):
- A scalar value is used in some operations.
Matrix Multiplication or Dot Product
The matrix multiplication process is used in many points of artificial neural networks.
- Efficient Representation of Data:
In artificial neural networks, data is often represented as matrices. Each row of the matrix corresponds to a different input feature, and each column corresponds to a different data point or sample. This representation allows efficient processing of large data sets.
2. Weighted Total of Inputs:
The connection between each neuron in a neural network is usually associated with a weight. The process of calculating the weighted sum of input is a fundamental operation in neurons. This operation can be expressed effectively using matrix multiplication. The input matrix represents the input features, while the weight matrix represents the synaptic weights.
3. Linear Transformations:
Neural networks consist of layers of neurons, and the output of each layer is the result of applying a linear transformation to the input data. Matrix multiplication provides a compact and efficient representation of these linear transformations.
4. Batch Processing
Matrix multiplication enables simultaneous processing of multiple inputs; this is often referred to as batch processing. This is important for parallelizing and optimizing computations, allowing to training of neural networks more efficiently, especially on hardware such as GPUs that are highly optimized for matrix operations.
5. Backpropagation and Gradient Descend:
During the training of neural networks, the backpropagation algorithm is used to adjust the weights based on the error in the network's predictions. This involves calculating gradients based on weights. Matrix multiplication is important to efficiently compute these gradients and update the weights using optimization algorithms such as gradient descent.
6. Flexibility in Network Architectures:
The use of matrix multiplication provides flexibility to design and implement a variety of neural network architectures. The layers can be easily connected by defining weight matrices, and the entire computation can be expressed as a sequence of matrix multiplications and activation functions.
7. Simplifying Network Expressions:
Expressing the operations of neural networks in terms of matrix multiplication makes it easier to understand and implement the mathematical representation of the network. This simplicity is beneficial for both theoretical analysis and practical application.
Matrix multiplication is indicated by the dot symbol and is different from element-by-element multiplication. Below is how matrix multiplication is done:
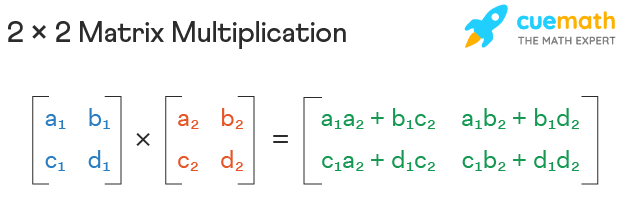
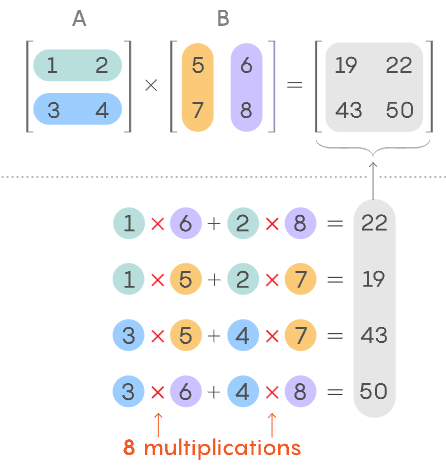
Note: When doing matrix multiplication, the inner dimensions must match. That is, you cannot multiply a (3,2) dimensional matrix with a (3,2) dimensional matrix, but (3,2) (2,3) = (3,3) and the output size will be the outer dimensions. Or you can do (2,3) (3,2) and the resulting dimension will be (2,2).
# Matrix multiplication
tensor = torch.tensor([1,2,3])
torch.matmul(tensor,tensor) # 14 because 1*1+2*2+3*3=14Note: Always use libraries instead of writing an operation yourself in Python.
Note: When using Jupyter Notebook, if you do “%%time” in a cell, you can find the working time of that cell.
Transpose
The transpose operation is used to change the dimensions of matrices. For example, you can transpose a matrix to perform matrix multiplication.
tensor = torch.tensor([[1, 2, 3], [1, 2, 3]])
print(tensor.shape) # torch.Size([2, 3])
print(tensor.T)
"""
tensor([[1, 1],
[2, 2],
[3, 3]])
"""
print(tensor.T.shape) # torch.Size([3, 2])Finding minimum, maximum, average and total values of tensors
The float() method is used in the code below because it must be of float32 type in order for the mean() method to be used.
tensor = torch.tensor([[1, 2, 3], [1, 2, 3]])
print(torch.min(tensor)) # 1
print(torch.max(tensor)) # 3
print(torch.mean(tensor.float())) # 2.0
print(torch.sum(tensor)) # 12Resources
[1] freeCodeCamp.org, (6 Ekim 2022), PyTorch for Deep Learning & Machine Learning — Full Course:
[https://www.youtube.com/watch?v=V_xro1bcAuA&t]
[2] mrdbourke, (20 Kasım 2023), pytorch-deep-learning:
[https://github.com/mrdbourke/pytorch-deep-learning]
[3] mrdbourke, (2023), Zero to Mastery Learn PyTorch for Deep Learning:










0 Comments