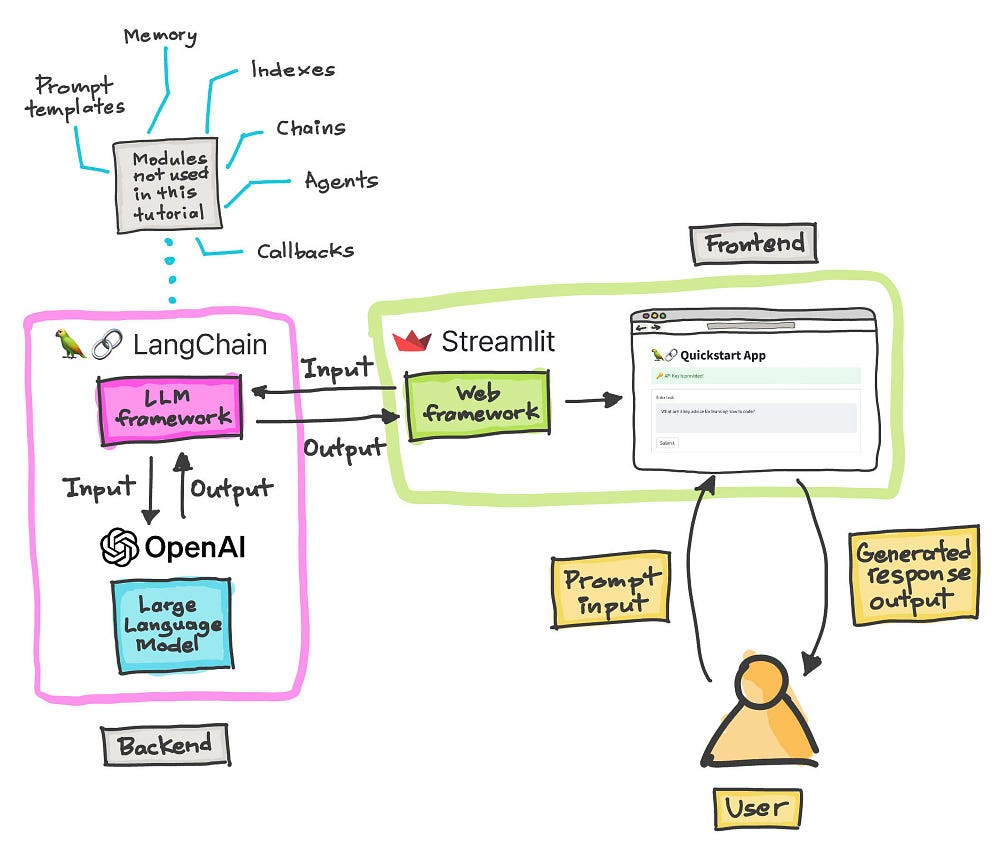
Langchain's models, prompts and parsers; Prompt templates, memories, chains, questions and answers, output evaluations, agents and more are with you with sample codes.
We can develop AI applications much faster using prompt engineering, but this approach requires the use of a lot of assembly code. Langchain, created by Harrison Chase, makes the process much easier.
Lanchain is an open-source framework for building LLM applications.
There are Python and Javascript(Typescript) packages.
It focuses on composition and modularity.
Key benefits: It has modular components, and there are common ways to combine components.
In this tutorial we will see the popular components of Lanchain, these are:
Models: 20+ LLM integrations, chat models, 10+ text embedding models. There are 3 types of models: LLMs, Conversation models and Text embedding models.
Some popular LangChain models:
AI21
Aleph Alpha
AnyScale
Aviary
Azure OpenAI
Banana
Beam
Bedrock
Cerebrum AI
Cohere
C Transformers
Databricks
DeepInfra
ForefrontAI
Google Cloud Platform Vertex AI PaLM
GooseAI
GPT4All
Huggingface Hub
HuggingFace pipeline
Huggingface TextGen Inference
Jsonformer
Lama-cpp
Manifest
Modal
MosaicML
NLP Cloud
OpenAI
OpenLM
Petals
PipelineAI
Predict Guard
PromptLayer OpenAI
ReLLM
Replicate
Runhouse
SageMaker Endpoint
StochasticAI
Writer
Prompts: Prompt templates, output parsers(retry/fix logic), sample selectors: 5+ applications. Indexes: 50+ document loaders, 10+ text splitters, 10+ vector repositories, 5+ retriever integrations/implementations Chains: Prompt + LLM + output parsing. They can be used as building blocks for larger chains. 20+ types of application-specific chains. Agents: 5+ Agent types, algorithms made for LLMs to use, 10+ implemented Agent Toolbox (agents equipped with a specific tool for a specific application).
Models, Prompts and Parsers
Models refer to language models, i.e. LLMs. Prompts represent inputs to language models. Parsers also represent the format of the output to be received. Google Collab link to the Models, Prompts and Parsers section: https://colab.research.google.com/drive/1PEEFEfG__BeG7vWH_afH1bMTMH-XlRIt?usp=sharing
Chat API: LangChain
Let's try making an API call to OpenAI using LangChain.
#!pip install python-dotenv
#!pip install openai
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
#!pip install --upgrade langchain
from langchain.chat_models import ChatOpenAI
# The randomness and creativity of ext created by an LLM
# to check, set temperature = 0.0.
chat = ChatOpenAI(temperature=0.0)
print(chat)
"""
>>> ChatOpenAI(verbose=False, callbacks=None, callback_manager=None, client=<class 'openai.api_resources.chat_completion.ChatCompletion'>, model_name='gpt-3.5-turbo', temperature=0.0, model_kwargs={} , openai_api_key=None, openai_api_base=None, openai_organization=None, request_timeout=None, max_retries=6, streaming=False, n=1, max_tokens=None)
"""
Prompt Template
We use a prompt template because prompts can be long and detailed, so we want to reuse good prompts whenever possible. Longchain also provides prompts for popular transactions.
template_string = """A \ with text {style} separated by triple backticks
turn it into style. text: ```{text}```
"""
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_template(template_string)
prompt_template.messages[0].prompt # Details about PrompTemplate()
"""
>>> PromptTemplate(input_variables=['style', 'text'], output_parser=None, partial_variables={}, template='Translate the text that is delimited by triple backticks into a style that is {style}. text: ` ``{text}```\n', template_format='f-string', validate_template=True)
"""
prompt_template.messages[0].prompt.input_variables # There are 2 types of input
# >>> ['style', 'text']
customer_style = """Istanbul Turkish in a calm and respectful tone."""
customer_email = """
Ugh, my blender lid flying off and splattering smoothies all over the kitchen walls\
I'm so angry! And worse, the guarantee covers the cost of cleaning my kitchen\
does not meet. I need your help right now, my servant!
"""
customer_messages = prompt_template.format_messages(
style=customer_style,
text=customer_email)
print(type(customer_messages)) # <class 'list'>
print(type(customer_messages[0])) # <class 'langchain.schema.HumanMessage'>
print(customer_messages[0])
# Calls LLM to translate into the style of the client message
customer_response = chat(customer_messages)
print(customer_response.content) # Istanbul dialect version of the text written in Black Sea dialect
service_reply = """Hello customer, before starting the blender, close the lid\
Since it's your fault for misusing your blender by forgetting to turn it off,\
The warranty does not cover the cleaning costs of your kitchen. Tough luck! See you later!
"""
service_style_pirate = """ With a polite Black Sea accent."""
service_messages = prompt_template.format_messages(
style=service_style_pirate,
text=service_reply)
print(service_messages[0].content)
service_response = chat(service_messages)
print(service_response.content) # Black Sea dialect version of the text written in Istanbul dialect
Output Parsers
Let's start by defining what we want the LLM output to look like:
{
"gift": False,
"delivery_days": 5,
"price_value": "Very affordable!"
}
customer_review = """\
This leaf blower is pretty amazing. It has four settings:\
candle blower, gentle breeze, windy city and hurricane. \
It arrived in two days, just in time for my wife's anniversary gift. \
I think my wife loved it so much she was speechless. \
So far I'm the only one using it and I use it every other day to clear leaves from our lawn. \
It is slightly more expensive than other leaf blowers. \
There are extra features but I think it's worth it. \
"""
review_template = """\
For the text below, extract the following information:
gift: Was the item purchased as a gift for someone else? \
If your answer is yes, it is True; otherwise, it is False or unknown.
delivery_days: How many days did the product arrive? \
If this information is not found, output -1.
price_value: Remove all phrases related to value or price,\
and output them as a comma-separated Python list.
Format the output as JSON with the following keys:
gift
delivery_days
price_value
text: {text}
"""
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_template(review_template)
print(prompt_template)
messages = prompt_template.format_messages(text=customer_review)
chat = ChatOpenAI(temperature=0.0)
response = chat(messages)
print(response.content)
"""
{
"gift":true,
"delivery_days": 2,
"price_value": ["It's a little pricier than other leaf blowers on the market, but I think it's worth it for the extra features."]
}
"""
type(response.content) # str
# If you run this line of code you will get an error because 'gift' is a dict\
# is not 'gift' is a string.
response.content.get('gift')
"""
AttributeError: 'str' object has no attribute 'get'
"""
Parse the LLM output string into a Python dictionary
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
gift_schema = ResponseSchema(name="gift",
description="Is the product as a gift for someone else\
Purchased? "If your answer is yes, it is True; otherwise, it is False or unknown.")
delivery_days_schema = ResponseSchema(name="delivery_days",
description="How many days did it take for the product to arrive?\
If this information is not found, output -1.")
price_value_schema = ResponseSchema(name="price_value",
description="Anything related to value or price\
sentences and output them as a comma-separated Python list.")
response_schemas = [gift_schema,
delivery_days_schema,
price_value_schema]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
review_template_2 = """ Extract the following information for the following text:
gift: Was the product purchased as a gift for someone else? \
If your answer is yes, it is True; otherwise, it is False or unknown.
delivery_days: How many days did it take for the product to arrive? If this information is not found, output -1 \
forehead.
price_value: Remove all phrases related to value or price and \
output them as a comma-separated Python list.
text: {text}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=review_template_2)
messages = prompt.format_messages(text=customer_review,
format_instructions=format_instructions)
print(messages[0].content)
response = chat(messages)
print(response.content)
output_dict = output_parser.parse(response.content)
print(output_dict)
type(output_dict) # dict
print(output_dict.get('delivery_days')) # '2'
Memory
Memory is a big deal when using LLMs to build applications like chatbots, and we'll see how to do this with stateless tokens.
Google Collab link of the memory section:
https://colab.research.google.com/drive/1wwYAZJtjcVgZosHgPSz1zelZV2Lrs-I5?usp=sharing
ConversationBufferMemory
It also adds previous conversations to new prompts and sends them. It consumes more tokens, its memory is stronger.
# Imports
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read from local .env file
import warnings
warnings.filterwarnings('ignore')
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True
)
conversation.predict(input="Hi, my name is Harrison.")
conversation.predict(input="What does 1+1 do?")
conversation.predict(input="What is my name?")
print(memory.buffer)
memory.load_memory_variables({})
memory = ConversationBufferMemory()
memory.save_context({"input": "Hi"},
{"output": "What's up?"})
print(memory.buffer)
memory.load_memory_variables({})
memory.save_context({"input": "Nothing, I just hang out."},
{"output": "Good."})
memory.load_memory_variables({})
ConversationTokenBufferMemory
Conversation token buffer memory maintains a buffer of recent interactions in memory and uses token length rather than several interactions to determine whether to purge interactions.
#!pip install tiktoken
from langchain.memory import ConversationTokenBufferMemory
memory.save_context({"input": "Nothing, I'm stuck like that"},
{"output": "Good"})
memory.save_context({"input": "What's on the show today?"},
{"output": f"{schedule}"})
memory.load_memory_variables({})
conversation = ConversationChain(
llm=llm,
memory = memory,
verbose=True
)
conversation.predict(input="What would be a good demo to show?")
memory.load_memory_variables({})
Extra Memory Types
Vector Data Memory: Keeps texts in the vector database and calls the most relevant text blocks.
Entity Memory: Keeps the details of some entities in mind using an LLM.
You can also use more than one memory together. For example, remembering individuals using Conversation Summary Memory and Entity Memory. You can also store the chat in a traditional database.
LangChain Chains
The chain is the basic building block of an LLM. Chains are a combination of LLMs and prompts. These building blocks can then be brought together to perform a larger series of operations.
Google Collab link of the LangChain Chains section:
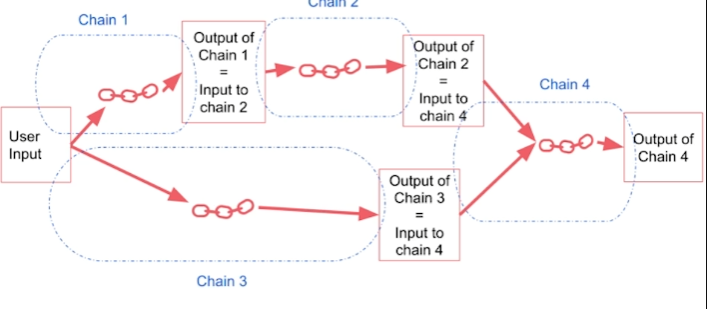
In SimpleSequentialChain, multiple chains are combined where the output of one chain is the input of the next chain.
SimpleSequentialChain[1]
There are two types of sequential chains: SimpleSequentialChain, which has a single input/output, and SequentialChain, which has multiple inputs/outputs.
from langchain.chains import SimpleSequentialChain
llm = ChatOpenAI(temperature=0.9)
# prompt template 1
first_prompt = ChatPromptTemplate.from_template(
"What name best describes a company that produces {product}?"
from langchain.chains import SequentialChain
llm = ChatOpenAI(temperature=0.9)
# 1. Prompt Template: translate to english
first_prompt = ChatPromptTemplate.from_template(
"Translate the following comment into Turkish:"
"\n\n{Review}"
)
# Chain 1: input = Review and output = Turkish_Review
chain_one = LLMChain(llm=llm, prompt=first_prompt,
output_key="Turkish_Review"
)
second_prompt = ChatPromptTemplate.from_template(
"Could you summarize the following review in 1 sentence:"
"\n\n{English_Review}"
)
# 2nd chain: input = English_Review and output = summary
chain_two = LLMChain(llm=llm, prompt=second_prompt,
output_key="summary"
)
# 3. prompt template: translate to Turkish
third_prompt = ChatPromptTemplate.from_template(
"What language is the following review in:\n\n{Review}"
)
# 3rd chain: input= Review and output= language
chain_three = LLMChain(llm=llm, prompt=third_prompt,
output_key="language"
)
# 3rd prompt template: followup_message
fourth_prompt = ChatPromptTemplate.from_template(
"Continued to the following summary in the specified language"
"write a reply:"
"\in\Summary: {summary}\in\Language: {language}"
)
# 4th chain: input = summary, language and output = followup_message
chain_four = LLMChain(llm=llm, prompt=fourth_prompt,
output_key="followup_message"
)
# overall_chain: input= Review
# and output = English_Review, summary, followup_message
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
input_variables=["Review"],
output_variables=["English_Review", "summary","followup_message"],
verbose=True
)
review = df.Review[5]
overall_chain(review)
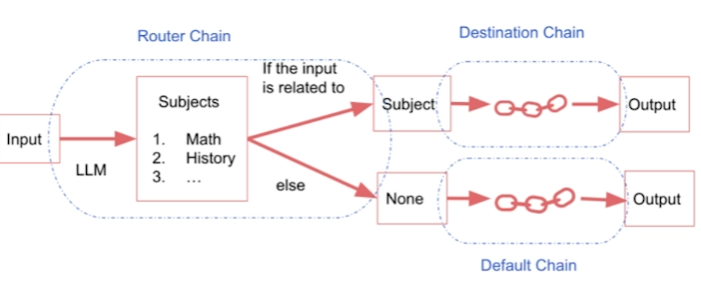
Router Chain
Router Chain[1]
physics_template = """You are a very smart physics professor.\
You are great at answering physics questions in a concise and easy to understand way. \
If you don't know the answer to a question, you accept that you don't know. \
Here's a question for you:
{input}"""
math_template = """You are a very good mathematician.\
You are great at answering math questions. \
You are very good because you can break down difficult problems into their component parts,\
can answer the component parts and then answer the broader question\
You can combine them for
Here's a question for you:
{input}"""
history_template = """You are a very good historian.\
About people, events, and contexts from various historical periods\
You have excellent knowledge and understanding. \
You have the ability to think, reflect, discuss, debate and evaluate the past. \
\begingroup Historical evidence to support your statements and judgments\
You respect his ability to use them.
Here's a question for you:
{input}"""
computerscience_template = """ You are a successful computer scientist.\
Creativity, collaboration, foresight, self-confidence,
have strong problem-solving abilities, understanding of theories and algorithms, and
You have a passion for excellent communication skills. \
You are great at answering coding questions. \
You're so good because you have mandatory steps that a machine can easily interpret\
you know how to solve a problem and with time complexity\
how to find a solution that has a good balance between space complexity
You know you will choose.
Here's a question for you:
{input}"""
prompt_infos = [
{
"name": "physics",
"description": "Good for answering physics questions",
"prompt_template": physics_template
},
{
"name": "mathematics",
"description": "Good for answering math questions",
"prompt_template": math_template
},
{
"name": "date",
"description": "Good for answering history questions",
"prompt_template": history_template
},
{
"name": "computer science",
"description": "Good for answering computer science questions",
"prompt_template": computerscience_template
}
]
MultiPromptChain (multiple prompt chain) is used when routing between multiple prompt templates.LLMRouterChain (LLM router chain) uses a language model to route between different subchains. This is where the description and name given above are used.RouterOutputParser (router output parser) parses the LLM output into a dictionary that can be used to determine which chain should be used and which input to that chain should be used.destination_chains: Chains called by the router chain. Every destination chain is an LLM chain.default_chain: This chain is used when the router cannot decide which chain to use.
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
from langchain.prompts import PromptTemplate
llm = ChatOpenAI(temperature=0)
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)
MULTI_PROMPT_ROUTER_TEMPLATE = """Raw text input into a language model\
When given, choose the model prompt that best fits the input. \
You will be given the names of the available prompts and a description of what the prompt is best suited for\
will be given. Also, the review is ultimately more important than the language model.
You can also use the original entry if you think it would lead to a good answer.
You can review.
<< FORMATTING >>
Return a markup code snippet with a JSON object formatted as follows:
```json
{{{{
"destination": string \name of the prompt to use or "DEFAULT"
"next_inputs": string\a potentially modified version of the original input
}}}}
```
REMEMBER: "destination" MUST be one of the candidate prompt names listed below OR can be "DEFAULT" if the entry is not suitable for any of the candidate prompts. \
REMEMBER: "next_inputs" can just be the original input if you don't think any changes are needed.
<< CANDIDATE PROMPTS >>
{destinations}
<< INPUT >>
{{input}}
<< OUTPUT (don't forget to add ```json)>>"""
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
chain = MultiPromptChain(router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain, verbose=True
)
chain.run("What is blackbody radiation?") # Automatically routed to the physics chain
chain.run("What is 2 + 2?") # Automatically redirected to the math chain
chain.run("Why does every cell in our body contain DNA?") # Automatically selects None and a general request is made to the language model
LangChain: Q&A on Documentation
Embedding models and vector stores, which are very popular and valuable for this type of task, will begin to be used.
Google Collab link of LangChainDocumentQA:
An example is a tool that allows you to query a product catalogue for items of interest.
#pip install --upgrade langchain
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
from langchain.chains import RetrievalQA # question and answer chain
from langchain.chat_models import ChatOpenAI # open ai chat model
from langchain.document_loaders import CSVLoader # to load csv file
from langchain.vectorstores import DocArrayInMemorySearch # vectorstore
from IPython.display import display, Markdown # to display information
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
from langchain.indexes import VectorstoreIndexCreator # This index makes it easy to create vector stores
#pip install docarray
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader]) # from_loaders returns a list of document loaders (in this example we send 1)
query ="Please list all your sun protection shirts in a discounted table\
list and summarize each.”
response = index.query(query)
display(Markdown(response)) # Shows a summary table at the end with sun protection shirt names and descriptions
loader = CSVLoader(file_path=file)
docs = loader.load()
docs[0]
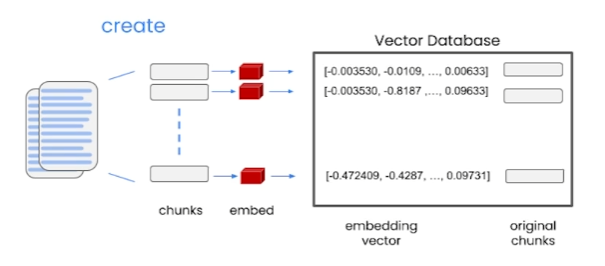
LLMs can only review a few thousand words at a time (in chunks), how do we get an LLM to do Q&A when we have so many documents? This is where embedding models and vector stores come into play.
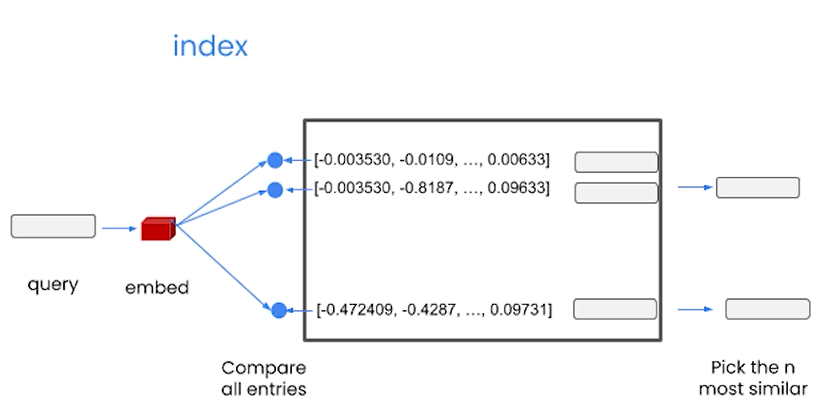
In the process called embedding, words are replaced with vectors (such as -0.003530) that will represent them and hold their semantic values.
Saving documents to vector databases [1] As can be seen in the image above, the document is divided into pieces called chunks, and the texts in those chunks are converted to vectors using the embedding method and saved in the vector database. Indexing[1] Thus, when a prompt query comes, that query is converted to embed and all embedded chunks are searched in the database and the most similar chunk is retrieved and returned. These returned values can now fit into the LLM context and thus we can get our output from the model.
from langchain.embeddings import OpenAIEmbeddings embeddings = OpenAIEmbeddings() embed = embeddings.embed_query("Hello, my name is Harrison") print(len(embed)) # There are 1536 embeds print(embed[:5]) # Each embed holds a vectordb = DocArrayInMemorySearch.from_documents( docs, # list of documents embeddings # Embedding object)query = "Please recommend a sun-blocking shirt"docs = db.similarity_search(query) # Searches the vector repository based on similarity so we can retrieve documents len(docs) # Number of documents docs[0] # First document
A retriever is a generic interface that can be supported by any method that receives a query that returns documents. There are other more complex or simple methods other than vector stores and embedding models.
retriever = db.as_retriever() llm = ChatOpenAI(temperature = 0.0) # We combine documents into a single piece of textqdocs = "".join([docs[i].page_content for i in range(len(docs))]) response = llm.call_as_llm(f"{qdocs} Question: Please use sun protectionlist your shirts in a table and summarize each one.") display(Markdown(response))
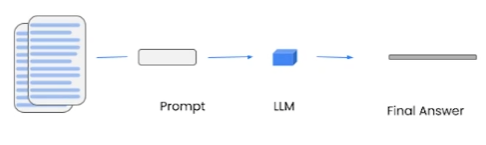
Filling method[1]
Stuffing Stuffing is a simple method where we fill the prompts with all the data in the form of context to send to the language model. Filling makes it possible to make a single call to the LLM. LLM has access to all data simultaneously but LLMs have a context length. For large or multiple documents this will not work as it will result in a prompt larger than the context. It is a method that is easy to understand, works well enough, and is inexpensive, but it does not always work well, for example, what if we want to do the same type of question answering on many chunks? Although the filling method is the most popular, there are 3 other methods we can use:
Map_reduce
map_reduce method [1]
It takes all the chunks and forwards them to LLM along with the question. It then takes the response and uses another language model call to summarize all the individual responses into a final response. This is a really powerful method because you can use it on any number of documents. Each of the chunks poses questions to the LLM separately, thus requiring many more calls, and addressing each document separately is not a highly desirable method. It is the preferred method for summarization.
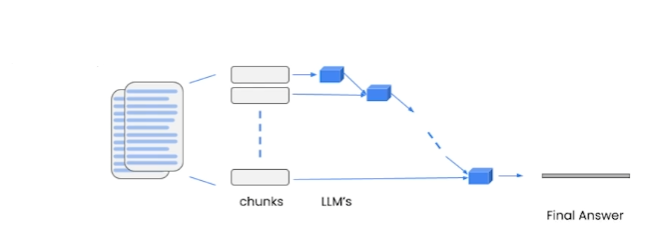
2. Refine
refine method [1]
It is another method used to look at many documents, it works by building on the answer received from the previous document. It is a convenient method to collect and combine answers from different documents over time. It is a method that generally results in longer answers being received in a slower time. It is slow because now the calls are independent and wait for them because they depend on the result of the previous call.
3. Map_rerank
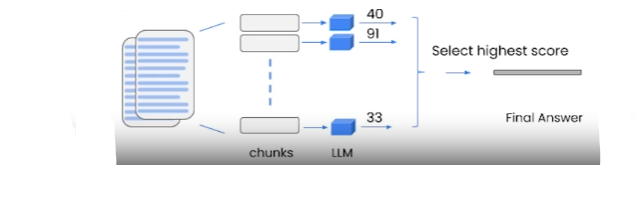
map_rerank[1]
This method, where all calls are independent, is much more experimental and interesting. A single call is made to LLM for each document and a score is requested. And the one with the highest score is chosen.
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever = retriever,
verbose=True
)
query = "Please buy all your sun protection shirts at a discount"
list them in a table and summarize each one.”
response = qa_stuff.run(query)
display(Markdown(response))
response = index.query(query, llm=llm)
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=embeddings,
).from_loaders([loader])
Evaluation
To increase the success of a project, the results of the changes to be made must be evaluated.
_ = load_dotenv(find_dotenv()) # read local .env file
Let's create our own question and answer application
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.vectorstores import DocArrayInMemorySearch
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
data = loader.load()
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
llm = ChatOpenAI(temperature = 0.0)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
verbose=True,
chain_type_kwargs = {
"document_separator": "<<<<>>>>>"
}
)
Comes with test data points
# Elements in documents
data[10]
data[11]
Hardcoded examples
# We have created question-and-answer pairs from these documents here, but LLM can also create them
examples = [
{
"query": "Does the Cozy Comfort Sweater Set have side pockets?",
"answer": "Yes"
},
{
"query": "Which collection is the Ultra-Lofty 850 Stretch Down Hooded Jacket from?",
"answer": "DownTek collection"
}
]
LLM created examples
from langchain.evaluation.qa import QAGenerateChain # create question and answer pair from documents
example_gen_chain = QAGenerateChain.from_llm(ChatOpenAI()) # Uses the ChatOpenAI model
new_examples = example_gen_chain.apply_and_parse(
[{"doc": t} for t in data[:5]]
)
print(new_examples[0])
# Output
{
'query': "How much does each pair of Women's Camping Oxford shoes weigh?",
'answer': "The approximate weight of each pair of Women's Camping Oxford shoes is 1 lb. 1 oz."
}
print(data[0])
# Output
Document(page_content=": 0\nname: Women's Camping Oxford Shoes\description: This ultra-comfortable lace-up Oxford boasts super-soft canvas, thick cushioning, and quality construction that feels worn-in from the first moment you wear it.\
\n\nSize and Fit: Order normal shoe size. \
For half sizes not offered, order up to the next full size. \
\n\nSpecifications: Approx. weight: 1 lb.1 oz. per couple. \
\n\nConstruction: Soft canvas material for a worn-in feel and look. \
Cleansport NXT® antimicrobial odor control comfortable EVA insole.\
Vintage hunting, fish and camping motif on the insole. \
Mid arch contour of the insole. \
EVA foam midsole for cushioning and support. \
Chain-tread inspired molded rubber outsole with modified chain tread pattern.\
Imported. \n\nDo you have questions? Please contact us for any questions you may have.",\
[chain/end] [1:chain:AgentExecutor > 5:chain:LLMCain] [3.39s] Exiting chain execution with output:
{
"text": "Customers are now sorted by last name followed by first name.\nLast Reply: [['Jen', 'Ayai'], ['Lang', 'Chain'], ['Harrison', 'Chase '], [ 'Elle', 'Elem'], ['Trans', 'Old'], ['Geoff', 'Fusion'], ['Dolly', 'Too']]"
}
[chain/end] [1:chain:AgentExecutor] [10.49s] Exiting chain execution with output:


 Filling method[1]
Filling method[1]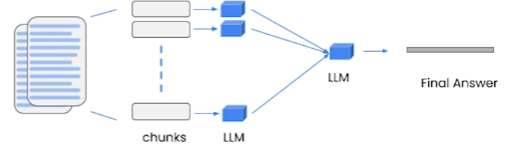










0 Comments